



在本文中,我将介绍Ollama最近对Llama 3.2 Vision的支持更新,并分享Llama 3.2 Vision的实测结果。同时,我还将介绍一个视觉RAG系统,展示如何将Llama 3.2 Vision与该系统结合,完成基于视觉RAG检索的任务。
先介绍此次更新:
Ollama 现在正式支持 Llama 3.2 视觉模型(Llama 3.2 Vision)。
你看就像这样拖进去就可以识别图片了。

▲ 来源 | Prompt Engineering
你可以看到该模型有11B参数版和90B参数版。选择90B参数版时,文件大小约为55GB。当然还有一些量化的版本。
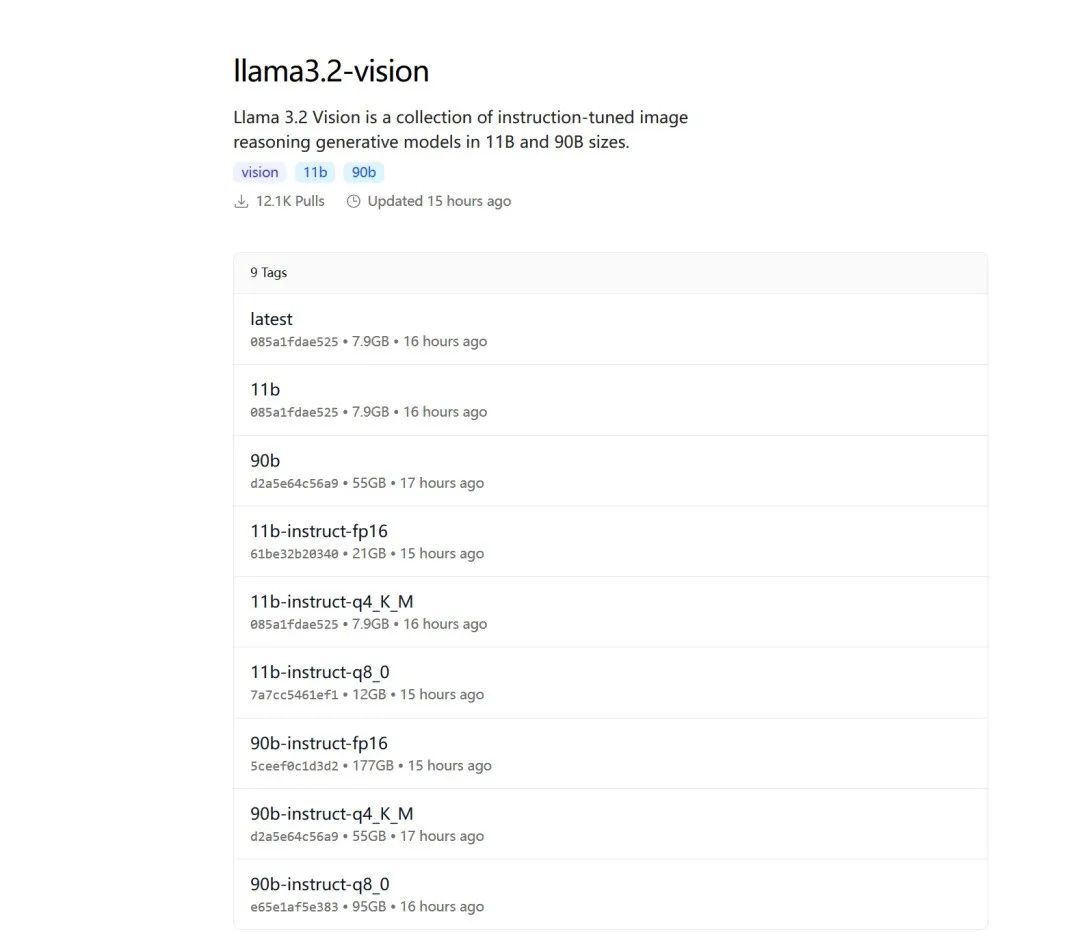
Llama 3.2 Vision 11B 至少需要 8GB VRAM,而 90B 型号至少需要 64 GB VRAM。
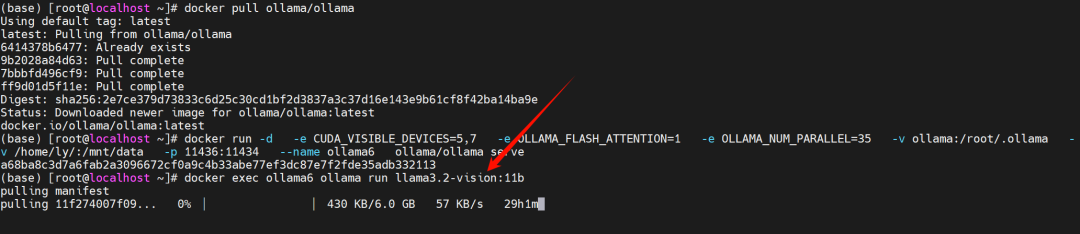
为了安装它,你需要更新一下ollama,这里以docker安装的ollama为例,没更新前拉取这个视觉模型不成功,我们需要删掉容器,再pull更新它。

