



🎯 本文从原理介绍到编程实战详细的阐述了 LangChain 的设计和使用
🎯 大家可以将此文档作为 LangChain 的 “快速进阶” 学习手册,希望帮助您实现 AI 工程的 Bootstrap
1、LangChain 介绍
LangChain 是 2022 年 10 月底,由哈佛大学的 Harrison Chase 发起的基于开源大语言模型用于开发由AI 大语言模型驱动的应用程序的开源框架。旨在帮助开发者构建和部署语言模型的应用程序。
它提供了一个模块化和可扩展的平台,使得整合多个语言模型和其他工具变得容易,从而创建更加强大和灵活的应用。顾名思义,LangChain 中的 “Lang” 是指大语言模型,“Chain” 即 “链”,也就是将大模型与其他组件连接成链,借此构建 AI 工程应用。
🌐 相关资料
- github地址
https://github.com/langchain-ai/langchain - 官网地址
https://www.langchain.com/langchain - 官网文档
https://python.langchain.com/docs/introduction/ - 中文文档
https://www.langchain.com.cn/ - API 文档
https://python.langchain.com/api_reference/ - Java版本
https://github.com/langchain4j/langchain4j
1.1 什么是 AI 工程
**🎯目标:**待解决的特定 AI 用户需求。如内容创作、智能问答、文档摘要、图像识别等等。
**🙋♂️人:**实施 AI 工程的具体角色。可以是程序员,或者 AI 应用的研发团队、创业公司。
**🔬科学 | 技术:**显然是大模型与相关工具服务,以及其后的计算科学理论。
**📜实体:**已有的文档、知识库、业务数据等生产材料。
**🛠️产品:**能满足目标需求的具体产品。如聊天机器人、内容生成工具等。
因此,LangChain 的设计就是希望构建通用的 AI 工程框架,即:
- 【目标 | 产品】
LangChain的设计目标是什么,能解决哪些AI工程问题? - 【人】
LangChain的编程接口如何定义,才能提升AI工程师的研发效率? - 【实体 | 科学 | 技术】
LangChain的核心组件如何抽象,以提升框架的扩展能力?
最终,LangChain 的核心设计思路如下:
- 作为AI工程框架,LangChain实际是对 LLM 能力的扩展和补充。如果把 LLM 比作人的大脑,LangChain 则是人的躯干和四肢,协助 LLM 完成“思考”之外的“脏活累活”。它的能力边界只取决于LLM 的智力水平和LangChain 能提供的工具集的丰富程度。
- LangChain提供了LCEL(LangChain Expression Language)声明式编程语言,降低AI工程师的研发成本。
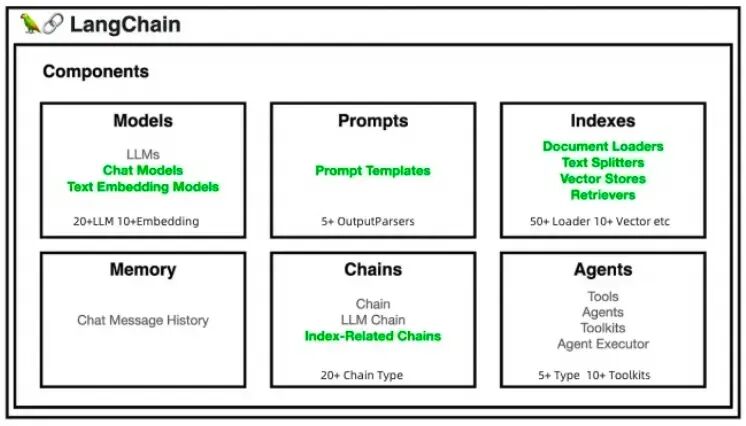
- LangChain提供了Models、Prompts、Indexes、Memory、Chains、Agents六大核心抽象,用于构建复杂的AI应用,同时保持了良好的扩展能力。
1.2 LangChain 的主要特点
1.模型集成:LangChain 支持多种语言模型,包括大型模型如 GPT-3,以及自定义模型。
2.工具连接:LangChain 可以连接到各种工具和API,使得模型能够利用外部资源来增强其回答的准确性和实用性。
3.记忆功能:LangChain 允许应用程序存储和检索对话历史,从而在对话中保持上下文连续性。
4.模块化设计:LangChain 的设计是模块化的,使得开发者可以根据需要轻松地添加或替换组件。
5.多语言支持:LangChain 支持多种编程语言,使得开发者可以使用他们熟悉的语言来构建应用程序。
LangChain 的目标是通过提供一个灵活的框架,使得开发者能够快速构建和迭代语言模型驱动的应用程序,从而推动语言模型的创新和应用。
它使得应用程序能够:
- 具有上下文感知能力:将语言模型连接到上下文来源(提示指令,少量的示例,需要回应的内容等)
- 具有推理能力:依赖语言模型进行推理(根据提供的上下文如何回答,采取什么行动等)
1.3 组成部分
- LangChain 库:Python 和 JavaScript 库。包含了各种组件的接口和集成,一个基本的运行时,用于将这些组件组合成链和代理,以及现成的链和代理的实现。
- LangChain 模板:一系列易于部署的参考架构,用于各种任务。
- LangServe:一个用于将 LangChain 链部署为 REST API 的库。
- LangSmith:一个开发者平台,让你可以调试、测试、评估和监控基于任何 LLM 框架构建的链,并且与 LangChain 无缝集成。
1.4 简化的应用程序生命周期
- 开发:在 LangChain/LangChain.js 中编写你的应用程序。使用模板作为参考,快速开始。
- 生产化:使用 LangSmith 来检查、测试和监控你的链,这样你可以不断改进并有信心地部署。
- 部署:使用 LangServe 将任何链转换为 API。
2、LangChain 库
2.1 LangChain 包的主要价值
- 组件:用于处理语言模型的可组合工具和集成。无论你是否使用 LangChain 框架的其余部分,组件都是模块化的,易于使用
- 现成的链:用于完成高级任务的组件的内置组合
现成的链使得开始变得容易。组件使得定制现有链和构建新链变得容易。
2.2 LangChain 的核心组件
- langchain-core:基础抽象和 LangChain 表达式语言。
