



在过去的一段时间,我们在公众号里一起学习了 RAG的搭建、向量数据库的选型、甚至是 Rerank(重排)模型的使用。
但最近,很多做 政务、金融、医疗 等垂直领域的朋友在后台私信我同一个痛点:
“云枢,我的 RAG 系统搭好了,Prompt 也写出花儿了,上了 Rerank,但效果还是差点意思。
用户问‘人才购房补贴’,它搜出来全是‘人才公寓管理’或者‘购房落户政策’。关键词都沾边,但意思完全不对!大模型拿不到对的参考资料,只能在那一本正经地胡说八道。”
这就像你问路“去火车站怎么走”,它告诉你“火车站的炒面很好吃”。它懂了,但没完全懂。
问题出在哪?Embedding 模型(向量化模型)不懂你的“行业黑话”。
今天,不教大家怎么“调 Prompt”,我们来点硬核的——手把手教你微调一个专属的 Embedding 模型,从根源上解决“搜不准”的问题!
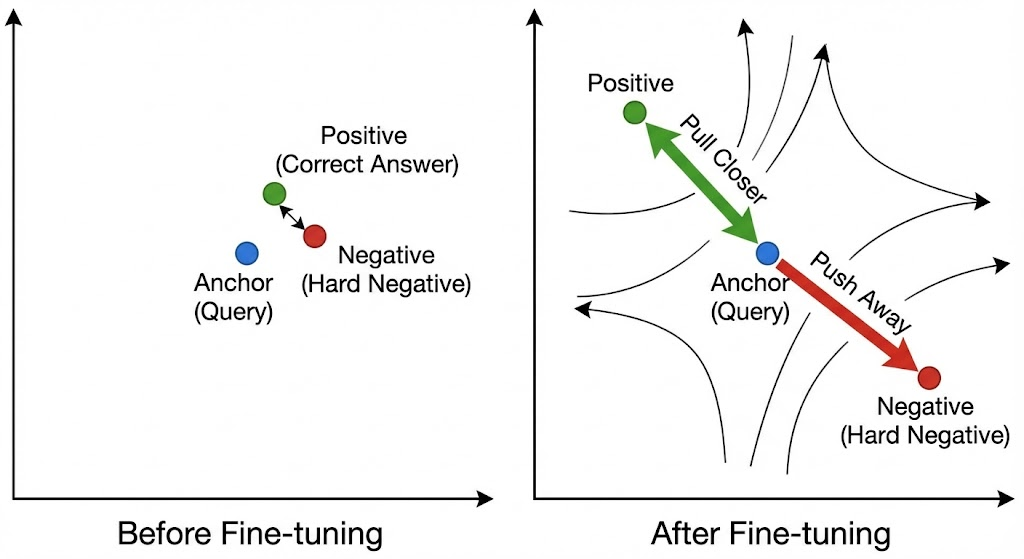
RAG 优化的“金字塔”:我们在哪一层?
在开始动手前,我们需要知道“模型微调”在 RAG 优化体系里的地位。RAG 的优化手段其实是一个金字塔:
•Level 1:Prompt 工程(最简单): 优化提问技巧,让大模型更好理解。•Level 2:切片策略 (Chunking): 把文档切得更科学,不切断语义。•Level 3:混合检索 (Hybrid Search): 向量检索 + 关键词检索 (BM25) 互补。•Level 4:重排 (Rerank): 在检索回来的结果里,用高精度模型再排一次序。•Level 5:Embedding 微调 (Fine-tuning)(最硬核): 直接改造模型的“大脑”,让它重新理解什么是“相似”,什么是“无关”。
如果前 4 层你都做过了,效果还是遇到瓶颈,那么微调 Embedding 就是你突破天花板的唯一路径。
技术选型:为什么不用“傻瓜式”工具?
市面上有很多微调工具,为什么我们要选择写代码?
•AutoTrain / LlamaIndex / ms-swift: 这些都是非常优秀的“开箱即用”工具(Wrapper)。它们像傻瓜相机,封装得很好,一行命令就能跑。但缺点是是个黑盒——你不知道它底层用了什么 Loss,不知道它是怎么处理数据的,一旦效果不好,你根本无从调试。•SentenceTransformers: 这是 PyTorch 生态下 Embedding 训练的事实标准,相当于摄影师手里的单反相机。 •透明: 你能看到每一行代码在干什么。 •强大: 完美支持 BGE、Jina 等主流模型。 •可控: 显存不够?调!负例不够?加!
云枢主张: 对于新手,第一次微调一定要用 SentenceTransformers 写一遍代码。只有理解了底层的“对比学习”原理,以后你才能驾驭那些自动化工具。
核心原理:大模型不懂“硬负例”
很多教程微调完效果不好,是因为忽略了**“硬负例”(Hard Negative)**。这是本篇文章最核心的概念,大家一定要懂。
教模型认“苹果”,有两种教法:
1.普通教学(Easy Negative): 拿个汽车,告诉它“这不是苹果”。这太简单了,模型闭着眼都能分清,学不到东西。2.硬核教学(Hard Negative): 拿个绿色的皮球,告诉它“这也是圆的、绿的,但它不是苹果”。
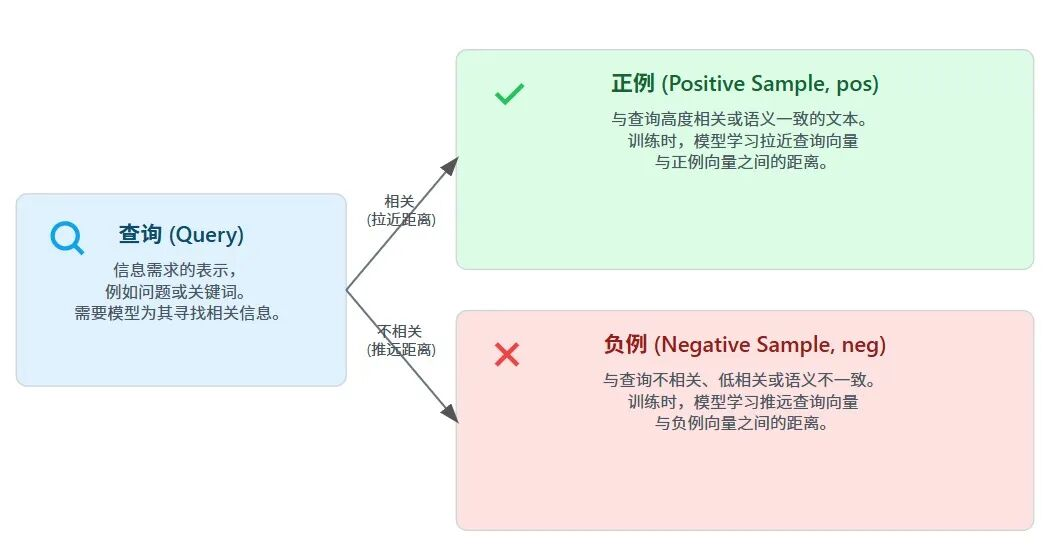
在 Embedding 微调中:
•简单负例: 随机抽一篇不相关的文档。•**硬负例:****“看起来很像,关键词重合度很高,但语义完全错误”**的文档。