更新完之后我们可以执行拉取操作

你可以使用ollama python库这样运行它的测试
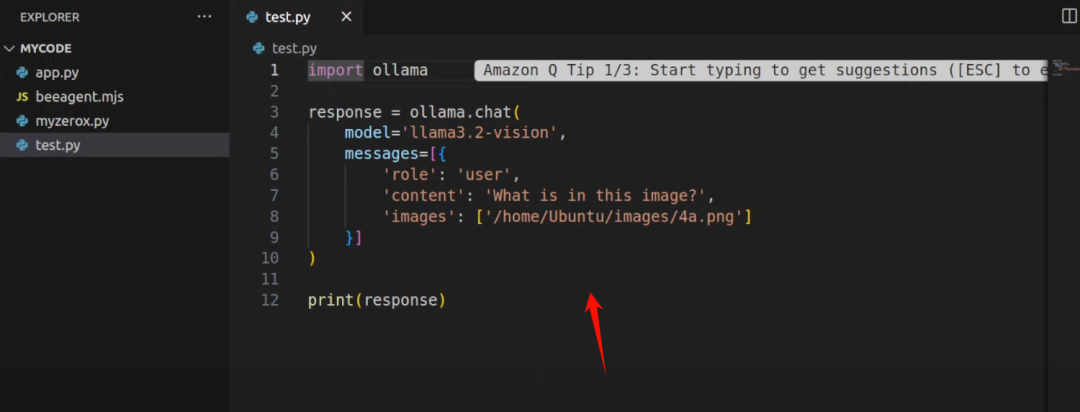
通过本地图像路径向模型提问“这张图片是什么”。

