



由于大模型API价格已成白菜价,AI应用的开发将进入到RAG时代,而由于有了像阿里云百炼这样的一站式平台,普通开发者也能开发定制化的AI SaaS应用。
遥想2023年的3月份,GPT-4的32k上下文的API价格是平均每千字就超过0.5元,如果是加上历史对话,简单的一个问题都要好几块钱。由于价格太贵,很多应用的开发都只停留在简单的对话上,而现在各种大模型成本的降低,才让RAG应用开发成了可能。
比如现在通义千问GPT-4级主力模型Qwen-Long,API输入价格从0.02元/千tokens降至0.0005元/千tokens,这意味着,1块钱就可以买200万tokens,而且还支持1千万tokens长文本输入,大约相当于当前GPT-4价格的1/400,无论是企业部署定制化的客服服务,还是企业内部知识管理,还是其他专业、私有、实时等应用场景,哪怕是中小企业也能够承受这样的成本。
AI应用开发的三种模式
大模型存在很多已知问题,比如信息幻觉(Hallucination),它经常会生成看似合理但实际上不准确或不存在的信息;知识滞后,由于大模型都是基于静态的数据集训练,因此如果保证内容的时效性(尽管现在有了搜索,但是解决不了它训练时数据是静态的问题);内容不可追溯,由于它不能指出明确的信息来源,甚至还编造来源,影响了它回答的可信度;还有专业知识、私有知识欠缺,上下文有限等等问题。
为了解决大模型遇到的这些问题,提高模型的性能和输出质量,在AI应用开发时,大家往往会采取以下三种方式,即提示工程、微调和RAG:
1. 提示工程 (Prompt Engineering)
通过设计和优化输入提示来引导大语言模型生成更准确和有用的回答,比如通过提供详细和具体的问题描述,引导模型理解问题的意图;为模型提供必要的背景信息,使其能够更好地理解问题的背景和细节;通过给出一些示例回答,引导模型理解期望的回答形式和内容等;
 提示工程 (Prompt Engineering)
提示工程 (Prompt Engineering)
在ChatGPT刚发布不久,网上就流传各种各样的提示词,比如引导它怎么写出不错的文案,编写出优秀的代码,不过这些提示词都是基于大模型已有的数据和能力而言的。
2. 微调 (Fine-Tuning)
微调是一种通过在预训练模型的基础上,使用特定领域的数据进行再训练,从而使模型在特定任务或领域上表现更好的技术。使用特定领域的数据进行微调,使模型在该领域的表现更加出色。
 微调 (Fine-Tuning)
微调 (Fine-Tuning)
不过微调需要大量的高质量标注数据来进行训练。如果数据不足或者数据质量不高,模型的性能可能无法提升甚至下降。
3. 检索增强生成 (Retrieval-Augmented Generation, RAG)
检索增强生成(RAG)是一种结合检索和生成能力的方法,通过检索相关信息来增强生成模型的回答。在回答问题之前,模型会先检索与问题相关的背景信息和知识,将其整合到回答中,以提高准确性和信息量。这种方法能根据最新的检索结果动态更新和调整回答内容,从而在任务执行中提供最相关且重要的数据,提升模型的性能和准确性。在基于大语言模型(LLM)的问答系统中,RAG确保模型访问最新、可靠的事实,并允许用户查看来源以验证准确性,建立信任。
| 功能 | 提示工程 | 微调 | RAG |
|---|---|---|---|
| 所需技能水平 | 低:只需基本了解如何构建提示。 | 中高:需要掌握机器学习原理和模型架构的知识。 | 中等:需要了解机器学习和信息检索系统。 |
| 价格和资源 | 低:使用现有模型,计算成本最低。 | 高:需要大量的计算资源来进行训练。 | 中等:需要资源来支持检索系统和模型交互,但比微调少。 |
| 定制化 | 低:受限于模型的预训练知识和用户构建有效提示的能力。 | 高:可以针对特定领域或风格进行广泛定制。 | 中等:通过外部数据源进行定制,取决于数据源的质量和相关性。 |
| 数据需求 | 无:使用预训练模型,无需额外数据。 | 高:需要大量的相关数据集进行有效微调。 | 中等:需要访问相关的外部数据库或信息源。 |
| 更新频率 | 低:依赖于底层模型的再训练。 | 可变:取决于何时用新数据再训练模型。 | 高:可以整合最新的信息。 |
| 质量 | 可变:高度依赖于构建提示的技能。 | 高:针对特定数据集进行定制,提供更相关和准确的响应。 | 高:通过上下文相关的外部信息增强响应。 |
| 使用场景 | 一般查询、广泛主题、教育用途。 | 专业应用、行业特定需求、定制化任务。 | 需要最新信息的情况,以及涉及上下文的复杂查询。 |
| 实施难易度 | 高:使用现有工具和接口,实施简单。 | 低:需要深入的设置和训练过程。 | 中等:涉及将语言模型与检索系统集成。 |
尽管RAG好处很多,但是即使是专业的程序员在面对信息检索、Embedding、向量数据库、搜索数据库、知识库管理、模型管理等时,也会面露难色,不过有了像阿里云百炼这样的一站式大模型应用开发平台,即便你毫无技术基础,也能在几分钟内搭建专属的RAG应用。
三分钟内搭建专属RAG应用
第1步:导入专有、私有、动态的数据
通过导入数据,可以把1000页以内的PDF、Word等文档直接上传到数据管理中心,阿里云文档智能解析服务会自动解析文档,抽取文档内容、层级结构等信息。比如我直接导入了一本《孙子兵法》的PDF文档。
 导入数据,支持PDF等常用文档,百炼自会提炼
导入数据,支持PDF等常用文档,百炼自会提炼
第2步:将导入的数据创建成知识库
这一步如果是你自己用代码的方式开发,则需要你掌握langchain、embedding模型、向量数据库(比如milvus、Pinecone)、开源的搜索数据库(如Meilisearch、Elasticsearch、Lucene)等知识,会非常复杂,但是使用百炼平台,不需要你有技术基础,只需要按照步骤点几下即可。
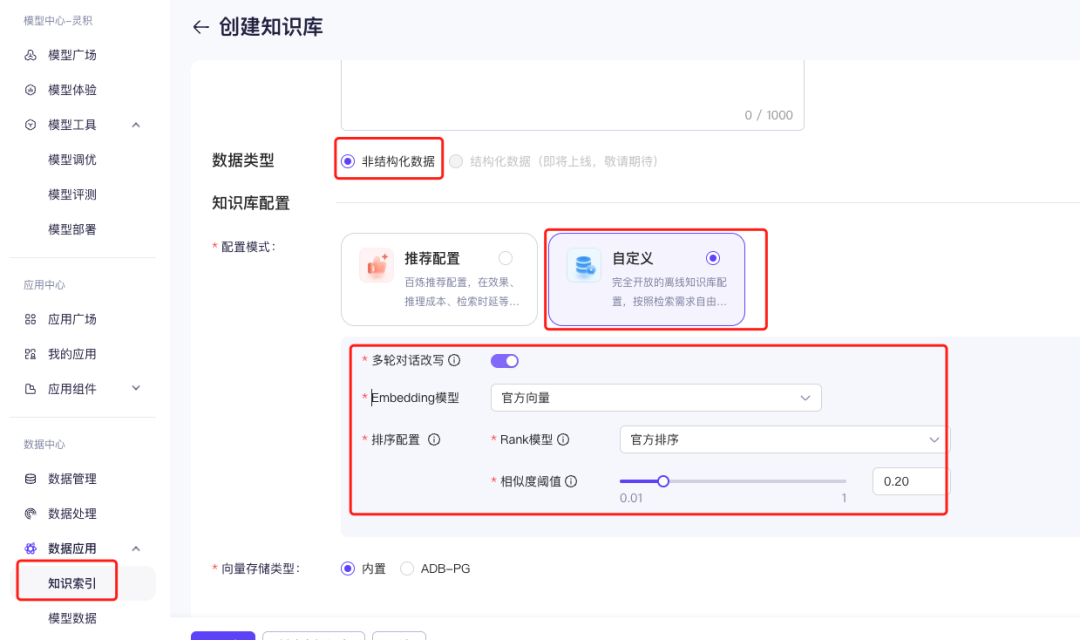 复杂的技术概念,只用可视化简单的操作即可完成
复杂的技术概念,只用可视化简单的操作即可完成
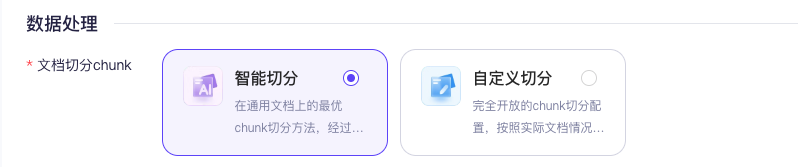 智能切分一步到位,无需调用langchain等
智能切分一步到位,无需调用langchain等
第3步:创建并发布RAG应用
接下来我们就可以直接创建并发布自己的RAG大模型了,选择大模型时,推荐通义千问-Max,输入prompt提示词时,需要加上一下变量${documents} 即可,比如:

