



大模型时代,向量数据库成了AI应用的“记忆中枢”。从智能客服到个性化推荐,语义搜索的背后,都是它在高效匹配高维向量。但 FAISS、Milvus、Pinecone、Chroma、Qdrant……这么多选择,到底该怎么挑?本文带你快速看懂主流向量数据库的特点与适用场景。
一、向量数据库介绍
1.1.如何让LLM“记住”并利用海量、多样的私有知识?
向量数据库是AI时代的核心记忆体。与传统的关系型数据库不同,向量数据库用于存储和查询由非结构化数据(如文本、图片、音视频)转化而来的高维向量嵌入(Embeddings)。这些向量在多维空间中的距离代表了原始数据的语义相似度。
因此,向量数据库的核心能力是高效的相似性检索。
1.2.什么是向量数据库?
向量数据库,是专门为向量检索设计的中间件!
高效存储、快速检索和管理高纬度向量数据的系统称为向量数据库
一种专门用于存储和检索高维向量数据的数据库。它将数据(如文本、图像、音频等)通过嵌入模型转换为向量形式,并通过高效的索引和搜索算法实现快速检索。
向量数据库的核心作用是实现相似性搜索,即通过计算向量之间的距离(如欧几里得距离、余弦相似度等)来找到与目标向量最相似的其他向量。它特别适合处理非结构化数据,支持语义搜索、内容推荐等场景。
1.3.向量数据库的核心价值?
- 为大模型提供长期记忆
弥补大模型上下文窗口(Context Window)长度限制和知识更新延迟的问题。
- 实现私有知识库的问答与搜索
将企业内部文档、产品信息等转化为向量,实现基于语义的智能检索。
- 赋能推荐系统、以图搜图等多种应用
通过计算用户、物品的向量相似度,提供更精准的推荐。
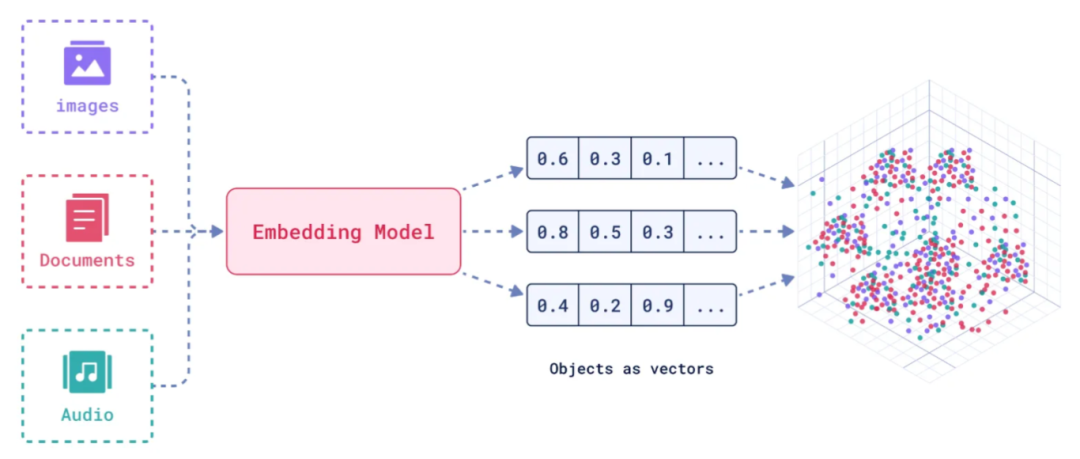
1.4.如何存储和检索嵌入向量?
-
存储
向量数据库将嵌入向量存储为高维空间中的点,并为每个向量分配唯一标识符(ID),同时支持存储元数据。
-
检索
通过近似最近邻(ANN)算法(如PQ等)对向量进行索引和快速搜索。比如,FAISS和Milvus等数据库通过高效的索引结构加速检索。
1.5.向量数据库与传统数据库对比
1.数据类型
- 传统数据库:存储结构化数据(如表格、行、列)。
- 向量数据库:存储高维向量数据,适合非结构化数据。
2.查询方式
- 传统数据库:依赖精确匹配(如=、<、>)。
- 向量数据库:基于相似度或距离度量(如欧几里得距离、余弦相似度)。
3.应用场景
- 传统数据库:适合事务记录和结构化信息管理。
- 向量数据库:适合语义搜索、内容推荐等需要相似性计算的场景。
1.6.澄清几个关键概念:
- 向量数据库的意义是快速的检索;
- 向量数据库本身不生成向量,向量是由 Embedding 模型产生的;
- 向量数据库与传统的关系型数据库是互补的,不是替代关系,在实际应用中根据实际需求经常同时使用。
二、主流向量数据库功能对比
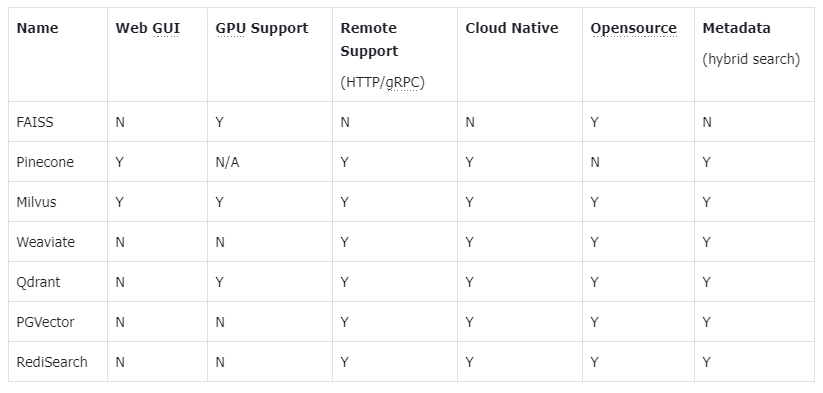
- FAISS
特点:由Facebook开发,专注于高性能的相似性搜索,适合大规模静态数据集,支持CPU与GPU加速。
优势:检索速度快,支持多种索引类型;内存效率高。
局限性:主要用于静态数据,更新和删除操作较复杂。
适用场景:离线批处理、研究实验、高性能近似最近邻搜索原型。
https://github.com/facebookresearch/faiss
- Pinecone
特点:托管的云原生向量数据库,支持高性能的向量搜索。
优势:完全托管、易于部署、自动扩缩容;SLA保障,企业级安全合规。
适用场景:RAG、推荐系统、智能客服等需要高可用、低运维负担的生产环境。
https://www.pinecone.io/
- Milvus
特点:开源、云原生向量数据库,支持分布式架构,支持企业级,数据量大,并发量大、横向扩容。
优势:具备强大的扩展性和灵活的数据管理功能。
适用场景:大规模AI应用、需要强扩展性与高并发的企业级系统。
https://milvus.io/
- Weaviate
特点:开源、AI原生量数据库,支持语义搜、RAG与Agentic AI,可对接Hugging Face、OpenAI等。
优势:支持混合搜索(向量+关键字)、多租户,可本地部署或云服务;强调端到端的AI应用构建。
局限性:超大规模(>10亿向量)性能不如Milvus。
适用场景:知识图谱增强搜索、语义回答、快速构建RAG或中小规模生产系统。
https://weaviate.io/
- Qdrant
特点:开源、高性能向量数据库,强调速度与可靠性,支持云服务与私有部署。
优势:内存效率高,支持量化压缩;API简洁(REST);适合边缘部署。
局限性:生态和工具链略逊于Milvus;多向量仍在演进中。