比如搜“购房补贴”,BM25可能会搜出“购房落户”或“租房补贴”。它们字面极像,最容易迷惑模型。我们就要把这些作为负例喂给模型,强迫它学会区分“落户”和“补贴”的细微差别。
云枢的实战结论: 如果不加硬负例,微调效果可能只能提升 5%;加上硬负例,提升能达到 20%-30%!
实战环节:3090 单卡微调全流程
第一步:数据准备(LLM + BM25 自动挖掘)
我们做垂直领域,通常没有现成的训练数据。千万别人工标注! 那是上一代 AI 做的事。我们要用魔法打败魔法。
我为大家设计了一条自动化数据流水线:
1.出题人 (LLM): 让大模型阅读文档,生成问题。2.找茬人 (BM25): 用传统的关键词搜索 (BM25) 去库里搜这个问题。
•为什么要用 BM25? 因为 BM25 只看字面匹配,不看语义。它搜出来的错题,通常字面重合度极高(比如搜“补贴”出“罚款”)。这正是我们梦寐以求的“硬负例”!
(注:数据生成脚本较长,请在文末获取完整代码仓库,这里只展示核心逻辑)
def main():
# 1. 加载所有文件并切片
print("1. 正在扫描目录并加载数据...")
if not os.path.exists(INPUT_DIR):
print(f"目录不存在: {INPUT_DIR}")
return
corpus = load_data_from_dir(INPUT_DIR)
print(f"数据加载完成,共切分为 {len(corpus)} 个片段。")
if len(corpus) == 0:
print("未找到有效文本数据,请检查目录。")
return
# 2. 构建 BM25 索引(全局索引)
print("2. 正在构建 BM25 索引(用于硬负例挖掘)...")
# 对中文进行分词
tokenized_corpus = [list(jieba.cut(doc)) for doc in corpus]
bm25 = BM25Okapi(tokenized_corpus)
dataset = []
# 3. 开始循环生成
print("3. 开始生成问题并挖掘负例...")
# 限制处理数量用于测试,正式跑可以去掉 [:10]
for idx, doc_text in tqdm(enumerate(corpus), total=len(corpus), desc="Generating"):
# 生成正例 (Query)
queries = generate_queries(doc_text)
for query in queries:
# 挖掘负例 (Hard Negatives)
tokenized_query = list(jieba.cut(query))
scores = bm25.get_scores(tokenized_query)
top_n_indexes = sorted(range(len(scores)), key=lambda i: scores[i], reverse=True)[:BM25_TOP_K]
hard_negatives = []
for neg_idx in top_n_indexes:
# 排除掉原文片段自己
if neg_idx == idx or corpus[neg_idx] == doc_text:
continue
hard_negatives.append(corpus[neg_idx])
if len(hard_negatives) >= NEG_COUNT:
break
# 补齐负例
retry_count = 0
