



本篇为:
-
面向人群:觉得LLM很多复杂的结构和层级,懂很多原理,但是不知道怎么结合到一起
-
本篇会很长,但是应该不会又臭又长
-
本篇可能像当头一棒,但是有可能:力度刚刚好,懵逼不伤脑。
-
逐行拆解LlaMa大模型的所有算子,架构,包括RMSNorm,ROPE,SwiGLU实现
-
本篇未采用huggingface的库,全程pytorch实现,没有任何预训练模型
-
起始点为一本《西游记》原文,终点为你自己练的大模型
-
准备好pytorch,即使没有显卡也没关系,主要是LLM原理的学习,而不是看完这个文章就可以造个新的大模型架构出来。
-
本篇会竭尽所能,全程用大白话去拆分原理。
引言
本文全部代码已分享至google_colab,有魔法的可以自行查看,代码逐行注释,不想看文章的,可直接去colab上跑一下,不需要GPU资源,直接最低配弄个CPU,可以运行(2024.10.17亲测):
https://colab.research.google.com/drive/1dqL8UN1UPNuEPCJzdNPbmin4vEveadgE?usp=sharing
如果有魔法的同学,打开上面的连接,看到的代码应该是本厮逐行注释过的,类似这样:

如果有兴趣继续的,那么请扶稳坐好,徒手搓个大模型系列–第一篇LlaMa,准备发车。
构造一个简单的文本生成模型
在构造LlaMa之前,我们先构造一个简单的seq2seq模型,然后逐步对原本的Seq2seq模型,增加LlaMa中的算子RMS、Rope、SwiGLU,直到完整构造LlaMa。
首先是一些功能函数的实现,虽然没什么难的,但是最好还是 过一遍,因为脑海里有数据的形状,在模型搭建的时候,知道输入进去的是什么样子的,对于理解深度神经网络有很大帮助。
导包
import torch
from torch import nn
from torch.nn import functional as F
import numpy as np
from matplotlib import pyplot as plt
import time
import pandas as pd
import urllib.request
这些库将帮助我们处理神经网络模型、数据操作、可视化、时间记录等功能。
创建配置字典
定义一个字典 MASTER_CONFIG 用于存储模型的配置参数:
MASTER_CONFIG = {
# 参数放这里
}
稍后我们将更新该配置字典以便使用。
下载《西游记》原文数据集
通过URL下载吴承恩版本的《西游记》原文数据集,并将其保存到本地文件 xiyouji.txt:
url = "https://raw.githubusercontent.com/mc112611/PI-ka-pi/main/xiyouji.txt"
file_name = "xiyouji.txt"
urllib.request.urlretrieve(url, file_name)
读取数据
从下载的文本文件中读取所有内容:
lines = open("xiyouji.txt", 'r').read()
lines = open("xiyouji.txt", 'r').read()
# 创建简易版词表(字符级)
vocab = sorted(list(set(lines)))
# 查看词表前n个字符
head_num=50
print('词表前{}个:'.format(head_num), vocab[:head_num])
print('词表大小:', len(vocab))
# 输出:
# 词表前50个: ['\n', ' ', '!', '"', '#', '*', ',', '.', '—', '‘', '’', '“', '”', '□', '、', '。', '《', '》', '一', '丁', '七', '万', '丈', '三', '上', '下', '不', '与', '丑', '专', '且', '丕', '世', '丘', '丙', '业', '丛', '东', '丝', '丞', '丢', '两', '严', '丧', '个', '丫', '中', '丰', '串', '临']
# 词表大小: 4325
字符编码与解码
将字符与数字相互映射,以便模型可以处理文本数据:
itos = {i: ch for i, ch in enumerate(vocab)} # index to string
stoi = {ch: i for i, ch in enumerate(vocab)} # string to index
接下来,我们创建一个简易的编码器和解码器,用于将文本转换为数字及将数字转换为文本:
# 编码器(青春版)
def encode(s):
return [stoi[ch] for ch in s]
# 解码器(青春版)
def decode(l):
return ''.join([itos[i] for i in l])
# 来试一下这个“高端”的编解码器
decode(encode("悟空"))
encode("悟空")
# 输出:
# [1318, 2691]
输出的两个数字代表着“悟”字和“空”字,在vocab词表中的编码,映射表的原理
因为是字符级的编码,不是BPE,或者其他格式的词表构建。此部分,可以替换为tiktoken或者其他的映射器,本文主要以理解原理为主,使用的方式越简单越容易理解。
# 对全文进行编码,并映射成为tensor
dataset = torch.tensor(encode(lines), dtype=torch.int16)
# 看一下形状,实际上就是多少个字符,一共65万个字符
print(dataset.shape)
print(dataset)
# 输出:
# torch.Size([658298])
# tensor([ 0, 4319, 1694, ..., 12, 0, 0], dtype=torch.int16)
上面这个代码块,我们将整本《西游记》全部编码,转换成tensor。本文一共有65万多个字符,转换成一维的张量。
接下来构建batch
# 构建batch
def get_batches(data, split, batch_size, context_window, config=MASTER_CONFIG):
# 切分训练集,验证集,测试集,比例为,训练80%,验证10%,测试10%
train = data[:int(0.8 * len(data))]
val = data[int(0.8 * len(data)): int(0.9 * len(data))]
test = data[int(0.9 * len(data)):]
# 将全部的训练数据作为batch,验证集,测试集也换个变量存储(单纯为了方便看)
batch_data = train
if split == 'val':
batch_data = val
if split == 'test':
batch_data = test
# 这里需要学习torch.randint,生成大小为batch_size,内部数值为随机整数的tensor。生成随机数数值域为[0,训练集字符数量-滑动窗口大小-1]之间的整数
# 详情可以参考官方文档,或者这个博客:https://blog.youkuaiyun.com/qq_41813454/article/details/136326473
ix = torch.randint(0, batch_data.size(0) - context_window - 1, (batch_size,))
# print('ix输出:')
# print(ix)
# 这里需要学习torch.stack,执行操作类似于python的zip关键字,只不过操作对象是tensor张量,指定任意维度的张量进行组合
# 详情参考官方文档,或者这个博客:https://blog.youkuaiyun.com/dongjinkun/article/details/132590205
# 这里x作为特征,y作为预测值,因为文本生成任务是根据前n个字符,去推理后面的1个字符,因此y的构造会使窗口在保持原大小的基础上向后移一位
# 通过滑动窗口,对batch_data中的训练数据,进行随机取样,相当于随机选择训练数据。
# 在原65万多个字符中,随机选取一个字符作为开始,并以这个开始点,向后选取滑动窗口个数的字符,作为训练数据,向后移一位就是其目标值。 因此ix的构造不能超出index。
x = torch.stack([batch_data[i:i+context_window] for i in ix]).long()
y = torch.stack([batch_data[i+1:i+context_window+1] for i in ix]).long()
# 返回特征值,目标值
return x, y
torch.randint 与 torch.stack 需要学习一下,这种的文章有很多。
重点可以放在这两行代码上:
x = torch.stack([batch_data[i:i+context_window] for i in ix]).long()
y = torch.stack([batch_data[i+1:i+context_window+1] for i in ix]).long()
以滑动窗口的形式对数据进行获取特征值与目标值,因为训练的时候,是根据前N个字符去预测后面的1个字符,因此,目标值y的滑动窗口在保持原本大小(长度)的前提下,向右移动一位。