- langchain-community:第三方集成。
- langchain:构成应用程序认知架构的链、代理和检索策略。
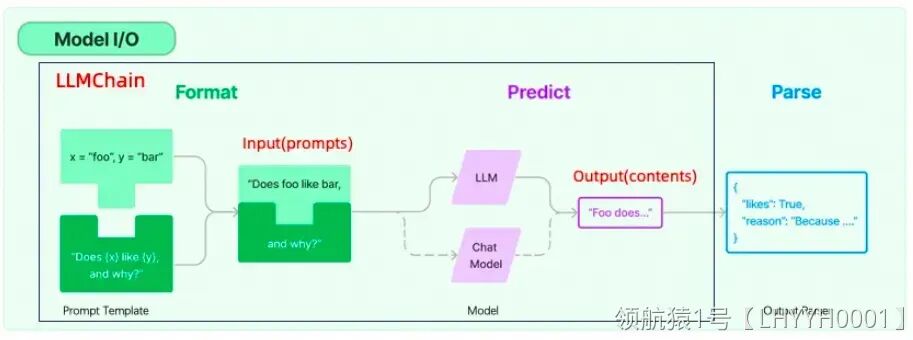
2.2.1 模型 I/O 封装
- LLMs(大语言模型)
这些模型是LangChain积木盒中的基础积木。如同用乐高搭建房屋的地基,LLMs为构建复杂的语言理解和生成任务提供了坚实的基础。
- Chat Models(聊天模型)
一般基于 LLMs,但按对话结构重新封装。这些模型就像是为你的乐高小人制作对话能力。它们能够让应用程序进行流畅的对话,好比是给你的乐高积木人注入了会说话的灵魂。
- PromptTemple(提示词模板)
想象一下,你正在给乐高小人编写剧本,告诉他们在不同场景下应该说什么。Prompt Templates就是这些剧本,它们指导模型如何回答问题或者生成文本。
- OutputParser:解析输出
2.2.2 数据连接封装
- Index(索引)
LangChain通过Indexs索引允许文档结构化,让LLM更直接、更有效地与文档互动。
- Document Loaders(文档加载器)
各种格式文件的加载器
- Document Transformers
对文档的常用操作,如:split, filter, translate, extract metadata, etc
- Text Embedding Models(文本嵌入模型)
如果说其他模型让积木能够理解和生成文本,文本嵌入模型则提供了理解文本深度含义的能力。它们就像是一种特殊的积木块,可以帮助其他积木更好地理解每个块应该放在哪里。
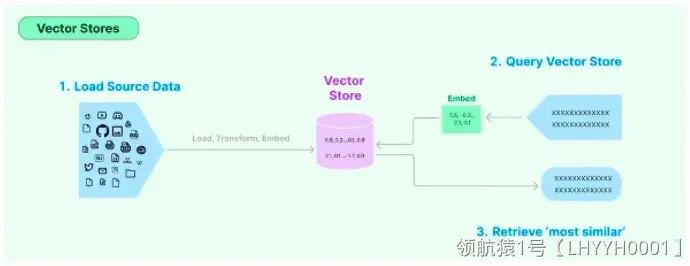
- Verctor Stores(面向检索的向量存储)
这些是一种特殊的存储设施,帮助你的乐高模型记住文本的数学表示(向量)。这就像是让积木块记住它们在整个结构中的位置。
- Retrievers(检索器)
想象一下你需要从一堆积木中找到一个特定的小部件。Retrievers能够快速在向量存储中检索和提取信息,就像是乐高世界里的搜索引擎。
2.2.3 Memory(记忆,对话的连贯性)
- 这里不是物理内存,从文本的角度,可以理解为“上文”、“历史记录”或者说“记忆力”的管理
- Chat Message History(聊天消息历史)
最常见的一种对话内容中的Memory类,这就好比是在你的乐高角色之间建立了一个记忆网络,使它们能够记住过去的对话,这样每次交流都能在之前的基础上继续,使得智能积木人能够在每次对话中保持连贯性。
2.2.4 架构封装(Agent & Chain)
2.2.4.1 Chain
-
分类:
Chain、
LLM Chain、Index-related Chains -
**概念:**实现一个功能或者一系列顺序功能组合,Chain 模块整合了大型语言模型、向量数据库、记忆系统及提示,通过Agents的能力拓展至各种工具,形成一个能够互相合作的独立模块网络。它不仅比大模型API更加高效,还增强了模型的各种应用,诸如问答、摘要编写、表格分析和代码理解等。
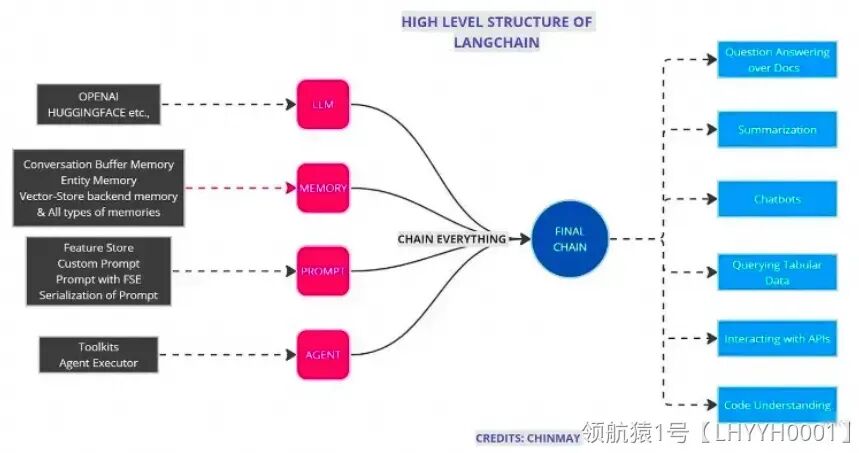
Chain是连接不同智能积木块的基本方式,而LLM Chain是最简单的 LLM+Prompts 的一种chain,专门用于链接语言模型。Index-related Chains 则将索引功能集成进来,确保信息的高效流动。
2.2.4.2 Agent(智能体)浅识
- 根据用户输入,自动规划执行步骤,自动选择每步需要的工具,最终完成用户指定的功能。
- 在LangChain的世界里,Agent是一个智能代理,它的任务是听取你的需求(用户输入)和分析当前的情境(应用场景),然后从它的工具箱(一系列可用工具)中选择最合适的工具来执行操作。这些工具箱里装的是 LangChain 提供的各种积木,比如 Models、Prompts、Indexes 等。
关于 Agent 智能体详细教程,请看下节课《3-4-7 Agent 智能体》
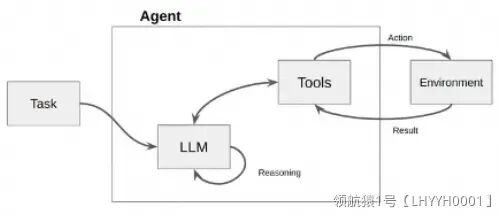
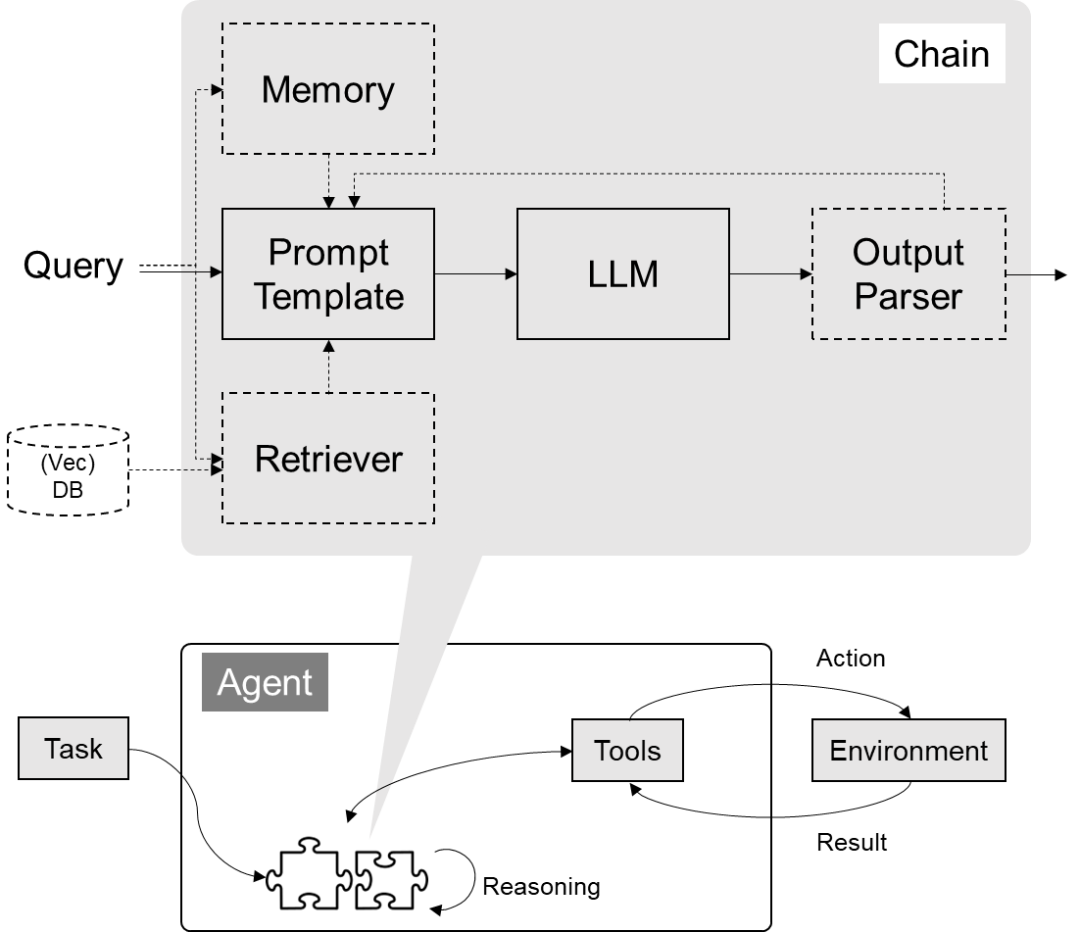
如下图所示,Agent接受一个任务,使用LLM(大型语言模型)作为它的“大脑”或“思考工具”,通过这个大脑来决定为了达成目标需要执行什么操作。它就像是一个有战略眼光的指挥官,不仅知道战场上的每个小队能做什么,还能指挥它们完成更复杂的任务。
LangChain 中 Agent 组件的架构图如下,本质上也是基于 Chain 实现,但是它是一种特殊的 Chain,这个 Chain 是对 Action 循环调用的过程,它使用的 PromptTemplate 主要是符合 Agent Type 要求的各种思考决策模版。Agent 的核心思想在于使用LLM进行决策,选择一系列要执行的动作,并以此驱动应用程序的核心逻辑。通过 Toolkits 中的一组特定工具,用户可以设计特定用例的应用。
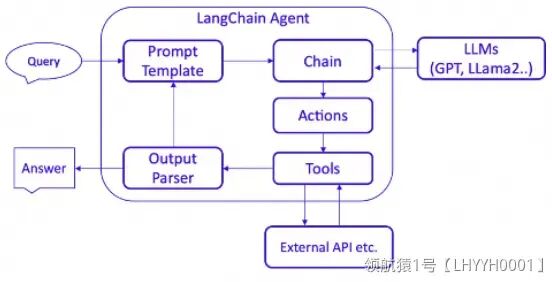
》》观察(Observation)
在这个阶段,代理通过其输入接口接收外部的触发,比如用户的提问或系统发出的请求。代理对这些输入进行解析,提取关键信息作为处理的基础。观察结果通常包括用户的原始输入或预处理后的数据。
》》思考(Thought)
在思考阶段,代理使用预先设定的规则、知识库或者利用机器学习模型来分析观察到的信息。这个阶段的目的是确定如何响应观察到的情况。代理可能会评估不同的行动方案,预测它们的结果,并选择最合适的答案或行为。