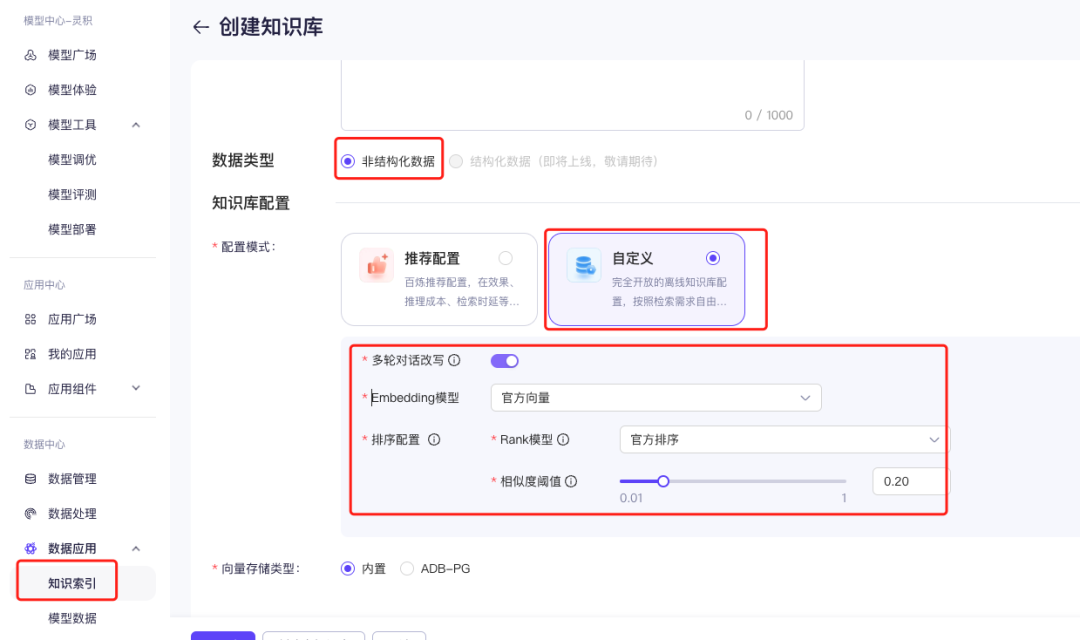 知识检索增强支持多个文档,自带Elasticsearch
知识检索增强支持多个文档,自带Elasticsearch
同时,要勾选知识检索增强,并选中之前创建好的知识库,以及回答来源(如果你希望让RAG回答问题都指出来源),然后点击保存并发布即可,到这里我们的RAG应用就已经创建好了。
第4步:调用RAG应用
我们可以直接在百炼控制台,像聊天一样来调用已经发布的应用,不过这个只是用来测试,比如我直接向它提问:“这本书有几个章节”,它不仅会围绕着我上传的《孙子兵法》来回答问题,而且还明确给出具体的出处,再也不会在它不懂的时候“胡说八道”了。