# 根据上面构造的get_batchs()函数,更新参数字典。
MASTER_CONFIG.update({
'batch_size': 8, # 不解释
'context_window': 16, # 滑动窗口采样,设置采样大小
'vocab_size':4325 # 咱们的西游记数据集,一共包含4325个不重复的汉字,标点符号
})
构造一个字典,用于存储config参数,滑动窗口的值16,代表着采样时候将每条文本,分成多个长度为16的数据。vocab_size,上面有,代表着《西游记》原文所有字符去重后字符数量,也就是词表的大小。
为了方便理解,我们每构造一个函数,或者类,就单独运行一下,看看效果。如果堆了很多代码,即使执行,看到最终结果,应该也是懵的。
所以我们执行刚刚的get_ batches函数,看一下结果,为了方便观察,使用解码器(青春版)解一下码。
# 获取训练数据
xs, ys = get_batches(dataset, 'train', MASTER_CONFIG['batch_size'], MASTER_CONFIG['context_window'])
# 因为是随机生成的采样,我们可以看一下数据,其中每个采样数据,来自于原文随机的起始点,每个元组为一个(x,y),可以观察每个x和y的首位去直观感受一下滑动窗口执行的操作
decoded_samples = [(decode(xs[i].tolist()), decode(ys[i].tolist())) for i in range(len(xs))]
print(decoded_samples)
# 输出:
# [('姿娇且嫩’ !”那女子笑\n而悄答', '娇且嫩’ !”那女子笑\n而悄答道'), ('泼猢狲,打杀我也!”沙僧、八戒问', '猢狲,打杀我也!”沙僧、八戒问道'), ('人家,不惯骑马。”唐僧叫八戒驮着', '家,不惯骑马。”唐僧叫八戒驮着,'), ('著一幅“圯桥进履”的\n画儿。行者', '一幅“圯桥进履”的\n画儿。行者道'), ('从何来?这匹马,他在此久住,必知', '何来?这匹马,他在此久住,必知水'), ('声去,唿哨一声,寂然不见。那一国', '去,唿哨一声,寂然不见。那一国君'), ('刀轮剑砍怎伤怀!\n火烧雷打只如此', '轮剑砍怎伤怀!\n火烧雷打只如此,'), ('鲜。紫竹几竿鹦鹉歇,青松数簇鹧鸪', '。紫竹几竿鹦鹉歇,青松数簇鹧鸪\n')]
输出结果结果是列表,列表中的元素为多个元组,每个元组是特征数据与目标值。可以观察每个元组数据的开始和结束,来看滑动窗口的效果。
接下来构造一个评估函数
# 构造一个评估函数
@torch.no_grad()
def evaluate_loss(model, config=MASTER_CONFIG):
# 评估结果存储变量
out = {}
# 将模型置为评估模式
model.eval()
# 分别会在训练集和验证集里通过get_batchs()函数取评估数据
for split in ["train", "val"]:
losses = []
# 评估10个batch
for _ in range(10):
# 拿到特征值(输入数据),以及目标值(输出数据)
xb, yb = get_batches(dataset, split, config['batch_size'], config['context_window'])
# 把拿到的数据丢进模型,得到loss值
_, loss = model(xb, yb)
# 更新loss存储
losses.append(loss.item())
# 这里就是大家经常在控制台看到的 "train_loss" "valid_loss"由来
out[split] = np.mean(losses)
# 评估完了,别忘了把模型再置回训练状态,下一个epoch还要继续训练呢
model.train()
return out
到这里应该没有令人“眼前一黑”的操作。
这里加一个分割线,没什么特别的作用,就是觉得,如果上面的内容过了一遍,在jupyter或者colab跑了一下,没啥问题,那么可以继续。
说一些题外的,如果想抱着,代码拿来就能用,这篇文章可能没那么神(毕竟一个西游记原文,65万字的数据,还没有预训练模型,能练出个什么惊天大模型出来)。如果是想学习LLM,那么再提醒一次,请认真逐行看一下代码,否则会懵逼且伤脑。
在进行分析LlaMa架构分析之前,我们从最简单的文本生成模型开始创建,然后在最简单的文本生成模型的基础上,把LlaMa的RSM,Rope等一点点添加进去。为此我们先:
创建一个有毛病的模型架构 分析一下这个架构(其实也没什么分析的)
class StupidModel(nn.Module):
def __init__(self, config=MASTER_CONFIG):
super().__init__()
self.config = config
# embedding层,输入:词表大小,输出:维度大小
self.embedding = nn.Embedding(config['vocab_size'], config['d_model'])
# 创建线性层用于捕捉特征关系
# 下面突击检查:这玩意是不是隐藏层!线性层堆叠越多是不是越好!堆叠越多是不是更计算开销越大!
# LlaMa使用的激活函数是SwiGLU,目前在这个斯丢匹德模型架构里面先用Relu
self.linear = nn.Sequential(
nn.Linear(config['d_model'], config['d_model']),
nn.ReLU(),
nn.Linear(config['d_model'], config['vocab_size']),
)
# 这个命令可以背一下,或者复制粘贴到自己的学习笔记。 因为这行命令会直接帮你查看模型的参数量。
# 否则要么自己手算,要么就是听别人讲某某模型 7B 20B 108B 有了这个命令,你就能直接查看你创建的模型参数量多少
print("模型参数量:", sum([m.numel() for m in self.parameters()]))
我想,看注释就可以了吧,我们创建了一个有些stupid的模型,结构很简单:嵌入,线性变换,激活函数。唯一比较有意思的是,记住下面这个命令,以后可以用来查参数量。
print("模型参数量:", sum([m.numel() for m in self.parameters()]))
接下来,我们对上面那个斯丢匹得模型增加前向传播函数,也就是forward,换个名字,叫:“简单的破模型”吧。实际上broken代表着有问题。至于问题,马上解答。
class SimpleBrokenModel(nn.Module):
# init里的跟上面一样,没变化
def __init__(self, config=MASTER_CONFIG):
super().__init__()
self.config = config
self.embedding = nn.Embedding(config['vocab_size'], config['d_model'])
self.linear = nn.Sequential(
nn.Linear(config['d_model'], config['d_model']),
nn.ReLU(),
nn.Linear(config['d_model'], config['vocab_size']),
)
# 添加前向传播函数
def forward(self, idx, targets=None):
# 实例化embedding层,输入映射为id的数据,输出嵌入后的数据
x = self.embedding(idx)
# 线性层承接embedding层输出的数据
a = self.linear(x)
# 对线性层输出的数据在最后一个维度,做softmax,得到概率分布
logits = F.softmax(a, dim=-1)
# 如果有目标值(也就是我们前面的y),则计算通过交叉熵损失计算loss结果。给输出的概率矩阵变个形状,再给目标值变个形状。 统一一下输入输出,然后计算loss。其中最后一维代表着一条数据。
# 此处需要了解tensor.view()函数,带上几何空间想象力去想一下矩阵的形状。
if targets is not None:
loss = F.cross_entropy(logits.view(-1, self.config['vocab_size']), targets.view(-1))
return logits, loss
# 如果没有目标值,则只返回概率分布的结果
else:
return logits
# 查看参数量
print("模型参数量:", sum([m.numel() for m in self.parameters()]))
注释里不只有训练阶段,同时也有推理(评估)阶段,条件判断目标值是否存在,如果不存在,则只输出模型输出的结果,如果目标值存在,则还要返还loss值。
OS:注释之前加完了,感觉本篇文章甚至没啥写的了
# 这里我们设置这个模型为128维的embedding
MASTER_CONFIG.update({
'd_model': 128,
})
# 实例化模型,传参
model = SimpleBrokenModel(MASTER_CONFIG)
# 再看看参数量
print("咱们的模型这么多参数量:", sum([m.numel() for m in model.parameters()]))