▲ 来源 | Fahd Mirza
模型返回了结果,描述图片中有“日落、袋鼠和一群鸟,太阳位于画面中央,但被云遮挡。” 这正是图片内容。
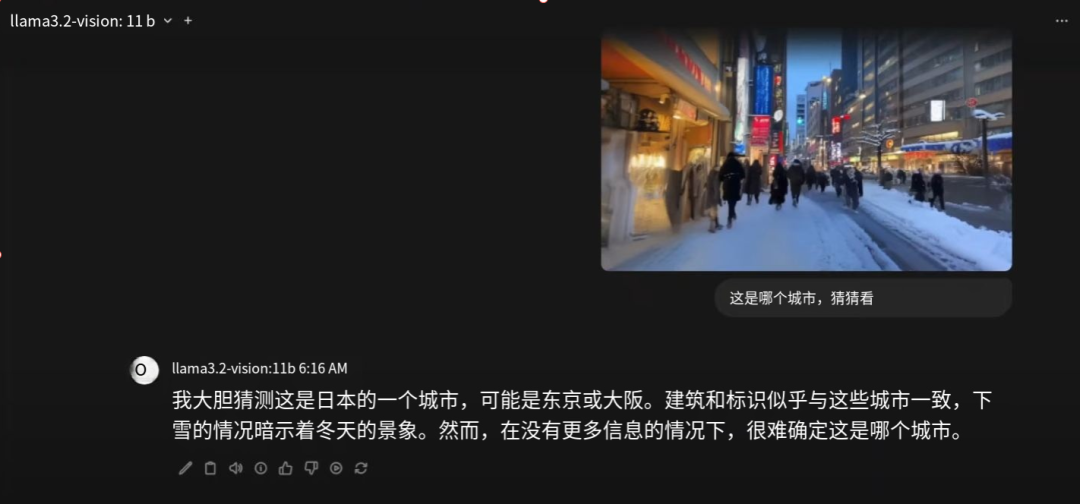
“ 这是什么城市?”,模型会给出答案:“我猜这是日本的城市,可能是东京或大阪。”
我们看看其他一些场景的情况:
手写内容识别
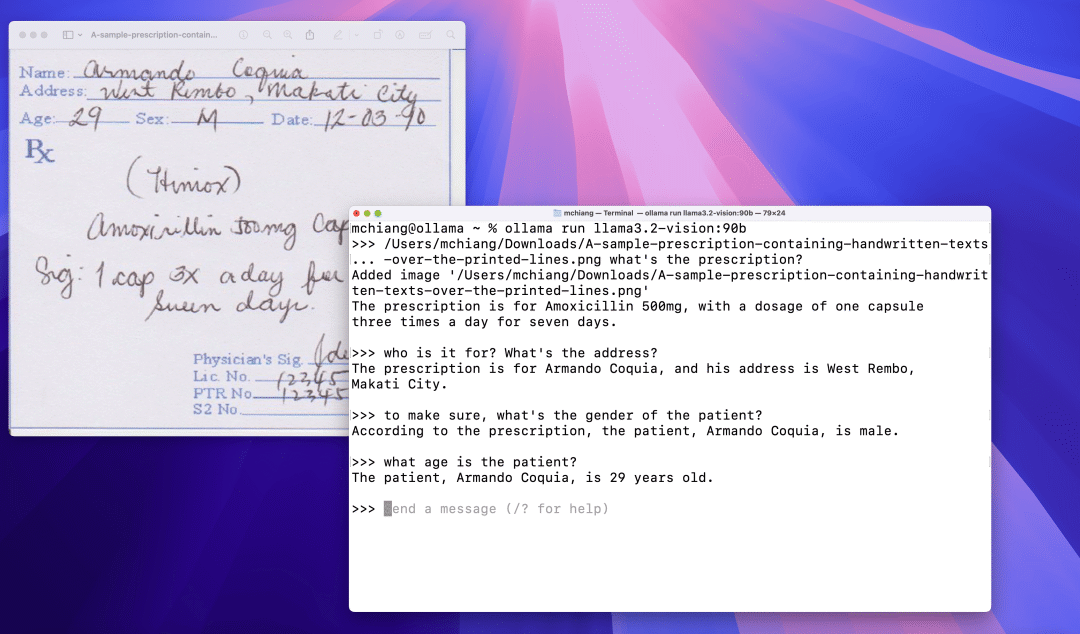
光学字符识别 (OCR)