适用场景:适用推荐系统、公司内部知识库、多模态搜索、对性能与资源占用敏感的应用。
https://qdrant.tech/
- Chroma
特点:开源、轻量级向量数据库,专为大模型应用(如 RAG)设计,以内嵌库形式提供高维向量的语义相似性搜索能力。
优势:嵌入式部署、框架兼容性强、支持灵活存储与毫秒级检索。
局限性:单机架构,缺乏分布式扩展能力,企业级功能尚不成熟。
适用场景:LLM应用快速原型开发、中小规模RAG、内部知识库等部署简易性和开发效率高的场景。
https://docs.trychroma.com/docs/overview/introduction
- RediSearch
特点:Redis官方集成的查询与索引引擎,支持全文、向量、地理等多维搜索。
优势:极低延迟;与Redis生态无缝副合(Pub/Sub、Stream)
局限性:内存数据库,成本高;向量规模受限于内存容量;分布式能力依赖Redis Cluster(配置复杂)。
https://github.com/RediSearch/RediSearch
- ElasticSearch
特点:强大的分布式搜索和分析引擎,将向量搜索(k-NN)作为其众多功能之一。
优势:具备业界领先的混合搜索能力,可以无缝结合传统的关键词搜索和向量语义搜索。
局限性:向量搜索非核心设计,ANN性能与专用向量数据库相比略逊;资源消耗大,配置调优复杂。
https://www.elastic.co/enterprise-search/vector-search
扩展阅读: https://guangzhengli.com/blog/zh/vector-database
三、如何将数据导入向量数据库?
- 1.数据清洗与准备
确保原始数据(如文本文档、图片)的质量,进行必要的预处理。
- 2.数据向量化(Embedding)
使用预训练的Embedding Model将原始数据转换成向量。
文本:可使用bge-m,Qwen3-Embedding,Jina-Embedding等模型。
图片:可使用CLIP,ResNet等模型。
选择合适的模型至关重要,它直接决定向量的质量和后续检索的效果。
- 3.创建元数据存储
将生成的向量及关联元数据(Metadata)一同存入向量数据库。
-
向量(Vecotor):生成的Embedding数字数组。
-
唯一ID(ID):用于唯一标识每个数据点,方便后续更新或删除。
-
元数据(Metadata):描述向量的附加信息,是实现高级检索的关键。例如:文本来源的文件名、章节、URL;商品的类别、品牌、价格;图片的创建日期、作者。
-
4.构建索引并****添加数据到索引
构建索引,并将生成的向量和对应的ID添加到IndexIDMap中。
四、向量数据库使用示例
4.1.Chroma
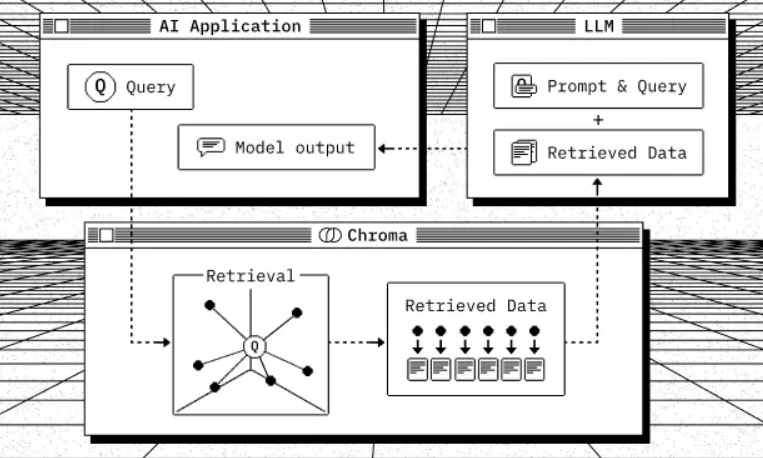
- 安装
通过包管理器安装ChromaDB初始化客户端
pip install chromadb
- 初始化客户端
内存模式(不建议使用)
import chromadb
client = chromadb.Client()
持久化模式
import chromadb
# 数据保存至本地目录
client = chromadb.PersistentClient(path="d:/m3emodel/chroma_db")
- Chroma核心操作流程-集合
集合是 Chroma 中管理数据的基本单元,类似关系数据库的表:
- 创建集合
from chromadb.utils import embedding_functions
# 默认情况下,Chroma 使用 DefaultEmbeddingFunction,它是基于 Sentence Transformers 的 MiniLM-L6-v2 模型
default_ef = embedding_functions.DefaultEmbeddingFunction()
collection = client.create_collection(
name = "my_collection",
configuration = {
# HNSW 索引算法,基于图的近似最近邻搜索算法(Approximate Nearest Neighbor,ANN)
"hnsw": {
"space": "cosine", # 指定余弦相似度计算
"ef_search": 100,
"ef_construction": 100,
"max_neighbors": 16,
"num_threads": 4
},
# 指定向量模型
"embedding_function": default_ef