在 LangChain 中,这个过程可能涉及以下几个子步骤:
**1.理解用户意图:**使用NLP(自然语言处理)技术来理解用户的问题是什么。
**2.推断所需工具:**确定哪个工具(或工具组合)能解决用户的问题。
**3.提取参数:**提取所需工具运行的必要参数。这可能涉及文本解析、关键信息提取和验证等过程。
》》行动(Action)
根据思考阶段的结果,代理将执行特定的行动。行动可能是提供答案、执行任务、调用工具或者与用户进行进一步的交云。
在LangChain代理中,这通常涉及以下几个子步骤:
**1.参数填充:**将思考阶段提取的参数填入对应的工具函数中。
**2.工具执行:**运行工具,并获取执行结果。这可能是查询数据库、运行算法、调用API等。
**3.响应生成:**根据工具的执行结果构建代理的响应。响应可以是纯文本消息、数据、图像或其他格式。
4.**输出:**将生成的响应输出给用户或系统。
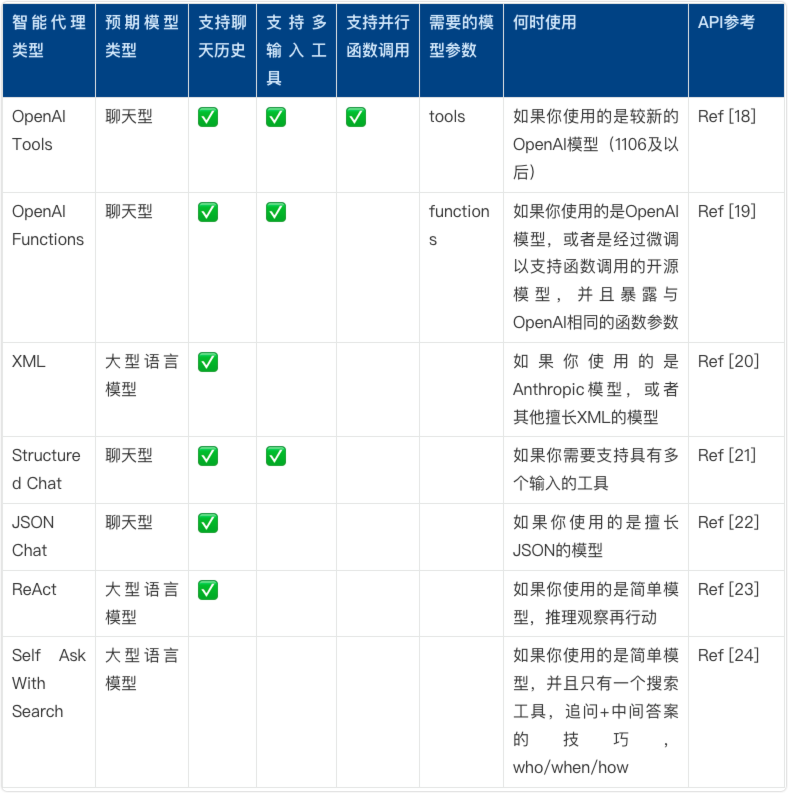
2.2.4.3 Agent推理方式:AgentType
代理类型决定了代理如何使用工具、处理输入以及与用户进行交互,就像给机器人挑选不同的大脑一样,我们有很多种"智能代理"可以根据需要来选择。有的代理是为聊天模型(接收消息,输出消息)设计的,可以支持聊天历史;有的代理更适合单一任务,是为大语言模型(接收字符串,输出字符串)而设计的。而且,这些代理的能力也不尽相同:有的能记住你之前的对话(支持聊天历史),有的能同时处理多个问题(支持并行函数调用),也有的只能专心做一件事(适用于单一任务)。此外,有些代理需要我们提供一些额外信息才能更好地工作(所需模型参数),而有些则可以直接上手,不需要额外的东西。所以,根据你的需求和你所使用的模型,你可以选择最合适的代理来帮你完成任务,常见的代理类型如下:
2.2.4.4 Agent与Chain的关系
如果说 Chain 是 LangChain 中的基础连接方式,那么 Agent 就是更高阶的版本,它不仅可以绑定模板和 LLM,还能够根据具体情况添加或调整使用的工具。简单来说,如果 Chain 是一条直线,那么 Agent就是能够在多个路口根据交通情况灵活选择路线的专业司机。
2.2.5 Callbacks
3、编程:手撕 LangChain
🎯 代码能力要求:中高,AI/数学基础要求:无
- 有编程基础的同学
- 关注设计思路,实现细节
- 没有编程基础的同学
- 尽量理解 SDK 的概念和价值,尝试体会使用 SDK 前后的差别与意义
3.1 模型 API:LLM vs ChatModel
🎯****关于代理地址与 api_key
如下演示中,我手动设置了代理地址 base_url 以及 api_key。这是我搭建的一个企业中转地址,支持 OpenAI、Deepseek、Claude、gemini、midjourney、文心一言、通义千问等众多模型,使用方便、稳定、价美。如果大家有需要可以私信我获取【LHYYH0001】
🎯****准备工作
- 先将 .env.templet 文件重命名为 .env 后配置你的 url 以及 key 即可。
- 你也可以直接创建 .env 然后配置:TONGYI_KEY、OPENAI_API_KEY、OPENAI_BASE_URL
pip install --upgrade langchain
pip install --upgrade langchain-openai
pip install --upgrade langchain-community
● 安装 doenv
○ pip install dotenv
○ 如果上面命令报错,请尝试:pip install python-dotenv
● 引入模块
import os
from dotenv import load_dotenv, find_dotenv
_ = load_dotenv(find_dotenv())
3.1.1 LangChain 调用 OpenAI Chat 接口
import os
from dotenv import load_dotenv, find_dotenv
_ = load_dotenv(find_dotenv())
from langchain_openai import ChatOpenAI
# 在 .env 文件中配置你的 url 以及 key 即可
api_key = os.getenv('OPENAI_API_KEY')
base_url = os.getenv('OPENAI_BASE_URL')
llm = ChatOpenAI(model="gpt-4o",
temperature=0,
max_tokens=None,
timeout=None,
max_retries=2,
api_key=api_key,
base_url=base_url)
response = llm.invoke("你是谁")
# 我是一个由OpenAI开发的人工智能助手,旨在帮助回答问题、提供信息和协助完成各种任务。你可以问我任何问题,我会尽力提供有用的回答。有什么我可以帮你的吗?
print(response.content)
3.1.2 多轮对话 session 封装
import os
from dotenv import load_dotenv, find_dotenv
_ = load_dotenv(find_dotenv())
from langchain_openai import ChatOpenAI
# 在 .env 文件中配置你的 url 以及 key 即可
api_key = os.getenv('OPENAI_API_KEY')
base_url = os.getenv('OPENAI_BASE_URL')