知识检索增强支持多个文档,自带Elasticsearch
就这么一个简单的问题,由于集成了资料,它的输入token是2562个,输出是107个,这在以前影响RAG流行最大的因素就是token太贵,而现在通义千问基本将API的调用打成了白菜价格,即便是在知识库里存放几百万字,RAG应用的对外用户服务的成本也在可控之内了。
而要让你的应用被广大用户使用,则需要懂一点编程知识,比如你可以使用阿里云的FC云函数计算来托管你的应用,也可以将应用集成到一些聊天应用里(比如集成到一些Chat Next Web之类的UI里,不过需要对UI的调用代码进行一点改造)。

用FC云函数即可调用,代码可以转换为多种语言
如何学习大模型
现在社会上大模型越来越普及了,已经有很多人都想往这里面扎,但是却找不到适合的方法去学习。
作为一名资深码农,初入大模型时也吃了很多亏,踩了无数坑。现在我想把我的经验和知识分享给你们,帮助你们学习AI大模型,能够解决你们学习中的困难。
下面这些都是我当初辛苦整理和花钱购买的资料,现在我已将重要的AI大模型资料包括市面上AI大模型各大白皮书、AGI大模型系统学习路线、AI大模型视频教程、实战学习,等录播视频免费分享出来,需要的小伙伴可以扫取。

一、AGI大模型系统学习路线
很多人学习大模型的时候没有方向,东学一点西学一点,像只无头苍蝇乱撞,我下面分享的这个学习路线希望能够帮助到你们学习AI大模型。

二、AI大模型视频教程

三、AI大模型各大学习书籍

四、AI大模型各大场景实战案例

五、结束语
学习AI大模型是当前科技发展的趋势,它不仅能够为我们提供更多的机会和挑战,还能够让我们更好地理解和应用人工智能技术。通过学习AI大模型,我们可以深入了解深度学习、神经网络等核心概念,并将其应用于自然语言处理、计算机视觉、语音识别等领域。同时,掌握AI大模型还能够为我们的职业发展增添竞争力,成为未来技术领域的领导者。
再者,学习AI大模型也能为我们自己创造更多的价值,提供更多的岗位以及副业创收,让自己的生活更上一层楼。
因此,学习AI大模型是一项有前景且值得投入的时间和精力的重要选择。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