# 于是乎,我们创建了一个1128307个参数的模型,上面参数想怎么改,自己改!电脑不会爆炸!
我们设置嵌入维度为128,LlaMa的嵌入维度是4096,我们弄个小一点的,毕竟在CPU上训练。得到一个112万参数量的模型。
下面,查看一下没训练之前,模型输出的结果,以及loss,模型输出的结果也就是数字,看loss更直观一些
# 获取训练的特征数据与目标数据
xs, ys = get_batches(dataset, 'train', MASTER_CONFIG['batch_size'], MASTER_CONFIG['context_window'])
# 扔进模型获取概率分布矩阵与loss
logits, loss = model(xs, ys)
loss
# 输出:
# tensor(8.3722, grad_fn=<NllLossBackward0>)
接下来,更新一下config超参数,实例化模型,以及设置优化器:
# 更新参数,训练伦次,batch_size,log日志打印步长
MASTER_CONFIG.update({
'epochs': 1000,
'log_interval': 10, # 每10个batch打印一次log
'batch_size': 32,
})
# 实例化模型
model = SimpleBrokenModel(MASTER_CONFIG)
# 创建一个Adam优化器,基础知识,
optimizer = torch.optim.Adam(
model.parameters(), # 优化器执行优化全部的模型参数
)
再构造一个训练函数,并启动训练:
# 构建训练函数
def train(model, optimizer, scheduler=None, config=MASTER_CONFIG, print_logs=False):
# loss存储
losses = []
# 训练时间记录开始时间
start_time = time.time()
# 循环训练指定epoch的轮数
for epoch in range(config['epochs']):
# 优化器要初始化啊,否则每次训练都是基于上一次训练结果进行优化,效果甚微
optimizer.zero_grad()
# 获取训练数据
xs, ys = get_batches(dataset, 'train', config['batch_size'], config['context_window'])
# 前向传播计算概率矩阵与loss
logits, loss = model(xs, targets=ys)
# 反向传播更新权重参数,更新学习率优化器
loss.backward()
optimizer.step()
# 如果提供学习率调度器,那么学习率会通过调度器进行修改,比如学习率周期性变化,或者梯度减小,增加,具体策略需要综合考虑进行设置,详情自行查询,关键字:lr_scheduler
if scheduler:
scheduler.step()
# 打印log
if epoch % config['log_interval'] == 0:
# 训练时间
batch_time = time.time() - start_time
# 执行评估函数,在训练集和验证集上计算loss
x = evaluate_loss(model)
# Store the validation loss
losses += [x]
# 打印进度日志
if print_logs:
print(f"Epoch {epoch} | val loss {x['val']:.3f} | Time {batch_time:.3f} | ETA in seconds {batch_time * (config['epochs'] - epoch)/config['log_interval'] :.3f}")
# 重置开始时间,用于计算下一轮的训练时间
start_time = time.time()
# 打印下一轮的学习率,如果使用了lr_scheduler
if scheduler:
print("lr: ", scheduler.get_lr())
# 上面所有epoch训练结束,打印最终的结果
print("Validation loss: ", losses[-1]['val'])
# 返还每一步loss值的列表,因为我们要画图,返还的是loss迭代的图像
return pd.DataFrame(losses).plot()
# 启动训练
train(model, optimizer)
输出的loss变化是这样的:

在1000个epoch的训练后,loss值从原来的8.3722,下降到了8.2150!
所以知道为什么这个模型架构叫“stupid”了吧,或者说“Broken“。
但是!
咱能修!
先分析一下原因:
上面那个训练框架存在一些问题。回到前向传播的代码,也就是forward()中。我们使用了 logits = F.softmax(a, dim=-1) 对线性层输出的结果做了一次概率分布的计算。而loss的计算选择了交叉熵损失, 目标值的词表映射结果是整数,而模型输出的logits是概率矩阵。
这俩玩意计算,相当于在国内的大街上,遇到外国人,跟人家说一句“hey man,what’s up”,老外说:“我会中文,嘎哈呀“,这么整也没问题,但是收敛起来就比较麻烦。
为了使loss计算更精确,我们需要将softmax去除。以保证交叉熵损失的计算效果更好。
# 拿掉softmax,logits改为获取最后一个线性层输出的结果,不进行softmax计算概率分布。
# 因此将这个架构取名为:不那么蠢的模型架构
class SimpleNotStupidModel(nn.Module):
def __init__(self, config=MASTER_CONFIG):
super().__init__()
self.config = config
self.embedding = nn.Embedding(config['vocab_size'], config['d_model'])
self.linear = nn.Sequential(
nn.Linear(config['d_model'], config['d_model']),
nn.ReLU(),
nn.Linear(config['d_model'], config['vocab_size']),
)
print("Model parameters:", sum([m.numel() for m in self.parameters()]))
def forward(self, idx, targets=None):
x = self.embedding(idx)
# 看这里,线性层直接输出结果,不转换为概率矩阵,只修改这里,其余不动。
logits = self.linear(x)
# print(logits.shape)
if targets is not None:
loss = F.cross_entropy(logits.view(-1, self.config['vocab_size']), targets.view(-1))
return logits, loss
else:
return logits
print("Model parameters:", sum([m.numel() for m in self.parameters()]))
再跑一下:
# 再来一次实例化各种功能,再启动一次训练
model = SimpleNotStupidModel(MASTER_CONFIG)
xs, ys = get_batches(dataset, 'train', MASTER_CONFIG['batch_size'], MASTER_CONFIG['context_window'])
logits, loss = model(xs, ys)
optimizer = torch.optim.Adam(model.parameters())
train(model, optimizer)
# loss开窍了,下降了很多

接下来构造一个推理函数:
并不准备传入数据,学习版,咱们就弄5个0,也就是词表中的换行符’\n’去推理。以换行符开始,循环推测后面20个字符
# 推理函数(输出结果就别纠结其效果了,权重都没保存,就是根据模型初始化生成的随机数组成的矩阵做的推理)
def generate(model, config=MASTER_CONFIG, max_new_tokens=20):
# 生成5个0,作为输入数据,5行一列,代表输入5个字符。 这个地方可以自行替换其他随机数测试。
idx = torch.zeros(5, 1).long()
print(idx[:, -config['context_window']:])
for _ in range(max_new_tokens):
# 因为推理的时候,依赖后面的n个token,所以滑动窗口要从后往前选择输入数据的倒数几个token,这个是超过字符数量会对输入进行截断,只选取最后几个token:idx[:, -config['context_window']:]
logits = model(idx[:, -config['context_window']:])
# print(logits.size())
# 得到模型输出的结果,进行解码,这里logits[:, -1, :]挺抽象的,实际上第一维度是输入的字符数,第二维度是时间步,第三维度是词表
# 即,对每一步的解码结果,取最后一个时间步的数据,作为输出的数据。解码的过程是第一次解码,输入5个token,第二次解码依赖的是原来5个token的最后4个,加上上一步解码生成的一个,也是5个token,如此循环。
last_time_step_logits = logits[:, -1, :]
# print('last_time_step_logits')
# print(last_time_step_logits.shape)
# 计算概率分布
p = F.softmax(last_time_step_logits, dim=-1)
# print('p_shape')
# print(p.shape)
# 根据概率分布计算下一个token,这里使用 torch.multinomial做的是随机采样
idx_next = torch.multinomial(p, num_samples=1)
# print('idx_next_shape')
# print(idx_next.shape)
# 将新的idx通过张量拼接写入到解码序列中
idx = torch.cat([idx, idx_next], dim=-1)
# 使用之前定义的解码函数,将ID转换为汉字,我们得到的5行21列的数据,来源于每一个输入字符作为开始位置,生成20个字符。 因为5个输入都是0,在词表中编号为0的数据是'\n'。
print(idx.shape)
return [decode(x) for x in idx.tolist()]
generate(model)
输出结果,不出所料,合乎情理,意料之中,挺差的:
['\n尽行者,咬道:“尽人了卖。”这人。”众僧',
'\n揪啊?怎么整猜脸。”那怪教沙僧护菩萨,貌',
'\n你看着国尖,不知请你。”妖王髯明。\n须行',
'\n老朗哥啊,遇货出便?路,径出聋送做者,似',
'\n那个急急的八戒、沙僧的树。菩萨莲削,身\n']
OK,到这里构造一个简单的Seq2seq模型,完毕,还是希望对上面的代码跑一下,理解一下,按行自行分析一下,如果有搞不清楚的,打印一下shape,看一下数据形状如何变换的。
如果上面全部搞清楚了,下面开始进入正题:在上面简单的模型基础上,逐步增加LlaMa的算子,并且每增加一个算子就看一下效果。
代码依旧是逐行注释,并且有些地方,咱也是为了学习分享,也记录了一些想法。
加个分割线,提醒一下:喝水,上厕所,活动腰和脊椎,做提肛运动防痔疮。自问一下:上面的内容是否已通透?马上就要考验高等数学学的是否扎实,是否准备好了?