}
)
- 查询集合
collection = client.get_collection(name="my_collection")
print(collection.peek())
print(collection.count())
- 删除集合
client.delete_collection(name="my_collection")
-
Chroma核心操作流程-添加数据
支持自动生成或手动指定嵌入向量。
# 方式1:自动生成向量(使用集合指定的嵌入模型)
collection.add(
documents = ["RAG是一种检索增强生成技术", "向量数据库存储文档的嵌入表示", "在机器学习领域,智能体(Agent)通常指能够感知环境、做出决策并采取行动以实现特定目标的实体"],
metadatas = [{"source": "RAG"}, {"source": "向量数据库"}, {"source": "Agent"}],
ids = ["id1", "id2", "id3"]
)
# 方式2:手动传入预计算向量
# collection.add(
# embeddings = [[0.1, 0.2, ...], [0.3, 0.4, ...]],
# documents = ["文本1", "文本2"],
# ids = ["id3", "id4"]
# )
- Chroma核心操作流程-查询数据
results = collection.query(
query_texts = ["RAG是什么?"],
n_results = 3,
#where = {"source": "RAG"}, # 按元数据过滤
#where_document = {"$contains": "检索增强生成"} # 按文档内容过滤
)
print(results)
{'ids': [['id1', 'id2']], 'embeddings': None, 'documents': [['RAG是一种检索增强生成技术,在智能客服系统中大量使用', '向量数据库存储文档的嵌入表示']], 'uris': None, 'included': ['metadatas', 'documents', 'distances'], 'data': None, 'metadatas': [[{'source': 'RAG'}, {'source': '向量数据库'}]], 'distances': [[0.34913837909698486, 0.5758516788482666]]}
- Chroma核心操作流程-查询数据
# 更新集合中的数据:
collection.update(ids=["id1"], documents=["RAG是一种检索增强生成技术,在智能客服系统中大量使用"])
删除集合中的数据:
collection.delete(ids=["id3"])
- Chroma Client-Server Model
- Server端
chroma run --path /db_path
chroma run --path d:\chromadb --host 0.0.0.0 --port 8000
# 建议使用第二种,否则client无法连接
测试Chroma是否响应
http://localhost:8000/api/v2/heartbeat
返回:
{“nanosecond heartbeat”:1748264596156232000}
或者
curl http://localhost:8000/api/v2/heartbeat
返回:
C:\Users\DELL>curl http://localhost:8000/api/v2/heartbeat
{“nanosecond heartbeat”:1748264833034387700}
- Client端使用
import chromadb
chroma_client = chromadb.HttpClient(host='localhost', port=8000)
# 列出所有集合
collections = chroma_client.list_collections()
print(collections)
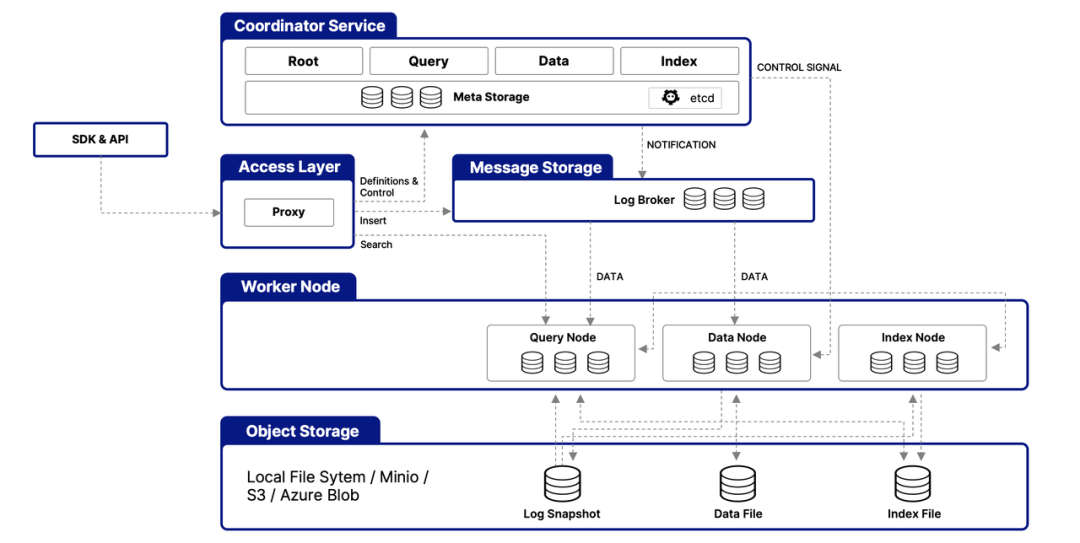
4.2.Milvus
Milvus 架构图
-
安装
请确保本地环境中有 Python 3.8+ 可用。安装
pymilvus,其中包含 python 客户端库和 Milvus Lite
pip install -U pymilvus
Milvus 支持在Docker和Kubernetes上部署,适用于生产用例。
-
设置向量数据库