while len(hard_negatives) < NEG_COUNT and retry_count < 20:
random_neg = random.choice(corpus)
if random_neg != doc_text and random_neg not in hard_negatives:
hard_negatives.append(random_neg)
retry_count += 1
# 组装数据
data_item = {
"query": query,
"pos": [doc_text],
"neg": hard_negatives
}
dataset.append(data_item)
# 4. 保存文件
print(f"4. 正在保存数据到 {OUTPUT_FILE}...")
with open(OUTPUT_FILE, 'w', encoding='utf-8') as f:
for item in dataset:
f.write(json.dumps(item, ensure_ascii=False) + '\n')
print(f"任务完成!训练数据已生成。")
跑完这个脚本,你就得到了一份高质量的、带有“陷阱”的训练数据,格式如下:
{
"query": "高层次人才购房补贴标准是多少?",
"pos": ["给予A类人才最高300万元购房补贴..."],
"neg": [
"大学生租房补贴标准为每月...", // 硬负例1:租房补贴
"人才购房落户需满足以下条件..." // 硬负例2:购房落户
]
}
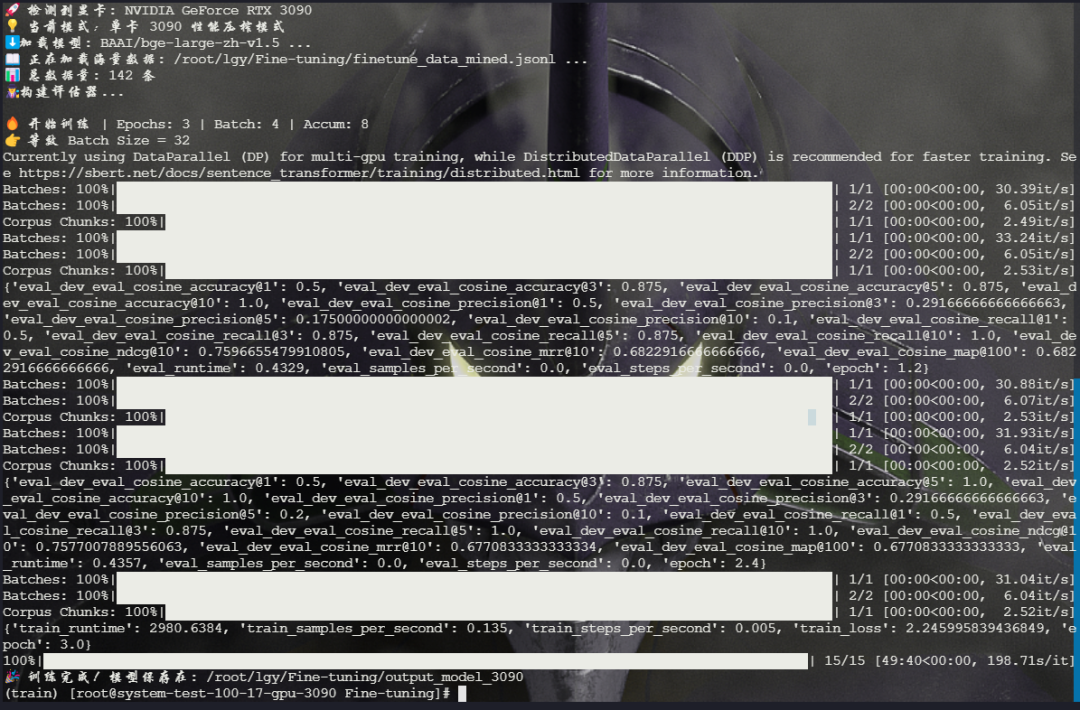
第二步:模型微调(解决显存爆炸)
数据有了,开始训练。这里演示使用的是单张 24G 显存的 3090,一跑代码就 OOM。 因为带了硬负例后,模型一次要处理 1(问) + 1(正) + 4(负) = 6 个句子!
为了让单卡能跑,云枢使用了**“单卡黄金配置”**,主要靠三招:
1.梯度检查点 (Gradient Checkpointing): 用算力换显存,必开。2.混合精度 (FP16): 显存占用减半。3.梯度累积: 既然显存小,我们就把 Batch Size 设小(比如 4),多跑几步再更新参数。
核心代码:
from sentence_transformers import SentenceTransformer, losses
from torch.utils.data import DataLoader
MODEL_NAME = "BAAI/bge-large-zh-v1.5" # 选个好点的中文基座
BATCH_SIZE = 4 # 3090 单卡建议 4-6
MAX_SEQ_LENGTH = 256 # 垂直领域 256 长度足够,非常省显存
def train():
# 加载模型
model = SentenceTransformer(MODEL_NAME)
model.max_seq_length = MAX_SEQ_LENGTH
# 开启梯度检查点,防 OOM 的关键!
model.gradient_checkpointing_enable()
# 准备数据
train_dataloader = DataLoader(train_examples, shuffle=True, batch_size=BATCH_SIZE)
# 定义损失函数:MultipleNegativesRankingLoss
# 会自动把 batch 内的其他数据也作为负例,极其高效
train_loss = losses.MultipleNegativesRankingLoss(model=model, scale=20.0)