llm = ChatOpenAI(model="gpt-4o",
temperature=0,
max_tokens=None,
timeout=None,
max_retries=2,
api_key=api_key,
base_url=base_url)
from langchain.schema import (
AIMessage, # 等价于OpenAI接口中的assistant role
HumanMessage, # 等价于OpenAI接口中的user role
SystemMessage # 等价于OpenAI接口中的system role
)
messages = [
SystemMessage(content="你是AGIClass的课程助理。"),
HumanMessage(content="我是学员,我叫王卓然。"),
AIMessage(content="欢迎!"),
HumanMessage(content="我是谁")
]
ret = llm.invoke(messages)
print(ret.content)
3.1.3 LangChain 调用国产文心一言模型
🎯 其它模型分装在 langchain_community 底包中
📌 如下是文心一言与通义千问的调用示例
# 其它模型分装在 langchain_community 底包中
from langchain_community.chat_models import QianfanChatEndpoint
from langchain_core.messages import HumanMessage
import os
from dotenv import load_dotenv, find_dotenv
_ = load_dotenv(find_dotenv())
ERNIE_CLIENT_ID={你的ERNIE_CLIENT_ID}
ERNIE_CLIENT_SECRET={你的ERNIE_CLIENT_SECRET}
llm = QianfanChatEndpoint(
qianfan_ak=ERNIE_CLIENT_ID,
qianfan_sk=ERNIE_CLIENT_SECRET
)
messages = [
HumanMessage(content="介绍一下你自己")
]
ret = llm.invoke(messages)
print(ret.content)
LangChain 中不支持企业转发,需要使用通义千问官方的 key
import os
from dotenv import load_dotenv, find_dotenv
_ = load_dotenv(find_dotenv())
# 其它模型分装在 langchain_community 底包中
from langchain_community.chat_models import ChatTongyi
# LangChain 中不支持企业转发,需要使用通义千问官方的 key
TONGYI_KEY = os.getenv('TONGYI_KEY')
tongyi_chat = ChatTongyi(
api_key=TONGYI_KEY
)
messages = [
("system", "你是「AI大模型全栈通识课」的课程助理。你叫AGI舰长。微信号:LHYYH0001"),
("human", "你是谁?"),
]
ai_msg = tongyi_chat.invoke(messages)
print(ai_msg.content)
3.2 Prompt 模版封装
**🎯****划重点:**把Prompt模板看作带有参数的函数
如下代码我拆成了三段,开源课件源码中对应的是 langchain_002.py
3.2.1 PromptTemplate 可以在模板中自定义变量
import os
from dotenv import load_dotenv, find_dotenv
_ = load_dotenv(find_dotenv())
from langchain.prompts import PromptTemplate
from langchain_openai import ChatOpenAI
from langchain_core.messages import AIMessage, HumanMessage
############################# 1、PromptTemplate 模版 #############################
# 1.1 模版的原理
template = PromptTemplate.from_template("给我讲个关于{subject}的笑话")
print("===Template===")
print(template)
print("===Prompt===")
print(template.format(subject='小明'))
# 1.2 调用大模型
api_key = os.getenv('OPENAI_API_KEY')
base_url = os.getenv('OPENAI_BASE_URL')
# 定义 LLM
llm = ChatOpenAI(api_key=api_key,base_url=base_url)
# 通过 Prompt 调用 LLM
ret = llm.invoke(template.format(subject='小明'))
# 打印输出
print("===调用大模型效果===")
print(ret.content)
效果
3.2.2 ChatPromptTemplate 用模板表示的对话上下文
import os