要创建本地的 Milvus 向量数据库,只需实例化一个
MilvusClient,指定一个存储所有数据的文件名,如 “milvus_demo.db”。
from pymilvus import MilvusClient
client = MilvusClient("milvus_demo.db")
- 创建 Collections
在 Milvus 中,我们需要一个 Collections 来存储向量及其相关元数据。你可以把它想象成传统 SQL 数据库中的表格。创建 Collections 时,可以定义 Schema 和索引参数来配置向量规格,如维度、索引类型和远距离度量。
if client.has_collection(collection_name="demo_collection"):
client.drop_collection(collection_name="demo_collection")
client.create_collection(
collection_name="demo_collection",
dimension=768, # 768维
)
- 准备数据
下载 embedding 模型为文本生成向量。
pip install "pymilvus[model]"
用默认模型生成向量 Embeddings。Milvus 希望数据以字典列表的形式插入,每个字典代表一条数据记录,称为实体。
from pymilvus import model
# 这将下载一个小型嵌入模型“interprecede-albert-small-v2”(约50MB)。
embedding_fn = model.DefaultEmbeddingFunction()
docs = [
"人工智能于1956年作为一门学科成立。",
"阿兰·图灵是第一个在人工智能领域进行实质性研究的人。",
"图灵出生于伦敦的麦达谷,在英格兰南部长大。",
]
vectors = embedding_fn.encode_documents(docs)
#输出向量有768个维度,与我们刚才创建的集合相匹配。
print("Dim:", embedding_fn.dim, vectors[0].shape) # Dim: 768 (768,)
#每个实体都有id、向量表示、原始文本和我们使用的主题标签
data = [
{"id": i, "vector": vectors[i], "text": docs[i], "subject": "history"}
for i in range(len(vectors))
]
print("Data has", len(data), "entities, each with fields: ", data[0].keys())
print("Vector dim:", len(data[0]["vector"]))
Dim: 768 (768,)
Data has 3 entities, each with fields: dict_keys([‘id’, ‘vector’, ‘text’, ‘subject’])
Vector dim: 768
- 插入数据
把数据插入 Collections:
res = client.insert(collection_name="demo_collection", data=data)
print(res)
{‘insert_count’: 3, ‘ids’: [0, 1, 2], ‘cost’: 0}
- 语义搜索
通过将搜索查询文本表示为向量来进行语义搜索,并在 Milvus 上进行向量相似性搜索。
-
向量搜索
Milvus 可同时接受一个或多个向量搜索请求。query_vectors 变量的值是一个向量列表,其中每个向量都是一个浮点数数组。
query_vectors = embedding_fn.encode_queries(["阿兰·图灵是谁?"])
res = client.search(
collection_name="demo_collection", # 目标集合
data=query_vectors, # 查询向量
limit=2, # 返回的实体数量
output_fields=["text", "subject"], # 指定要返回的字段
)
print(res)
data: [“[{‘id’: 2, ‘distance’: 0.5859944820404053, ‘entity’: {‘text’: ‘图灵出生于伦敦的麦达谷,在英格兰南部长大。’, ‘subject’: ‘history’}}, {‘id’: 1, ‘distance’: 0.5118255615234375, ‘entity’: {‘text’: ‘Alan Turing是第一个对人工智能进行实质性研究的人。’, ‘subject’: ‘history’}}]”] , extra_info: {‘cost’: 0}