# 4. 开始训练
model.fit(
train_objectives=[(train_dataloader, train_loss)],
epochs=3,
output_path="./output_model_final",
save_best_model=True,
use_amp=True # 开启 FP16 混合精度
)
if __name__ == "__main__":
train()
第三步:效果验证
微调完,到底有没有用?我们写个对比脚本,让基座模型和微调模型同台竞技。
核心逻辑:
# 加载两个模型
base_model = SentenceTransformer("BAAI/bge-large-zh-v1.5")
ft_model = SentenceTransformer("./output_model_final")
# 计算 Query 与 正例/负例 的相似度
q_emb = model.encode(query)
p_emb = model.encode(pos_doc)
n_emb = model.encode(neg_doc)
print(f"正例得分: {util.cos_sim(q_emb, p_emb)}")
print(f"负例得分: {util.cos_sim(q_emb, n_emb)}")
**真实运行结果(政务场景):**Case 1:用户提问“高层次人才购房补贴”
| 模型 | 正例得分 (购房补贴) | 负例得分 (购房落户/租房补贴) | 区分度 (正 - 负) | 评价 |
|---|---|---|---|---|
| 微调前 | 0.91 | 0.89 | 0.02 | ❌ 极差,几乎分不清,容易搜错 |
| 微调后 | 0.82 | 0.35 | 0.47 | ✅ 完美,一眼就能把干扰项踢开 |
解惑:为什么微调后正例得分变低了?
细心的朋友会发现:微调前正例是 0.91,微调后怎么变成 0.82 了?模型变傻了吗?
恰恰相反!这是模型变聪明的表现。
•基座模型像个近视眼,看谁都像好人,所以给分都虚高(0.91 vs 0.89)。•微调模型戴上了眼镜,看清了负例其实是“坏人”,把它狠狠推远(0.89 -> 0.35)。为了拉开这个距离,正例的绝对分数自然会回归理性(0.91 -> 0.82)。
记住:RAG 要的是排序(Ranking),只要区分度(Gap)拉大了,微调就是成功的!
总结
通过今天这篇文章,我们没有使用任何黑盒工具,而是从数据挖掘原理到代码落地,彻底跑通了 Embedding 微调。
你会发现,当你把“硬负例”喂给模型后,它仿佛瞬间开窍了,能精准识别那些曾经让它困惑的“行业黑话”。
**下一步做什么?**虽然代码微调很爽,但在大规模工程化场景下,我们可能需要更快捷的工具。下期文章,我将教大家使用 AutoTrain 、FlagEmbedding Runner、Llama Index、ms-swift 体验“一行命令”的多卡训练!
获取本文完整代码(包含数据生成脚本、防OOM训练脚本、对比评估脚本):请在公众号后台回复关键词:【微调实战】
如果内容对您有帮助,欢迎点赞、关注、转发,后期笔者会持续更新优质内容教程。
想入门 AI 大模型却找不到清晰方向?备考大厂 AI 岗还在四处搜集零散资料?别再浪费时间啦!2025 年 AI 大模型全套学习资料已整理完毕,从学习路线到面试真题,从工具教程到行业报告,一站式覆盖你的所有需求,现在全部免费分享!
👇👇扫码免费领取全部内容👇👇