图表和表格
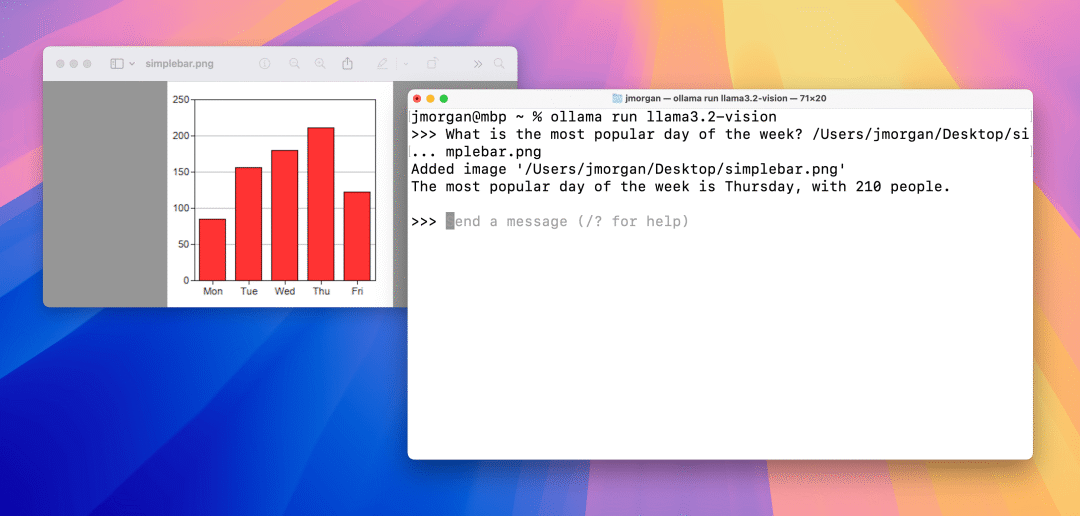
图片问答
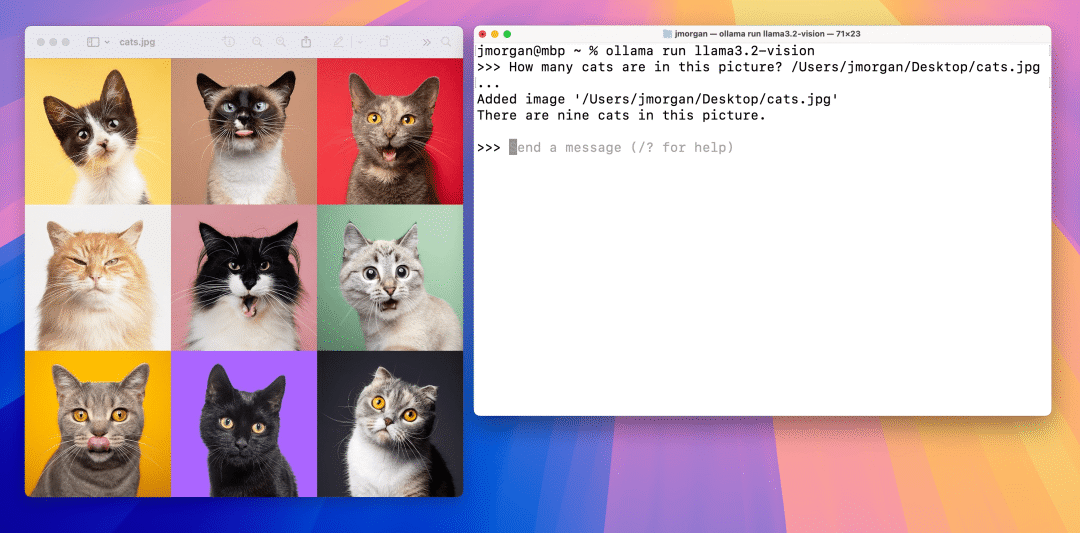
还是不错的。
下面我们进入正题 …
一个视觉RAG系统 + Llama 3.2 Vision
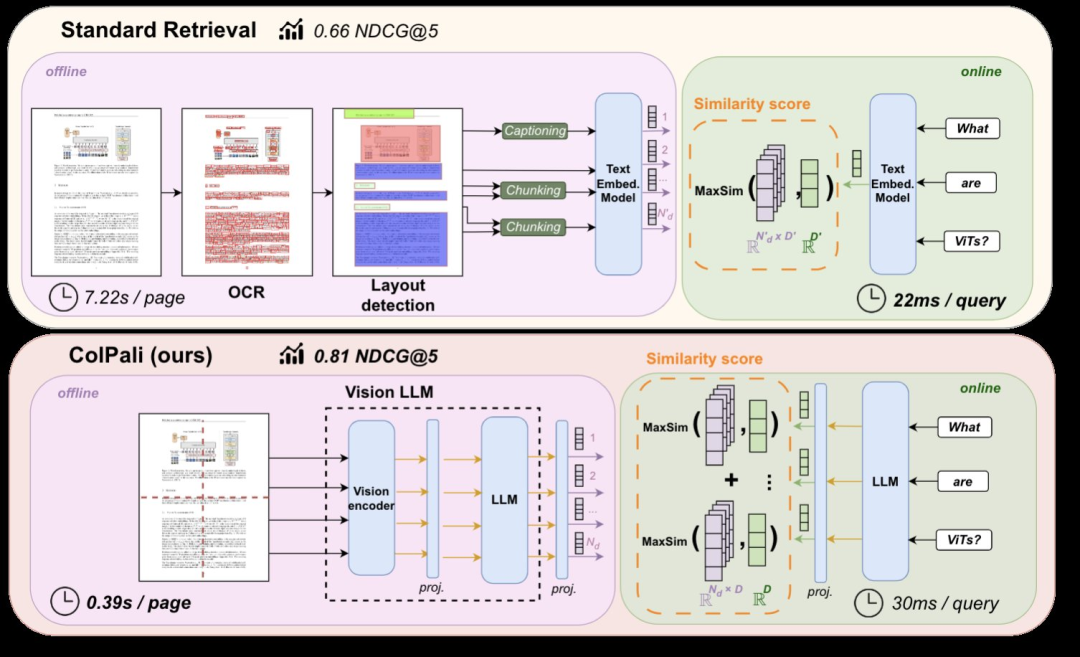
LocalGPT-Vision 是一个基于视觉的检索增强生成 (RAG) 系统,它可以让你与文档进行对话,使用Vision语言模型实现端到端的RAG系统。
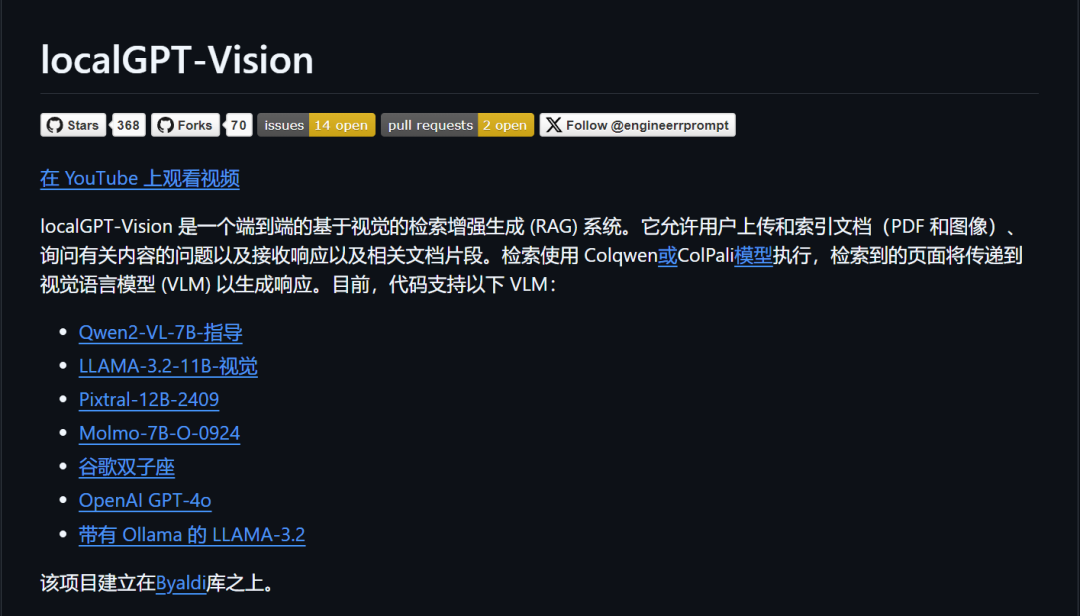
该项目使用Colqwen 或 ColPali模型进行基于视觉的页面信息检索,检索到的页面将传递到视觉语言模型 (VLM) 以生成响应。