输出结果是一个结果列表,每个结果映射到一个向量搜索查询。每个查询都包含一个结果列表,其中每个结果都包含实体主键、到查询向量的距离以及指定output_fields 的实体详细信息。
-
删除实体
如果想清除数据,可以删除指定主键的实体,或删除与特定过滤表达式匹配的所有实体。
res = client.delete(collection_name="demo_collection", ids=[0, 2])
print(res)
res = client.delete(
collection_name="demo_collection",
filter="subject == 'biology'",
)
print(res)
- 加载现有数据
from pymilvus import MilvusClient
client = MilvusClient("milvus_demo.db")
- 删除Collection
client.drop_collection(collection_name="demo_collection")
- 调用Server
指定Milvus 服务器的URI 和令牌
client = MilvusClient(uri="http://localhost:19530", token="root:Milvus")
更详细见官方文档 :https://milvus.io/docs/zh/
五、完整示例
采用Faiss 实现数据导入和检索
- 安装
pip install faiss-cpu # 使用 CPU 版本的 FAISS
pip install faiss-gpu # 使用 GPU 加速版本的 FAISS
- 初始化 API 客户端
# Step1. 初始化 API 客户端
try:
client = OpenAI(
api_key=os.getenv("DASHSCOPE_API_KEY"),
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1"
)
except Exception as e:
print("初始化OpenAI客户端失败,请检查环境变量'DASHSCOPE_API_KEY'是否已设置。")
print(f"错误信息: {e}")
exit()
- 准备示例文本和元数据
# Step2. 准备示例文本和元数据
# 在实际应用中,这些数据可能来自数据库、文件等
documents = [
{
"id": "doc1",
"text": "商城商品一经售出,原则上不支持无理由退换。但若商品存在质量问题,用户可在签收后7天内申请退换货,并提供相关凭证。",
"metadata": {"source": "return_policy_v1.pdf", "category": "退换货政策", "author": "CustomerService"}
},
{
"id": "doc2",
"text": "开通“会员PLUS”服务的用户,可享受全年免运费、专属折扣及优先客服响应等权益。",
"metadata": {"source": "membership_benefits.docx", "category": "会员权益", "author": "MarketingDept"}
},
{
"id": "doc3",
"text": "通过APP下单的用户如需取消订单,须在订单发货前操作;已发货订单需拒收后方可申请退款,退款将在仓库确认收货后3个工作日内处理。",
"metadata": {"source": "app_order_guide.html", "category": "退换货政策", "author": "E-commerceTeam"}
},
{
"id": "doc4",
"text": "因系统升级,商城支付功能将于本周六凌晨0:00至6:00暂停服务,请提前完成结算。",
"metadata": {"source": "system_maintenance.txt", "category": "平台公告", "author": "TechOps"}
}
]
- 创建元数据存储和向量列表
Step3. 创建元数据存储和向量列表
# 我们使用一个简单的列表来存储元数据。列表的索引将作为FAISS的ID。
# 这种方式简单直接,适用于中小型数据集。
# 对于大型数据集,可以考虑使用字典或数据库(如Redis, SQLite)
metadata_store = []