正篇开始:
将LlaMa的算子加入到上面的简易模型架构中 主要包括:
1.RMS_Norm 2.RoPE 3.SwiGLU
RMSNorm快速了解
norm,做标准化,训练过程中的张量标准化操作,通过计算均值和方差,将样本进行归一化。在大学课程《概率与统计》我们学过,样本的均值代表样本的特征,而方差代表离散程度。
因此,通过计算,让数据变为均值为0,方差为1的数据。这样可以使数据服从标准的正态分布。
记得大学时候,老师讲这一段的时候,着重强调:“高斯分布,正态分布”,也可以叫自然分布,自然界的很多统计情况,几乎都满足高斯分布。两边向中心靠拢,超过中心的,随着逐渐增大,会越来越少,没超过中心的,距离中心越远,数量也越来越少。而分布的众数永远都是在中间。
啊~ 数学之美,但是也美不过高数老师(嘿嘿)。
使用均值和方差计算数据的标准差,这样既保留了数据的异常值,同时维持数据的异常结构,这样可以稳定梯度,让梯度变化更稳定,减少梯度消失或者爆炸的问题,因为维持了异常结构,也能减少过拟合问题,增强泛化能力。
RMSNorm出来之前,广泛使用的batch_normlize,针对批次数据做标准化。标准化的数值是一个batch作为一个样本总体,计算其均值与方差。
而后,又出现了layer_norm,其是针对每个token的特征向量做归一化处理(不知道特征向量,请看本人之前的rope文章。应该可以理解token和特征向量的关系。)依旧需要计算均值和方差。
RMSNorm和layer_norm的主要区别在于RMSNorm不需要同时计算均值和方差两个统计量,而只需要计算均方根这一个统计量。在模型表现效果几乎与layer_norm持平的前提下,节省7%-64%的计算量。
RMS_Norm计算公式: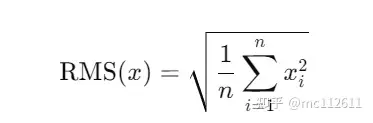
RMSNorm 的工作原理
计算 RMS:对于输入的特征(如神经元的输出),首先计算其 RMS 值。标准化:将每个特征的值除以其 RMS 值,从而调整数据的尺度,使其均值为 0,标准差为 1。
缩放和平移:在归一化后,RMSNorm 通常还会引入可学习的参数(缩放因子和偏置),以便模型能够学习适合特定任务的特征表示。
猜想:既然都平方根了,突然想起那个让程序员之神–约翰·卡马克直呼“卧槽”的快速平方根倒数算法了。当然,也有可能这么经典的数值计算方法已经被集成进了pytorch。
RMS基本介绍差不多了,下面开始实现RMSNorm模块:
class RMSNorm(nn.Module):
def __init__(self, layer_shape, eps=1e-8, bias=False):
super(RMSNorm, self).__init__()
# torch中register_parameter()功能为:向我们建立的网络module添加parameter
# 因此,我们需要对pytorch官方封装好的RMSNorm功能模块添加一个可以训练参数的层,命名为scale,并初始化为形状为layer_shape,所有值为1的张量矩阵。
self.register_parameter("scale", nn.Parameter(torch.ones(layer_shape)))
def forward(self, x):
# 计算Frobenius范数(球某个矩阵中所有元素的平方和再开方得到,该范数用来衡量矩阵的大小,详情请百度), RMS = 1/sqrt(N) * Frobenius
# 具体来说,torch.linalg.norm(x, dim=(1, 2))计算了x在第1和第2维度上的范数。然后,将结果乘以x[0].numel() ** -.5。x[0].numel()表示x第一个元素(即x的第一行)的元素个数,** -.5表示求平方根的倒数。
ff_rms = torch.linalg.norm(x, dim=(1,2)) * x[0].numel() ** -.5
# print(ff_rms.shape)
# 将ff_rms算子应用于输入的张量x,依据公式,做除法,因为输入向量x是三维的,因此需要对ff_rms进行升两维,也变成三维的张量。这样可以进行元素之间的计算。
raw = x / ff_rms.unsqueeze(-1).unsqueeze(-1)
# print(raw.shape)
# 返回缩放后归一化的张量
# print(self.scale[:x.shape[1], :].unsqueeze(0) * raw)
return self.scale[:x.shape[1], :].unsqueeze(0) * raw
需要注意的是,raw = x / ff_rms.unsqueeze(-1).unsqueeze(-1)这里的计算是针对张量矩阵中的每个元素计算,计算出了范数(实际上就是一个数值,不是矩阵),对原本输入数据的张量矩阵中,每一个元素除以这个归一化范数。因为RMSNorm已经继承在pytorch官方的nn.Moudle中,因此我们对其稍加修改。
接着:我们将这个RMS_Norm算子加入到上面的简易模型中,代码中很清楚,如何加入的:
class SimpleNotStupidModel_RMS(nn.Module):
def __init__(self, config=MASTER_CONFIG):
super().__init__()
self.config = config
self.embedding = nn.Embedding(config['vocab_size'], config['d_model'])
# 在这里,我们添加RMS层
self.rms = RMSNorm((config['context_window'], config['d_model']))
self.linear = nn.Sequential(
nn.Linear(config['d_model'], config['d_model']),
nn.ReLU(),
nn.Linear(config['d_model'], config['vocab_size']),
)
print("Model parameters:", sum([m.numel() for m in self.parameters()]))
def forward(self, idx, targets=None):
x = self.embedding(idx)
# 在这里,添加实例化后的RMS层,承接Embedding层输出的张量
x = self.rms(x)
logits = self.linear(x)
# print(logits.shape)
if targets is not None:
loss = F.cross_entropy(logits.view(-1, self.config['vocab_size']), targets.view(-1))
return logits, loss
else:
return logits
print("Model parameters:", sum([m.numel() for m in self.parameters()]))
我们添加了RMS_Norm之后,再看一下训练效果:
# 好啦,这样我们对原来的NotStupidModel添加了RMSNorm,现在执行一下看看
model = SimpleNotStupidModel_RMS(MASTER_CONFIG)
xs, ys = get_batches(dataset, 'train', MASTER_CONFIG['batch_size'], MASTER_CONFIG['context_window'])
logits, loss = model(xs, ys)
optimizer = torch.optim.Adam(model.parameters())
train(model, optimizer)