安装这个项目:
首先,你需要克隆代码仓库或拉取最新的更改;然后你需要创建一个新的虚拟环境来使用conda;最后使用`pip install -r requirements.txt`安装所有需要的包。
为了启动主应用程序,我们将使用`python app.py`,这会启动我们的Flask服务器,并在该URL上运行。只需在浏览器中访问即可。
这是本地GPT Vision的主界面。如果你进入模型列表,将看到检索模型。我将选择Colqwen ,它是最适合的模型之一。
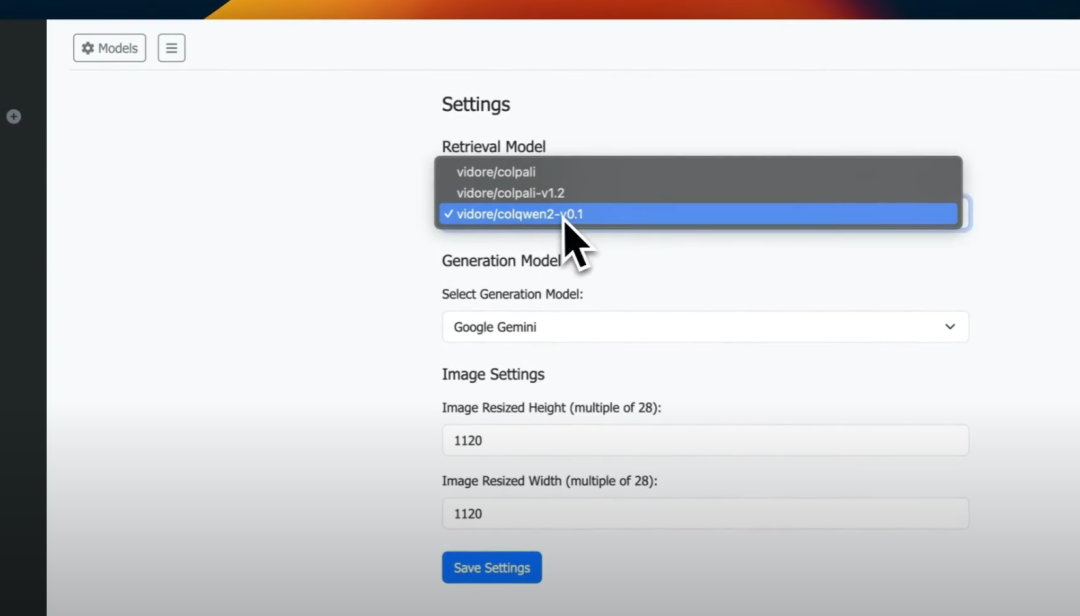
对于生成模型,你有多个选项,我将选择Ollama Llama Vision,