from dotenv import load_dotenv, find_dotenv
_ = load_dotenv(find_dotenv())
from langchain.prompts import PromptTemplate
from langchain_openai import ChatOpenAI
from langchain_core.messages import AIMessage, HumanMessage
############################# 2、ChatPromptTemplate 用模板表示的对话上下文 #############################
from langchain.prompts import (
ChatPromptTemplate,
HumanMessagePromptTemplate,
SystemMessagePromptTemplate,
MessagesPlaceholder,
HumanMessagePromptTemplate,
MessagesPlaceholder,
)
api_key = os.getenv('OPENAI_API_KEY')
base_url = os.getenv('OPENAI_BASE_URL')
# 定义 LLM
llm = ChatOpenAI(api_key=api_key,base_url=base_url)
template = ChatPromptTemplate.from_messages(
[
SystemMessagePromptTemplate.from_template(
"你是{product}的客服助手。你的名字叫{name}"),
HumanMessagePromptTemplate.from_template("{query}"),
]
)
llm = ChatOpenAI()
prompt = template.format_messages(
product="AI大模型全栈通识课",
name="AGI舰长",
query="你是谁"
)
print("\n\n =======对话上下文 prompt=======\n", prompt)
ret = llm.invoke(prompt)
print(ret.content)
效果
3.2.3 MessagesPlaceholder 把多轮对话变成模板
import os
from dotenv import load_dotenv, find_dotenv
_ = load_dotenv(find_dotenv())
from langchain.prompts import PromptTemplate
from langchain_openai import ChatOpenAI
from langchain_core.messages import AIMessage, HumanMessage
############################# 2、ChatPromptTemplate 用模板表示的对话上下文 #############################
from langchain.prompts import (
ChatPromptTemplate,
HumanMessagePromptTemplate,
SystemMessagePromptTemplate,
MessagesPlaceholder,
HumanMessagePromptTemplate,
MessagesPlaceholder,
)
api_key = os.getenv('OPENAI_API_KEY')
base_url = os.getenv('OPENAI_BASE_URL')
# 定义 LLM
llm = ChatOpenAI(api_key=api_key,base_url=base_url)
############################# 2、MessagesPlaceholder 把多轮对话变成模板 #############################
# 3.1 模版设定
human_prompt = "将你的回答翻译成 {language}."
human_message_template = HumanMessagePromptTemplate.from_template(human_prompt)
chat_prompt = ChatPromptTemplate.from_messages(
[MessagesPlaceholder("history"), human_message_template]
)
# 3.2 模版转换
human_message = HumanMessage(content="Who is Elon Musk?")
ai_message = AIMessage(
content="Elon Musk is a billionaire entrepreneur, inventor, and industrial designer"
)
messages = chat_prompt.format_prompt(
# 对 "history" 和 "language" 赋值
history=[human_message, ai_message], language="中文"
)
print('\n\n模版转换后的 prompt ===\n', messages.to_messages())
# 3.3 请求大模型
result = llm.invoke(messages)
print('大模型返回结果 =====\n', result.content)
效果