一、学习必备:100+本大模型电子书+26 份行业报告 + 600+ 套技术PPT,帮你看透 AI 趋势
想了解大模型的行业动态、商业落地案例?大模型电子书?这份资料帮你站在 “行业高度” 学 AI:
1. 100+本大模型方向电子书

2. 26 份行业研究报告:覆盖多领域实践与趋势
报告包含阿里、DeepSeek 等权威机构发布的核心内容,涵盖:

- 职业趋势:《AI + 职业趋势报告》《中国 AI 人才粮仓模型解析》;
- 商业落地:《生成式 AI 商业落地白皮书》《AI Agent 应用落地技术白皮书》;
- 领域细分:《AGI 在金融领域的应用报告》《AI GC 实践案例集》;
- 行业监测:《2024 年中国大模型季度监测报告》《2025 年中国技术市场发展趋势》。
3. 600+套技术大会 PPT:听行业大咖讲实战
PPT 整理自 2024-2025 年热门技术大会,包含百度、腾讯、字节等企业的一线实践:

- 安全方向:《端侧大模型的安全建设》《大模型驱动安全升级(腾讯代码安全实践)》;
- 产品与创新:《大模型产品如何创新与创收》《AI 时代的新范式:构建 AI 产品》;
- 多模态与 Agent:《Step-Video 开源模型(视频生成进展)》《Agentic RAG 的现在与未来》;
- 工程落地:《从原型到生产:AgentOps 加速字节 AI 应用落地》《智能代码助手 CodeFuse 的架构设计》。
二、求职必看:大厂 AI 岗面试 “弹药库”,300 + 真题 + 107 道面经直接抱走
想冲字节、腾讯、阿里、蔚来等大厂 AI 岗?这份面试资料帮你提前 “押题”,拒绝临场慌!

1. 107 道大厂面经:覆盖 Prompt、RAG、大模型应用工程师等热门岗位
面经整理自 2021-2025 年真实面试场景,包含 TPlink、字节、腾讯、蔚来、虾皮、中兴、科大讯飞、京东等企业的高频考题,每道题都附带思路解析:

2. 102 道 AI 大模型真题:直击大模型核心考点
针对大模型专属考题,从概念到实践全面覆盖,帮你理清底层逻辑:

3. 97 道 LLMs 真题:聚焦大型语言模型高频问题
专门拆解 LLMs 的核心痛点与解决方案,比如让很多人头疼的 “复读机问题”:

三、路线必明: AI 大模型学习路线图,1 张图理清核心内容
刚接触 AI 大模型,不知道该从哪学起?这份「AI大模型 学习路线图」直接帮你划重点,不用再盲目摸索!

路线图涵盖 5 大核心板块,从基础到进阶层层递进:一步步带你从入门到进阶,从理论到实战。

L1阶段:启航篇丨极速破界AI新时代
L1阶段:了解大模型的基础知识,以及大模型在各个行业的应用和分析,学习理解大模型的核心原理、关键技术以及大模型应用场景。

L2阶段:攻坚篇丨RAG开发实战工坊
L2阶段:AI大模型RAG应用开发工程,主要学习RAG检索增强生成:包括Naive RAG、Advanced-RAG以及RAG性能评估,还有GraphRAG在内的多个RAG热门项目的分析。

L3阶段:跃迁篇丨Agent智能体架构设计
L3阶段:大模型Agent应用架构进阶实现,主要学习LangChain、 LIamaIndex框架,也会学习到AutoGPT、 MetaGPT等多Agent系统,打造Agent智能体。

L4阶段:精进篇丨模型微调与私有化部署
L4阶段:大模型的微调和私有化部署,更加深入的探讨Transformer架构,学习大模型的微调技术,利用DeepSpeed、Lamam Factory等工具快速进行模型微调,并通过Ollama、vLLM等推理部署框架,实现模型的快速部署。

L5阶段:专题集丨特训篇 【录播课】

四、资料领取:全套内容免费抱走,学 AI 不用再找第二份
不管你是 0 基础想入门 AI 大模型,还是有基础想冲刺大厂、了解行业趋势,这份资料都能满足你!
现在只需按照提示操作,就能免费领取:
👇👇扫码免费领取全部内容👇👇
2025 年想抓住 AI 大模型的风口?别犹豫,这份免费资料就是你的 “起跑线”!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