# 在同样的训练超参数设置上,加入了RMSNorm的训练速度明显加快
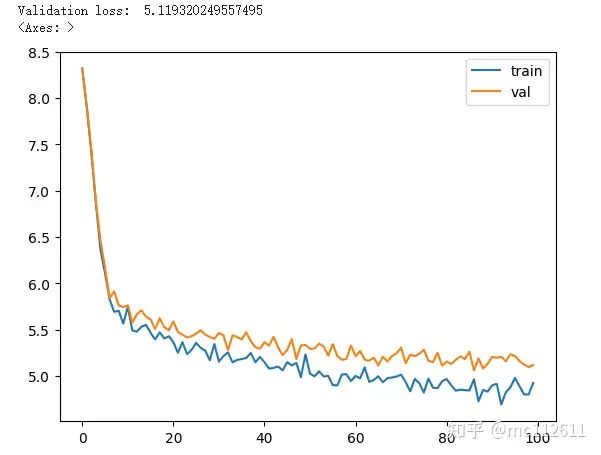 如果跑了一下代码,你会感受到计算速度会变快。
如果跑了一下代码,你会感受到计算速度会变快。
但是别急,下面两个算子会让计算速度更慢
将旋转位置编码(Rope)加入到模型中
RoPE很巧妙的将笛卡尔坐标系的计算,拉到极坐标空间计算。具体原理快速过一下可能说不完,有兴趣的可以看一下本厮的文章:
https://zhuanlan.zhihu.com/p/780744022
https://zhuanlan.zhihu.com/p/830878252
这里不再对原理进行分析,主要是代码实现。
还是建议先看完上面两个文章,代码部分就很好理解了
先定义一个函数,用于计算旋转位置编码:
def get_rotary_matrix(context_window, embedding_dim):
# 初始化一个0填充,形状为(context_window, embedding_dim, embedding_dim)的张量矩阵,其中context_window为token数量,后面两个embedding_dim组成正方形矩阵,与后面的attention计算对齐格式
R = torch.zeros((context_window, embedding_dim, embedding_dim), requires_grad=False)
# 遍历每一个位置的token
for position in range(context_window):
# 还记得我的上一篇文章中说的,对于特征,两两组合吗,因此需要循环的次数为embedding_dim除以2
for i in range(embedding_dim // 2):
# 设置θ值,采样频率,或者说旋转频率,旋转角都可以,除以embedding_dim防止梯度问题。
theta = 10000. ** (-2. * (i - 1) / embedding_dim)
# 根据欧拉公式,计算旋转的角度,分别有sin 和cos,将计算拉到复数空间,并将旋转角度应用在上面的0填充的矩阵
m_theta = position * theta
R[position, 2 * i, 2 * i] = np.cos(m_theta)
R[position, 2 * i, 2 * i + 1] = -np.sin(m_theta)
R[position, 2 * i + 1, 2 * i] = np.sin(m_theta)
R[position, 2 * i + 1, 2 * i + 1] = np.cos(m_theta)
# 得到的结果是旋转位置编码矩阵,到这里还没覆盖到attention
return R
因为旋转位置编码是结合了注意力机制的Q和K进行计算的,因此我们先实现一个单头的注意力机制的算子:
# 此为单头注意力机制
class RoPEMaskedAttentionHead(nn.Module):
def __init__(self, config):
super().__init__()
self.config = config
# 计算Q权重矩阵
self.w_q = nn.Linear(config['d_model'], config['d_model'], bias=False)
# 计算K权重矩阵
self.w_k = nn.Linear(config['d_model'], config['d_model'], bias=False)
# 计算V权重矩阵
self.w_v = nn.Linear(config['d_model'], config['d_model'], bias=False)
# 获得旋转位置编码矩阵,接下来会覆盖Q和K权重矩阵
self.R = get_rotary_matrix(config['context_window'], config['d_model'])
# 这里将上一个代码块中实现的创建旋转位置编码的功能函数原封不动的拿过来
def get_rotary_matrix(context_window, embedding_dim):
# 初始化一个0填充,形状为(context_window, embedding_dim, embedding_dim)的张量矩阵,其中context_window为token数量,后面两个embedding_dim组成正方形矩阵,与后面的attention计算对齐格式
R = torch.zeros((context_window, embedding_dim, embedding_dim), requires_grad=False)
# 遍历每一个位置的token
for position in range(context_window):
# 还记得我的上一篇文章中说的,对于特征,两两组合吗,因此需要循环的次数为embedding_dim除以2
for i in range(embedding_dim // 2):
# 设置θ值,采样频率,或者说旋转频率,旋转角都可以,除以embedding_dim防止梯度问题。
theta = 10000. ** (-2. * (i - 1) / embedding_dim)
# 根据欧拉公式,计算旋转的角度,分别有sin 和cos,将计算拉到复数空间,并将旋转角度应用在上面的0填充的矩阵
m_theta = position * theta
R[position, 2 * i, 2 * i] = np.cos(m_theta)
R[position, 2 * i, 2 * i + 1] = -np.sin(m_theta)
R[position, 2 * i + 1, 2 * i] = np.sin(m_theta)
R[position, 2 * i + 1, 2 * i + 1] = np.cos(m_theta)
# 得到的结果是旋转位置编码矩阵,到这里还没覆盖到attention
return R
def forward(self, x, return_attn_weights=False):
# 前向传播时,输入矩阵的形状为(batch, sequence length, dimension)
b, m, d = x.shape # batch size, sequence length, dimension
# 线性变换Q,K,V
q = self.w_q(x)
k = self.w_k(x)
v = self.w_v(x)
# 将旋转位置编码应用于Q和K,其中torch.bmm为矩阵做外积,transpose是转置,对Q矩阵转置,并与旋转位置编码做外积,再转置回原状,Q便应用了旋转位置编码。
# 考虑到输入文本的长度,因此对位置编码矩阵在第一维度做截断,因为长了也没用,与文本长度一样。
q_rotated = (torch.bmm(q.transpose(0, 1), self.R[:m])).transpose(0, 1)
# 同理对K也应用旋转位置编码进行覆盖
k_rotated = (torch.bmm(k.transpose(0, 1), self.R[:m])).transpose(0, 1)
# 对注意力机制点积进行等比例缩放,防止attention张量过长引发梯度爆炸,对应
activations = F.scaled_dot_product_attention(
q_rotated, k_rotated, v, dropout_p=0.1, is_causal=True
)
# 如果return_attn_weights参数置为1,则需要对attention进行掩码,因为在学习的时候,希望模型能依据前n个token去预测token,而不是开卷考试。
if return_attn_weights:
# 创建注意力掩码矩阵,其中torch.tril函数为:对于矩阵,取左下三角,剩下的都置0
attn_mask = torch.tril(torch.ones((m, m)), diagonal=0)