vectors_list = []
vector_ids = []
print("正在为文档生成向量...")
for i, doc in enumerate(documents):
try:
# 调用API生成向量
completion = client.embeddings.create(
model="text-embedding-v4",
input=doc["text"],
dimensions=1024,
encoding_format="float"
)
# 获取向量
vector = completion.data[0].embedding
vectors_list.append(vector)
# 存储元数据,并使用列表索引作为唯一ID
metadata_store.append(doc)
vector_ids.append(i) # 自定义ID与列表索引一致
print(f" - 已处理文档 {i+1}/{len(documents)}")
except Exception as e:
print(f"处理文档 '{doc['id']}' 时出错: {e}")
continue
# 将向量列表转换为NumPy数组,FAISS需要这种格式
vectors_np = np.array(vectors_list).astype('float32')
vector_ids_np = np.array(vector_ids)
- 构建并填充 FAISS 索引
# Step4. 构建并填充 FAISS 索引
dimension = 1024 # 向量维度
k = 3 # 查找最近的3个邻居
# 创建一个基础的L2距离索引
index_flat_l2 = faiss.IndexFlatL2(dimension)
# 使用IndexIDMap来包装基础索引,能够映射我们自定义的ID
# 这就是关联向量和元数据的关键!
index = faiss.IndexIDMap(index_flat_l2)
# 将向量和它们对应的ID添加到索引中
index.add_with_ids(vectors_np, vector_ids_np)
print(f"\nFAISS 索引已成功创建,共包含 {index.ntotal} 个向量。")
- 执行搜索并检索元数据
# Step5. 执行搜索并检索元数据
query_text = "我想了解退换货政策"
print(f"\n正在为查询文本生成向量: '{query_text}'")
# 为查询文本生成向量
query_completion = client.embeddings.create(
model="text-embedding-v4",
input=query_text,
dimensions=1024,
encoding_format="float"
)
query_vector = np.array([query_completion.data[0].embedding]).astype('float32')
# 在FAISS索引中执行搜索
# search方法返回两个NumPy数组:
# D: 距离 (distances)
# I: 索引/ID (indices/IDs)
distances, retrieved_ids = index.search(query_vector, k)
- 展示结果
# Step6. 展示结果
print("\n--- 搜索结果 ---")
# `retrieved_ids[0]` 包含与查询最相似的k个向量的ID
for i in range(k):
doc_id = retrieved_ids[0][i]
# 检查ID是否有效
if doc_id == -1:
print(f"\n排名 {i+1}: 未找到更多结果。")
continue
# 使用ID从我们的元数据存储中检索信息
retrieved_doc = metadata_store[doc_id]
print(f"\n--- 排名 {i+1} (相似度得分/距离: {distances[0][i]:.4f}) ---")
print(f"ID: {doc_id}")
print(f"原始文本: {retrieved_doc['text']}")
print(f"元数据: {retrieved_doc['metadata']}")
你正在用哪款向量数据库?遇到过哪些坑?
想入门 AI 大模型却找不到清晰方向?备考大厂 AI 岗还在四处搜集零散资料?别再浪费时间啦!2025 年 AI 大模型全套学习资料已整理完毕,从学习路线到面试真题,从工具教程到行业报告,一站式覆盖你的所有需求,现在全部免费分享!
👇👇扫码免费领取全部内容👇👇