3.2.4 从文件加载 Prompt 模板
- 本地新建一个文件
本地文件.txt,内容如下
AI大模型全栈通识教程-适宜人群
🎓 学历要求:高中及以上学历
👍 偷偷的努力,然后惊艳所有人!
🎓 做懂业务,懂开发,懂AI;会使用,会微调,会绘画的三懂三会人才,成为中国第一批AI大模型全栈工程师
🙋 专业人士,可以不学; 小白/基础薄弱的,建议都来学!
● 中年职场人:职业发展陷入瓶颈,降薪、裁员,渴望破局
● 初入职场人:找工作困难,渴望挑战高薪,提升职场竞争力
● 家庭主妇/宝妈/失业人群:时间充裕,寻求简单的副业机会
● 企业家:有公司,人力成本高,产出低,需要降本增效
● 青少年:培养青少年 AI 兴趣与创造力,树立良好启蒙
作者:AGI舰长
教程介绍:https://www.yuque.com/lhyyh/agi/introduce
- 代码执行
############################# 3、从文件加载 Prompt 模板 #############################
template = PromptTemplate.from_file("本地文件.txt")
print("\n\n===Template===")
print(template)
print("===Prompt===")
print(template.format(topic='AI大模型全栈通识教程-适宜人群'))
- 效果
3.3 RAG必用技术:文档处理向量检索
3.3.1 文档加载器 Document Loaders
import os
from dotenv import load_dotenv, find_dotenv
_ = load_dotenv(find_dotenv())
from langchain_openai import ChatOpenAI
from langchain_community.document_loaders import PyMuPDFLoader
############################# 1、PromptTemplate 模版 #############################
# 1.2 调用大模型
api_key = os.getenv('OPENAI_API_KEY')
base_url = os.getenv('OPENAI_BASE_URL')
# 定义 LLM
llm = ChatOpenAI(api_key=api_key,base_url=base_url)
# pip install fitz pymupdf
loader = PyMuPDFLoader("AI大模型全栈通识课介绍.pdf")
pages = loader.load_and_split()
print(pages[0].page_content)
3.3.2 文档处理器 TextSplitter
🎯****类似 LlamaIndex,LangChain 也提供了丰富的文档处理工具:
-
Document****Loaders:
https://python.langchain.com/v0.2/docs/how_to/#document-loaders
-
Text Splitters:
https://python.langchain.com/v0.2/docs/how_to/#text-splitters
pip install --upgrade langchain-text-splitters
from langchain_text_splitters import RecursiveCharacterTextSplitter
# 初始化RecursiveCharacterTextSplitter文本分隔器
# 设置分隔器的参数,用于控制文本分割的行为
text_splitter = RecursiveCharacterTextSplitter(
# 每个文本块的最大大小为200个字符
chunk_size=200,
# 文本块之间的重叠大小为100个字符,确保上下文的连贯性
chunk_overlap=100,
# 使用len函数计算文本长度
length_function=len,
# 在每个文本块的开始位置添加索引,便于后续处理时定位信息源
add_start_index=True,
)
paragraphs = text_splitter.create_documents([pages[0].page_content])
for para in paragraphs:
print(para.page_content)
print('-------')
3.3.3 向量数据库与向量检索
- 更多的三方检索组件链接参考
https://python.langchain.com/v0.2/docs/integrations/vectorstores/
from langchain_openai import OpenAIEmbeddings
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_community.vectorstores import FAISS
from langchain_openai import ChatOpenAI
from langchain_community.document_loaders import PyMuPDFLoader
# 加载文档
loader = PyMuPDFLoader("AI大模型全栈通识课介绍.pdf")
pages = loader.load_and_split()
# 文档切分
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=300,
chunk_overlap=100,
length_function=len,
add_start_index=True,
)
texts = text_splitter.create_documents(
[page.page_content for page in pages[:4]]
)
# 灌库
embeddings = OpenAIEmbeddings(model="text-embedding-ada-002")
db = FAISS.from_documents(texts, embeddings)
# 检索 top-3 结果
retriever = db.as_retriever(search_kwargs={"k": 3})
docs = retriever.invoke("llama2有多少参数")
for doc in docs:
print(doc.page_content)
print("----")
4、LangServe & LangChain.js【选】
4.1 LangServe
**🎯****定义:**LangServe 用于将 Chain 或者 Runnable 部署成一个 REST API 服务。
pip install --upgrade "langserve[all]"
# 也可以只安装一端
pip install "langserve[client]"
pip install "langserve[server]"
# server 端
#!/usr/bin/env python
from fastapi import FastAPI
from langchain.prompts import ChatPromptTemplate
from langchain_openai import ChatOpenAI
from langserve import add_routes
import uvicorn
app = FastAPI(
title="LangChain Server",
version="1.0",
description="A simple api server using Langchain's Runnable interfaces",
)
model = ChatOpenAI()
prompt = ChatPromptTemplate.from_template("讲一个关于{topic}的笑话")
add_routes(
app,
prompt | model,
path="/joke",
)
if __name__ == "__main__":
uvicorn.run(app, host="localhost", port=9999)
# client 端
import requests
response = requests.post(
"http://localhost:9999/joke/invoke",
json={'input': {'topic': '小明'}}
)
print(response.json())
4.2 LangChain.js
Python 版 LangChain 的姊妹项目,都是由 Harrison Chase 主理。
-
项目地址
https://github.com/langchain-ai/langchainjs
-
文档地址
https://js.langchain.com/docs/
-
特色:
- 可以和 Python 版 LangChain 无缝对接
- 抽象设计完全相同,概念一一对应
- 所有对象序列化后都能跨语言使用,但 API 差别挺大,不过在努力对齐
- 支持环境:
- Node.js (ESM and CommonJS) - 18.x, 19.x, 20.x
- Cloudflare Workers
- Vercel / Next.js (Browser, Serverless and Edge functions)
- Supabase Edge Functions
- Browser
- Deno
- 安装:
npm install langchain
4.3 LangChain 与 LlamaIndex 的错位竞争
- LangChain 侧重与 LLM 本身交互的封装
- Prompt、LLM、Message、OutputParser 等工具丰富
- 在数据处理和 RAG 方面提供的工具相对粗糙
- 主打 LCEL 流程封装
- 配套 Agent、LangGraph 等智能体与工作流工具
- 另有 LangServe 部署工具和 LangSmith 监控调试工具
- LlamaIndex 侧重与数据交互的封装
- 数据加载、切割、索引、检索、排序等相关工具丰富
- Prompt、LLM 等底层封装相对单薄
- 配套实现 RAG 相关工具
- 有 Agent 相关工具,不突出
- LlamaIndex 为 LangChain 提供了集成
- 在 LlamaIndex 中调用 LangChain 封装的 LLM 接口
https://docs.llamaindex.ai/en/stable/api_reference/llms/langchain/ - 将 LlamaIndex 的 Query Engine 作为 LangChain Agent 的工具
https://docs.llamaindex.ai/en/v0.10.17/community/integrations/using_with_langchain.html - LangChain 也 曾经 集成过 LlamaIndex,目前相关接口仍在
https://api.python.langchain.com/en/latest/retrievers/langchain_community.retrievers.llama_index.LlamaIndexRetriever.html
过几天更新 Langchain v1.0 版本变化,感兴趣小伙伴可以点个关注~
想入门 AI 大模型却找不到清晰方向?备考大厂 AI 岗还在四处搜集零散资料?别再浪费时间啦!2025 年 AI 大模型全套学习资料已整理完毕,从学习路线到面试真题,从工具教程到行业报告,一站式覆盖你的所有需求,现在全部免费分享!
👇👇扫码免费领取全部内容👇👇