# 计算注意力机制的权重矩阵,并对最后一维度做归一化,(突击检查)为什么是最后一维!因为最后一维度是每个token的特征向量!
attn_weights = torch.bmm(q_rotated, k_rotated.transpose(1, 2)) / np.sqrt(d) + attn_mask
attn_weights = F.softmax(attn_weights, dim=-1)
return activations, attn_weights
return activations
单头注意力机制实现完毕,下面是多头的注意力机制:
# 单头注意力机制实现完毕,下面实现多头注意力机制
class RoPEMaskedMultiheadAttention(nn.Module):
def __init__(self, config):
super().__init__()
self.config = config
# 一个注意力机制头对象构建完毕了,多头的,首先多次创建这个对象。生成多个注意力机制头,塞到一个列表里。
self.heads = nn.ModuleList([
RoPEMaskedAttentionHead(config) for _ in range(config['n_heads'])
])
# 在模型结构上,创建一个线性层(隐藏层),用于线型输出注意力机制头输出的张量矩阵,寻找多头之间的特征,但是更主要的是,x经过多头计算后形状改变了,创建线性层,让张量矩阵变回原来输入的形状。
# 同时为了防止过拟合,使用随机神经元失活,比率0.1
# 线性层输入形状:注意力机制的头数,乘以矩阵的维度,关联到俺的上一篇文章,就是key矩阵,在多头之间共享权重,减少计算的思维。 输出为:模型的embedding维度数
self.linear = nn.Linear(config['n_heads'] * config['d_model'], config['d_model'])
self.dropout = nn.Dropout(0.1)
def forward(self, x):
# 输入矩阵形状x: (batch, sequence length, dimension)
# 每一个注意力机制头,都传入X进行计算。(这个地方开启并行执行会不会快一些,但是不知道pytorch是不是自动调用并行)
heads = [h(x) for h in self.heads]
# 输入张量x经过多个头计算attention(同时,attention是已经覆盖了RoPE的),重新拼接成新的矩阵,重新放入变量x。到这里你应该觉得:那矩阵形状不就变了吗
x = torch.cat(heads, dim=-1)
# 这不,线性层的作用来了
x = self.linear(x)
# 随机失活一下,防止过拟合
x = self.dropout(x)
return x
如果已经感觉,除了懵逼,已经伤脑了。还是先学习一下RoPE的原理,即使不是本厮的那两篇,也可以找一些能理解的文章,白话解释,甚至问chatgpt,任何方法,只要作者的讲述方式,和自己的脑电波频率对得上,能理解,就OK。
好啦,上面的功能已实现,让我们更新一下config超参数的字典,设定注意力机制头数,LlaMa是32个注意力机制头,我们创建8个:
MASTER_CONFIG.update({
'n_heads': 8,
})
接下来,我们更新我们的建议模型,之前更新了RMS_Norm,这次我们在那基础上,将融合了ROPE位置编码的多头注意力机制加入进去!
# 我们已经创建完了所需要的算子, 现在积木已创建完毕,将这些积木组合起来!!!!
class RopeModel(nn.Module):
def __init__(self, config):
super().__init__()
self.config = config
# Embedding层
self.embedding = nn.Embedding(config['vocab_size'], config['d_model'])
# RMSNorm层
self.rms = RMSNorm((config['context_window'], config['d_model']))
# 旋转位置编码器+注意力机制
self.rope_attention = RoPEMaskedMultiheadAttention(config)
# 线性层+激活函数变为非线性输出!
self.linear = nn.Sequential(
nn.Linear(config['d_model'], config['d_model']),
nn.ReLU(),
)
# 最终的输出,因为需要解码,因为输出的维度与词表大小统一!!!
self.last_linear = nn.Linear(config['d_model'], config['vocab_size'])
print("model params:", sum([m.numel() for m in self.parameters()]))
# 前向传播
def forward(self, idx, targets=None):
# embedding,不解释
x = self.embedding(idx)
# 归一化数值,不解释
x = self.rms(x)
# 相加,解释一下,因为attention是要覆盖到原矩阵的,想象两个形状一样的矩阵为两张纸,左手一张纸,右手一张纸,双手合十,啪!覆盖。 使用加算,就是将两个矩阵中的元素按位置相加!直接覆盖值!
x = x + self.rope_attention(x)
# 再归一化!
x = self.rms(x)
# 因为直接计算归一化的数值可能出现梯度问题,因此把归一化的值作为修正系数,再覆盖!
x = x + self.linear(x)
# 到这里,才是最终输出vocab数量的神经元输出!!!!!!
logits = self.last_linear(x)
# 训练阶段有目标值
if targets is not None:
loss = F.cross_entropy(logits.view(-1, self.config['vocab_size']), targets.view(-1))
return logits, loss
# 验证或者推理阶段,目标值y没有!只有结果,没有loss!
else:
return logits
老规矩,跑一下,看看效果!
# 再跑一下!
model = RopeModel(MASTER_CONFIG)
xs, ys = get_batches(dataset, 'train', MASTER_CONFIG['batch_size'], MASTER_CONFIG['context_window'])
logits, loss = model(xs, ys)
optimizer = torch.optim.Adam(model.parameters())
train(model, optimizer)
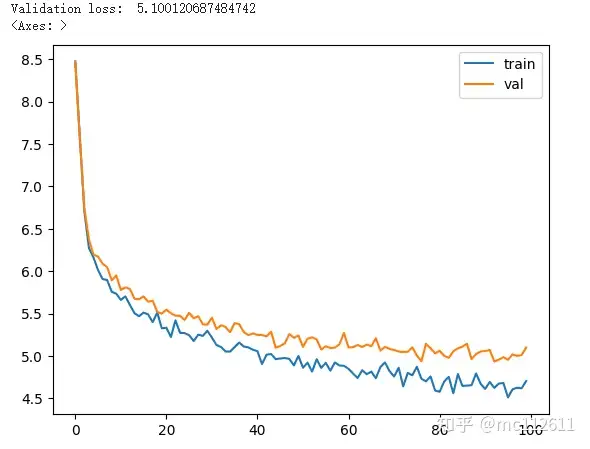 太惊人了,loss足足下降了0.01!
太惊人了,loss足足下降了0.01!
额。实际上就是attention没有做mask,虽然功能实现了,但是没有调用,布尔值设置的是false。
SwiGLU算子
将swish和glu结合起来。这两个激活函数单独拿出来都很强,结合起来。
这玩意挺玄学,说它不好吧,但是这玩意确实比relu这败家子保留更多语义特征参数,不至于某个权重突然到了小于0的区间,然后糊里糊涂的消失。说它好吧,它的计算量确实挺大。
swish用了sigmoid,GLU用了门控结构(门控结构思想,可以学习一下RNN,GRU,LSTM什么的)
由于SwiGLU部分,本厮也没深入研究过,因此以下是抄来的东西:
Swiglu 的工作原理
Swiglu 将 Swish 和 GLU 结合在一起,计算方式如下:
计算两个部分:
输入通过线性变换得到 a 和 b。
a 使用 Swish 激活,b 使用 Sigmoid 激活。
组合结果:
最终的输出由 a 和 b 的组合决定,形式为:
优势
灵活性:Swiglu 结合了非线性和门控机制,允许模型更灵活地捕捉复杂的模式。
性能:在某些任务上,Swiglu 已显示出比传统激活函数更好的表现,尤其是在处理复杂数据时。
下面实现一下:
class SwiGLU(nn.Module):
def __init__(self, size):
super().__init__()
# 定义一个门控的线性层,输入输出都是门控结构的尺寸
self.linear_gate = nn.Linear(size, size)
# 门控结构主干线性层
self.linear = nn.Linear(size, size)
# 初始化一个随机数作为beta系数
self.beta = torch.randn(1, requires_grad=True)
# nn.Parameter用于指定某一层参数为可学习的,即本来不能通过训练更改参数,现在变成了可以经过训练来更新的参数。
self.beta = nn.Parameter(torch.ones(1))
# 将随机数beta指定为一个名为beta的神经网络层
self.register_parameter("beta", self.beta)
def forward(self, x):
# Swish门控但愿的计算:(从括号里开始)对于原始输入的数据张量,经过线性变换乘以beta系数,再经过sigmoid变换为0-1之间的值,再乘以原数据经过门控线性变换。总的来说,线型输出经过非线性变换,再应用到线性变换的结果,元素按位置相乘,修正原本数据张量,就是这个门控结构做的事情。
swish_gate = self.linear_gate(x) * torch.sigmoid(self.beta * self.linear_gate(x))
# 将门控结构输出的值再按位乘以线型输出的原数据张量
# 为啥这么做,我不知道,但是论文复现的代码就是这样滴,有兴趣可以研究一下,我没研究过。
out = swish_gate * self.linear(x)
return out
再将刚刚定义好的swiglu算子添加到模型中,该模型我们之前添加过RMS、RopeAttention。
# 再将swiglu添加进上面的模型
class RopeModel(nn.Module):
def __init__(self, config):
super().__init__()
self.config = config
self.embedding = nn.Embedding(config['vocab_size'], config['d_model'])
self.rms = RMSNorm((config['context_window'], config['d_model']))
self.rope_attention = RoPEMaskedMultiheadAttention(config)
self.linear = nn.Sequential(
nn.Linear(config['d_model'], config['d_model']),
# 在这里,增加了SwiGLU层
SwiGLU(config['d_model']),
)
self.last_linear = nn.Linear(config['d_model'], config['vocab_size'])
print("model params:", sum([m.numel() for m in self.parameters()]))
def forward(self, idx, targets=None):
x = self.embedding(idx)
x = self.rms(x)
x = x + self.rope_attention(x)
x = self.rms(x)
x = x + self.linear(x)
logits = self.last_linear(x)
if targets is not None:
# Calculate cross-entropy loss if targets are provided
loss = F.cross_entropy(logits.view(-1, self.config['vocab_size']), targets.view(-1))
return logits, loss
else:
return logits
再跑一次!