一、学习必备:100+本大模型电子书+26 份行业报告 + 600+ 套技术PPT,帮你看透 AI 趋势
想了解大模型的行业动态、商业落地案例?大模型电子书?这份资料帮你站在 “行业高度” 学 AI:
1. 100+本大模型方向电子书

2. 26 份行业研究报告:覆盖多领域实践与趋势
报告包含阿里、DeepSeek 等权威机构发布的核心内容,涵盖:

- 职业趋势:《AI + 职业趋势报告》《中国 AI 人才粮仓模型解析》;
- 商业落地:《生成式 AI 商业落地白皮书》《AI Agent 应用落地技术白皮书》;
- 领域细分:《AGI 在金融领域的应用报告》《AI GC 实践案例集》;
- 行业监测:《2024 年中国大模型季度监测报告》《2025 年中国技术市场发展趋势》。
3. 600+套技术大会 PPT:听行业大咖讲实战
PPT 整理自 2024-2025 年热门技术大会,包含百度、腾讯、字节等企业的一线实践:

- 安全方向:《端侧大模型的安全建设》《大模型驱动安全升级(腾讯代码安全实践)》;
- 产品与创新:《大模型产品如何创新与创收》《AI 时代的新范式:构建 AI 产品》;
- 多模态与 Agent:《Step-Video 开源模型(视频生成进展)》《Agentic RAG 的现在与未来》;
- 工程落地:《从原型到生产:AgentOps 加速字节 AI 应用落地》《智能代码助手 CodeFuse 的架构设计》。
二、求职必看:大厂 AI 岗面试 “弹药库”,300 + 真题 + 107 道面经直接抱走
想冲字节、腾讯、阿里、蔚来等大厂 AI 岗?这份面试资料帮你提前 “押题”,拒绝临场慌!