一、学习必备:100+本大模型电子书+26 份行业报告 + 600+ 套技术PPT,帮你看透 AI 趋势
想了解大模型的行业动态、商业落地案例?大模型电子书?这份资料帮你站在 “行业高度” 学 AI:
1. 100+本大模型方向电子书

2. 26 份行业研究报告:覆盖多领域实践与趋势
报告包含阿里、DeepSeek 等权威机构发布的核心内容,涵盖:

- 职业趋势:《AI + 职业趋势报告》《中国 AI 人才粮仓模型解析》;
- 商业落地:《生成式 AI 商业落地白皮书》《AI Agent 应用落地技术白皮书》;
- 领域细分:《AGI 在金融领域的应用报告》《AI GC 实践案例集》;
- 行业监测:《2024 年中国大模型季度监测报告》《2025 年中国技术市场发展趋势》。
3. 600+套技术大会 PPT:听行业大咖讲实战
PPT 整理自 2024-2025 年热门技术大会,包含百度、腾讯、字节等企业的一线实践:

- 安全方向:《端侧大模型的安全建设》《大模型驱动安全升级(腾讯代码安全实践)》;
- 产品与创新:《大模型产品如何创新与创收》《AI 时代的新范式:构建 AI 产品》;
- 多模态与 Agent:《Step-Video 开源模型(视频生成进展)》《Agentic RAG 的现在与未来》;
- 工程落地:《从原型到生产:AgentOps 加速字节 AI 应用落地》《智能代码助手 CodeFuse 的架构设计》。
二、求职必看:大厂 AI 岗面试 “弹药库”,300 + 真题 + 107 道面经直接抱走
想冲字节、腾讯、阿里、蔚来等大厂 AI 岗?这份面试资料帮你提前 “押题”,拒绝临场慌!