# 一二三四!再来一次!
model = RopeModel(MASTER_CONFIG)
xs, ys = get_batches(dataset, 'train', MASTER_CONFIG['batch_size'], MASTER_CONFIG['context_window'])
logits, loss = model(xs, ys)
optimizer = torch.optim.Adam(model.parameters())
train(model, optimizer)
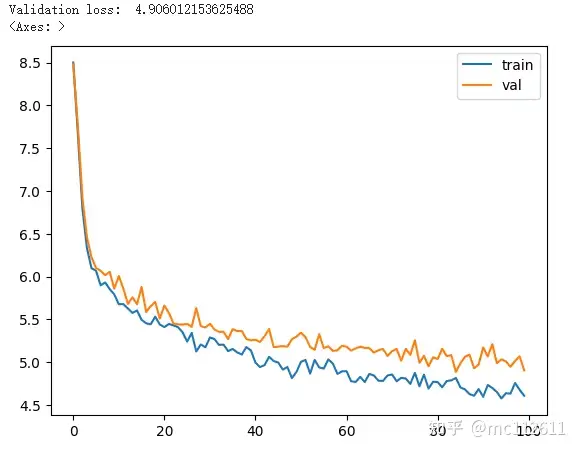 loss又惊人地下降了0.1。。。。。。。
loss又惊人地下降了0.1。。。。。。。
到这里,能添加的算子已经添加完毕,但是这只是一个llama的功能块,而llama是由多个功能块堆叠组成的。
加个分割线,该喝水的喝水,该活动脊椎的活动脊椎,建议消化一下。或者有精通SwiGLU的大佬也顺手出个教程~~~
如果可以的话,我们继续,接下来开始实现LlaMa
上面我们实现了LlaMa所需的算子,下面我们将其组合成为LlaMa的功能块,然后通过功能块的堆叠,组成LlaMa!
首先,设定一下功能块堆叠的层数:
# OK! 现在我们更新一下,隐藏层维度堆叠多少层,我们先来4层尝尝咸淡!!!!
MASTER_CONFIG.update({
'n_layers': 4,
})
然后,组成LlaMa的功能块,实际上就是融合了RMS、AttentionRoPE、SwiGLU激活函数的那个简易模型:
# 现在我们拥有了所有的算子,RMS,ROPE,SWIGLU,我们搭建我们的LlaMa! 首先实现LlaMa的功能块,然后堆叠。
# 功能没什么好讲的,如果仔细看到了这里,下面的每一行代码都难不住你。
class LlamaBlock(nn.Module):
def __init__(self, config):
super().__init__()
self.config = config
self.rms = RMSNorm((config['context_window'], config['d_model']))
self.attention = RoPEMaskedMultiheadAttention(config)
self.feedforward = nn.Sequential(
nn.Linear(config['d_model'], config['d_model']),
SwiGLU(config['d_model']),
)
def forward(self, x):
x = self.rms(x)
x = x + self.attention(x)
x = self.rms(x)
x = x + self.feedforward(x)
return x
看一下超参数字典
# 看一下我们的超参数字典
MASTER_CONFIG
# 输出:
#{'batch_size': 32,'context_window': 16, 'vocab_size': 4325,'d_model': 128,'epochs': 1000,'log_interval': 10,'n_heads': 8,'n_layers': 4}
测一下创建的功能块有没有问题:
# 用config字典,创建llama的功能块
block = LlamaBlock(MASTER_CONFIG)
# 生成一条随机数据,丢到这个llama功能块里,看一下是不是有bug
random_input = torch.randn(MASTER_CONFIG['batch_size'], MASTER_CONFIG['context_window'], MASTER_CONFIG['d_model'])
# 执行以下看看输出
output = block(random_input)
output.shape
组装LlaMa!
# 现在,我们组装LlaMa
from collections import OrderedDict
class Llama(nn.Module):
def __init__(self, config):
super().__init__()
self.config = config
# Embedding不解释
self.embeddings = nn.Embedding(config['vocab_size'], config['d_model'])
# 根据传入的堆叠层数,创建Llama功能块,注意OrderedDict为一种特殊类型的字典数据,保留字典写入的顺序,先插入的数据在前,后插入的数据在后。
# 这里,我们将llama的功能块堆叠4层
self.llama_blocks = nn.Sequential(
OrderedDict([(f"llama_{i}", LlamaBlock(config)) for i in range(config['n_layers'])])
)
# FFN层,包含:线性层、激活函数非线性变换、再用线性层输出最终解码数值。
self.ffn = nn.Sequential(
nn.Linear(config['d_model'], config['d_model']),
SwiGLU(config['d_model']),
nn.Linear(config['d_model'], config['vocab_size']),
)
# 看看咱们的大模型多少参数!
print("model params:", sum([m.numel() for m in self.parameters()]))
def forward(self, idx, targets=None):
# embedding嵌入
x = self.embeddings(idx)
# Llama模型计算
x = self.llama_blocks(x)
# FFN计算,得到logits
logits = self.ffn(x)
# 推理阶段没有目标值,只输出结果
if targets is None:
return logits
# 训练阶段,有目标值,需要输出结果,以及loss,用于反向传播更新权重!
else:
loss = F.cross_entropy(logits.view(-1, self.config['vocab_size']), targets.view(-1))
return logits, loss
训练LlaMa
# 开始训练咱们的Llama
llama = Llama(MASTER_CONFIG)
xs, ys = get_batches(dataset, 'train', MASTER_CONFIG['batch_size'], MASTER_CONFIG['context_window'])
logits, loss = llama(xs, ys)
optimizer = torch.optim.Adam(llama.parameters())
train(llama, optimizer)
推理一下:
# 再看一下推理效果(实际上也没什么效果-。-)
# 别忘了generate里面的输入数据是咱们弄的5个0,如果替换为encode之后的数也是可以的!组成列表,转换tensor,这个应该没问题的吧~
generated_text = generate(llama, MASTER_CONFIG, 500)[0]
print(generated_text)
推理的效果还是挺抽象的。感觉这文本推理像在逆练《新华字典》
当然,压根就没指望推理效果。所以之前就说了,本篇文章本身就不是开箱即用的,更适合中国宝宝学习大模型的文章。
玄兔春非朦意敖叶祥肤水沉岭日疼清赛。萝范燕旗顺清气瑜灵子庄。海藏御直熟列棱
尉火牙心正花,四位幸堂国如生岖。
辟两只道:千人人纵开羊堤进宝贝,乃人头破马前立阵,腰一年心;足如蜻丛杨馥新一耸飘木
膜须寺颜凤丹叶獐绦;桃送?