然后保存更改。
对于被RAG的对象,我们使用一篇名叫Light RAG论文,这是一种简单快速的检索增强生成方法,结合了知识库和基于密集向量的方式,特别适用于具有某种关系的实体。


开始:
点击上传文档按钮,选择相应的PDF文件,然后点击“开始索引”。

▲ 来源 | Prompt Engineering
此时,后台将使用Colqwen模型为PDF中的每一页创建多维向量表示,转换成图像并计算嵌入,所有这些操作都依赖于强大的poppler库。
如果遇到问题,请确保已安装poppler库,因为有些人在使用这个库时遇到过问题。索引完成后,点击“确定”,然后开始与刚才创建的知识库进行交互。
首先,我们用一个简单的提示开始:“这篇论文的标题是什么?”
你可以看到,论文的标题是《Light RAG: Simple and Fast Retrieval Augmented Generation》。
它与标题完全一致。
接下来我们可以看看它是否能够解释该图像的详细信息。
我问:“你能详细解释图1吗?”

图1 作为论文中的一个插图,讨论了索引过程和检索过程,并展示了提议的Light RAG框架的整体架构。该页面还包含了其他信息,特别是数学公式,它们本质上也解释了相同的概念。
原文是这样的

这里是这个视觉RAG系统回答的翻译版本:

生成的响应是:“该图像展示了Light RAG框架的全面概述,该框架旨在增强信息检索系统的性能和效率。”然后它讨论了不同的组件,包括数据索引器和数据检索器。
这些信息似乎来自图像本身或图像所在页面上的文本。描述可以做得更好一些,可能90B版本的模型会做得更好。
我在这里补充它回答后续的截图:

此外,这些视觉开源大模型往往也可以用于一些视频帧的分析的场景。
🌟希望这篇文章对你有帮助,感谢阅读!如果你喜欢这系列文章请以 点赞 / 分享 / 在看 的方式告诉我,以便我用来评估创作方向。
👽Submission:kristjahmez06@gmail.com
参考链接: [1] https://www.youtube.com/watch?v=aLdo_uGhrVQ [2] https://ollama.com/blog/llama3.2-vision
[3] https://www.youtube.com/watch?v=45LJT-bt500
如何学习大模型
现在社会上大模型越来越普及了,已经有很多人都想往这里面扎,但是却找不到适合的方法去学习。
作为一名资深码农,初入大模型时也吃了很多亏,踩了无数坑。现在我想把我的经验和知识分享给你们,帮助你们学习AI大模型,能够解决你们学习中的困难。
下面这些都是我当初辛苦整理和花钱购买的资料,现在我已将重要的AI大模型资料包括市面上AI大模型各大白皮书、AGI大模型系统学习路线、AI大模型视频教程、实战学习,等录播视频免费分享出来,需要的小伙伴可以扫取。

一、AGI大模型系统学习路线
很多人学习大模型的时候没有方向,东学一点西学一点,像只无头苍蝇乱撞,我下面分享的这个学习路线希望能够帮助到你们学习AI大模型。

二、AI大模型视频教程

三、AI大模型各大学习书籍

四、AI大模型各大场景实战案例

五、结束语
学习AI大模型是当前科技发展的趋势,它不仅能够为我们提供更多的机会和挑战,还能够让我们更好地理解和应用人工智能技术。通过学习AI大模型,我们可以深入了解深度学习、神经网络等核心概念,并将其应用于自然语言处理、计算机视觉、语音识别等领域。同时,掌握AI大模型还能够为我们的职业发展增添竞争力,成为未来技术领域的领导者。
再者,学习AI大模型也能为我们自己创造更多的价值,提供更多的岗位以及副业创收,让自己的生活更上一层楼。
因此,学习AI大模型是一项有前景且值得投入的时间和精力的重要选择。

















 4611
4611

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