1. 107 道大厂面经:覆盖 Prompt、RAG、大模型应用工程师等热门岗位
面经整理自 2021-2025 年真实面试场景,包含 TPlink、字节、腾讯、蔚来、虾皮、中兴、科大讯飞、京东等企业的高频考题,每道题都附带思路解析:

2. 102 道 AI 大模型真题:直击大模型核心考点
针对大模型专属考题,从概念到实践全面覆盖,帮你理清底层逻辑:

3. 97 道 LLMs 真题:聚焦大型语言模型高频问题
专门拆解 LLMs 的核心痛点与解决方案,比如让很多人头疼的 “复读机问题”:

三、路线必明: AI 大模型学习路线图,1 张图理清核心内容
刚接触 AI 大模型,不知道该从哪学起?这份「AI大模型 学习路线图」直接帮你划重点,不用再盲目摸索!

路线图涵盖 5 大核心板块,从基础到进阶层层递进:一步步带你从入门到进阶,从理论到实战。

L1阶段:启航篇丨极速破界AI新时代
L1阶段:了解大模型的基础知识,以及大模型在各个行业的应用和分析,学习理解大模型的核心原理、关键技术以及大模型应用场景。

L2阶段:攻坚篇丨RAG开发实战工坊
L2阶段:AI大模型RAG应用开发工程,主要学习RAG检索增强生成:包括Naive RAG、Advanced-RAG以及RAG性能评估,还有GraphRAG在内的多个RAG热门项目的分析。

L3阶段:跃迁篇丨Agent智能体架构设计
L3阶段:大模型Agent应用架构进阶实现,主要学习LangChain、 LIamaIndex框架,也会学习到AutoGPT、 MetaGPT等多Agent系统,打造Agent智能体。

L4阶段:精进篇丨模型微调与私有化部署
L4阶段:大模型的微调和私有化部署,更加深入的探讨Transformer架构,学习大模型的微调技术,利用DeepSpeed、Lamam Factory等工具快速进行模型微调,并通过Ollama、vLLM等推理部署框架,实现模型的快速部署。

L5阶段:专题集丨特训篇 【录播课】

四、资料领取:全套内容免费抱走,学 AI 不用再找第二份
不管你是 0 基础想入门 AI 大模型,还是有基础想冲刺大厂、了解行业趋势,这份资料都能满足你!
现在只需按照提示操作,就能免费领取:
👇👇扫码免费领取全部内容👇👇
2025 年想抓住 AI 大模型的风口?别犹豫,这份免费资料就是你的 “起跑线”!

















 1548
1548

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