1. 107 道大厂面经:覆盖 Prompt、RAG、大模型应用工程师等热门岗位
面经整理自 2021-2025 年真实面试场景,包含 TPlink、字节、腾讯、蔚来、虾皮、中兴、科大讯飞、京东等企业的高频考题,每道题都附带思路解析:

2. 102 道 AI 大模型真题:直击大模型核心考点
针对大模型专属考题,从概念到实践全面覆盖,帮你理清底层逻辑:

3. 97 道 LLMs 真题:聚焦大型语言模型高频问题
专门拆解 LLMs 的核心痛点与解决方案,比如让很多人头疼的 “复读机问题”:

三、路线必明: AI 大模型学习路线图,1 张图理清核心内容
刚接触 AI 大模型,不知道该从哪学起?这份「AI大模型 学习路线图」直接帮你划重点,不用再盲目摸索!

路线图涵盖 5 大核心板块,从基础到进阶层层递进:一步步带你从入门到进阶,从理论到实战。

L1阶段:启航篇丨极速破界AI新时代
L1阶段:了解大模型的基础知识,以及大模型在各个行业的应用和分析,学习理解大模型的核心原理、关键技术以及大模型应用场景。

L2阶段:攻坚篇丨RAG开发实战工坊
L2阶段:AI大模型RAG应用开发工程,主要学习RAG检索增强生成:包括Naive RAG、Advanced-RAG以及RAG性能评估,还有GraphRAG在内的多个RAG热门项目的分析。

L3阶段:跃迁篇丨Agent智能体架构设计
L3阶段:大模型Agent应用架构进阶实现,主要学习LangChain、 LIamaIndex框架,也会学习到AutoGPT、 MetaGPT等多Agent系统,打造Agent智能体。

L4阶段:精进篇丨模型微调与私有化部署
L4阶段:大模型的微调和私有化部署,更加深入的探讨Transformer架构,学习大模型的微调技术,利用DeepSpeed、Lamam Factory等工具快速进行模型微调,并通过Ollama、vLLM等推理部署框架,实现模型的快速部署。

L5阶段:专题集丨特训篇 【录播课】

四、资料领取:全套内容免费抱走,学 AI 不用再找第二份
不管你是 0 基础想入门 AI 大模型,还是有基础想冲刺大厂、了解行业趋势,这份资料都能满足你!
现在只需按照提示操作,就能免费领取:
👇👇扫码免费领取全部内容👇👇
2025 年想抓住 AI 大模型的风口?别犹豫,这份免费资料就是你的 “起跑线”!

















8000 字精心打磨&spm=1001.2101.3001.5002&articleId=155389061&d=1&t=3&u=d58cee3f74154bba93b9cd98e808276e)
 1194
1194

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