添牛福芽蟒菜丛体茵岁鹅宫丰,贼培莲豆龙东兵,九千
蓝穿鸣人罔二无团蛇陌盔,日滚听拿
万盏可帮迎。这壁楼去常路递淫栖询除朱,
渎制然便跑神果。因安群猴俱无发能放。今
钟无削乐都有僵拿,
能可怕饭息饯?”又说他怒道:“师父是两魔头请久得五条大神神净,全
天
前顷飞影多功。有四尺阳皆之挨初山,只然艰薤盘裳见大仙的清过武前,阻雨野轮板雕青应沫。
月海依乃射仙僧岸,更天淡海月蓬为白巅耀院,日花匾盏神润晴涧攒肾壑笠绵,恶非狐成聚三藏灵玉火花,玉西草奇竹主深。
德太影任涨青叶,十莲缨猪大圣天寸耀亮红、平
啸壮名空猿携绩蝶泾帝妖
满冻在我跑旧热力。唬得小子,
又五凤景晚。细抖见出前蓝泛卿西浪花白帘谷琶?一张酥罢旨
严胜锁来鬼处将他几个人师父!”喝道:“我们这厮伏:“可来,我伤得!不要说,有水洒悭迟。
待吾叫做,
俱的劈摆道者怕形,等我个妖精坐在鹤下,钩怪藏
手里罩放发,
天篮,掣身
测试集跑一下,甚至都忘了测试集了吧,忘了的回头看看get_batch那个函数:
# 下面是测试集跑一下
# 获取测试集的特征值和目标值
xs, ys = get_batches(dataset, 'test', MASTER_CONFIG['batch_size'], MASTER_CONFIG['context_window'])
# 丢进Llama获取loss
logits, loss = llama(xs, ys)
print(loss)
# 输出:
# tensor(4.7326, grad_fn=<NllLossBackward0>)
加点玩意,让其看上去更像回事,增加学习率调度器
# 还有优化的点哦,别忘了optimizer!以及学习率调度器!
# 调整参数再来一次!
MASTER_CONFIG.update({
"epochs": 1000
})
# 学习率优化器选择余弦退火
llama_with_cosine = Llama(MASTER_CONFIG)
llama_optimizer = torch.optim.Adam(
llama.parameters(),
betas=(.9, .95),
weight_decay=.1,
eps=1e-9,
lr=1e-3
)
# 余弦退火学习率优化器,让学习率逐渐减小,在结束时达到最低值。 详细可以百度,这种文章很多。
scheduler = torch.optim.lr_scheduler.CosineAnnealingLR(llama_optimizer, 300, eta_min=1e-5)
# 跑一下!
train(llama_with_cosine, llama_optimizer, scheduler=scheduler)
 跑2万个epoch就好了。毕竟所有参数都是随便弄的。。。。。
跑2万个epoch就好了。毕竟所有参数都是随便弄的。。。。。
好咯,剩下的没什么了,我们保存一下模型,然后再写个调用模型推理的函数。
参数路径自己改哦
保存模型:
# 保存模型权重
model_save_path = "./hf_model_save/pytorch_model.bin"
torch.save(llama_with_cosine.state_dict(), model_save_path)
# 生成一个config文件
import json
config_save_path = "./hf_model_save/config.json"
with open(config_save_path, 'w') as f:
json.dump(MASTER_CONFIG, f)
# 保存optimizer和学习率调度器的状态,方便继续微调
optimizer_save_path = "./hf_model_save/optimizer.pt"
torch.save(llama_optimizer.state_dict(), optimizer_save_path)
scheduler_save_path = "./hf_model_save/scheduler.pt"
torch.save(scheduler.state_dict(), scheduler_save_path)
加载模型:
# 接下来是加载模型
llama_with_cosine = Llama(MASTER_CONFIG)
# 加载模型权重
model_save_path = "./hf_model_save/pytorch_model.bin"
llama_with_cosine.load_state_dict(torch.load(model_save_path))
# 设置为评估模式
llama_with_cosine.eval()
# 加载优化器和学习率调度器,如果需要继续训练什么的。
llama_optimizer.load_state_dict(torch.load(optimizer_save_path))
scheduler.load_state_dict(torch.load(scheduler_save_path))
# 进行推理
output = generate(llama_with_cosine, MASTER_CONFIG)
print(output)
恭喜你,看到这里的你,炼丹成功!成功炼制出了自己的人工智障大模型!
好的,基本上就是这样,有了主干部分,剩下策略部分,或者增加其他算子,只要遵循结构,没什么不可以的。关注点可以放在:输入和输出 。矩阵的计算需要数学知识,区分是元素计算,还是向量矩阵整体的计算。
看到这里的你,如果对上面的内容理解差不多了,那么我相信,下面这个llama3源码中的model.py文件,对于你来说已经可以拿捏了。不得不感叹,meta团队是真的想让全世界看懂他们的代码,极具工整性与强解释性的代码,非常适合大模型学习。
https://github.com/meta-llama/llama3/blob/main/llama/model.py
留了个花活儿在colab的那个分享的ipynb脚本中,实际上也不是花活儿,就是把刚刚的人工智障,用fastAPI部署一个异步处理的服务。没兴趣的可以撤了。
如何学习大模型
现在社会上大模型越来越普及了,已经有很多人都想往这里面扎,但是却找不到适合的方法去学习。
作为一名资深码农,初入大模型时也吃了很多亏,踩了无数坑。现在我想把我的经验和知识分享给你们,帮助你们学习AI大模型,能够解决你们学习中的困难。
我已将重要的AI大模型资料包括市面上AI大模型各大白皮书、AGI大模型系统学习路线、AI大模型视频教程、实战学习,等录播视频免费分享出来,需要的小伙伴可以扫取。

一、AGI大模型系统学习路线
很多人学习大模型的时候没有方向,东学一点西学一点,像只无头苍蝇乱撞,我下面分享的这个学习路线希望能够帮助到你们学习AI大模型。

二、AI大模型视频教程

三、AI大模型各大学习书籍

四、AI大模型各大场景实战案例

五、结束语
学习AI大模型是当前科技发展的趋势,它不仅能够为我们提供更多的机会和挑战,还能够让我们更好地理解和应用人工智能技术。通过学习AI大模型,我们可以深入了解深度学习、神经网络等核心概念,并将其应用于自然语言处理、计算机视觉、语音识别等领域。同时,掌握AI大模型还能够为我们的职业发展增添竞争力,成为未来技术领域的领导者。
再者,学习AI大模型也能为我们自己创造更多的价值,提供更多的岗位以及副业创收,让自己的生活更上一层楼。
因此,学习AI大模型是一项有前景且值得投入的时间和精力的重要选择。


















 927
927

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









