 大模型选型:本地vs云端
大模型选型:本地vs云端




在 AI 应用快速落地的今天,大模型已成为企业智能化转型的核心引擎。然而,面对“本地部署 Llama3/Qwen”与“调用 GPT-4/Claude 云 API”两条路径,技术决策者常陷入两难:既要高性能、低延迟,又要控制成本、满足数据合规。本文将从性能、成本、安全、运维复杂度四个维度,系统对比两种方案,并给出可落地的混合架构建议,帮助 CTO 和技术负责人做出理性选择。
一、云 API:开箱即用,但代价不菲
主流云大模型如 OpenAI 的 GPT-4、Anthropic 的 Claude,凭借卓越的语言理解与生成能力,成为许多企业的首选。
优势:
- 开箱即用:无需训练、部署、调优,一行代码即可接入。
- 持续进化:模型自动更新,始终使用最新版本。
- 高可用性:SLA 保障,无需自建容灾与监控体系。
劣势:
- 成本高昂:以 GPT-4 Turbo 为例,输入0.01/千 token,输出0.03/千 token,若日均调用量达 100 万 token,月成本轻松突破 $900+。
- 数据出境风险:用户输入可能经由境外服务器处理,违反《数据安全法》《个人信息保护法》,尤其在金融、政务、医疗等强监管行业不可接受。
- 不可控性:无法定制模型行为,也无法保证响应延迟(受网络与 API 队列影响)。
结论:适合非敏感场景、原型验证或低频调用,但长期规模化应用需谨慎。
二、本地部署:自主可控,但门槛较高
将 Llama3-8B、Qwen-7B/14B 等开源模型部署在私有 GPU 集群,已成为越来越多企业的选择。
优势:
- 数据不出域:所有推理在内网完成,100% 满足合规要求。
- 成本可预测:一次性硬件投入,后续仅电费与运维成本。
- 高度可定制:可微调、蒸馏、插件化,适配业务专属场景(如 RAG、Agent 控制平面)。
劣势:
- 硬件门槛高:Llama3-8B 全精度需 16GB+ 显存,若需并发服务,通常需 8×A10(24GB)或 2×A100。
- 运维复杂:需自行处理模型加载、量化、批处理、监控告警等。
- 性能调优难:默认推理速度慢,需借助专业推理框架优化。
关键提示:通过量化(如 GGUF 格式) 和连续批处理(Continuous Batching),可显著降低显存占用并提升吞吐。
三、推理框架横评:vLLM、llama.cpp、Ollama、TGI 谁更胜一筹?
| 框架 | 适用场景 | 量化支持 | 并发能力 | 易用性 | GPU 利用率 |
| vLLM | 高并发生产环境 | ✅(AWQ) | ⭐⭐⭐⭐⭐ | 中 | 极高(PagedAttention) |
| TGI(Text Generation Inference) | HuggingFace 生态 | ✅(bitsandbytes) | ⭐⭐⭐⭐ | 中 | 高 |
| llama.cpp | CPU/低配 GPU | ✅(GGUF) | ⭐⭐ | 高 | 低(CPU 为主) |
| Ollama | 本地开发/测试 | ✅(GGUF) | ⭐ | 极高 | 一般 |
推荐组合:
- 生产环境:vLLM + Llama3-8B-AWQ(4-bit 量化),兼顾速度与显存。
- 边缘/低配设备:llama.cpp + GGUF 4-bit,可在 6GB 显存设备运行 7B 模型。
- 快速验证:Ollama 一行命令启动,适合原型开发。
四、成本模型对比:云 vs 本地,谁更划算?
我们以 日均 200 万 token 处理量 为基准进行测算:
云 API 成本(GPT-4 Turbo):
- 输入:2M × 0.01/1k = 20/天
- 输入:2M × 0.03/1k = 20/天
- 月成本 ≈ $2400
本地部署成本(8×NVIDIA A10):
- A10 单卡月租(云厂商):约 ¥8000(≈$1100)
- 8 卡月成本:≈ $8800(一次性投入或长期租赁)
- 但注意:A10 可支撑 日均 5000 万+ token 推理(vLLM 优化后),单位 token 成本远低于云 API。
临界点分析:当日均 token > 50 万,本地部署成本开始低于云 API;> 100 万,优势显著。
五、混合架构:兼顾安全与效率的最佳实践
对于多数企业,“敏感数据走本地,通用问题走云” 是最优解。下图展示了典型的混合推理流程:
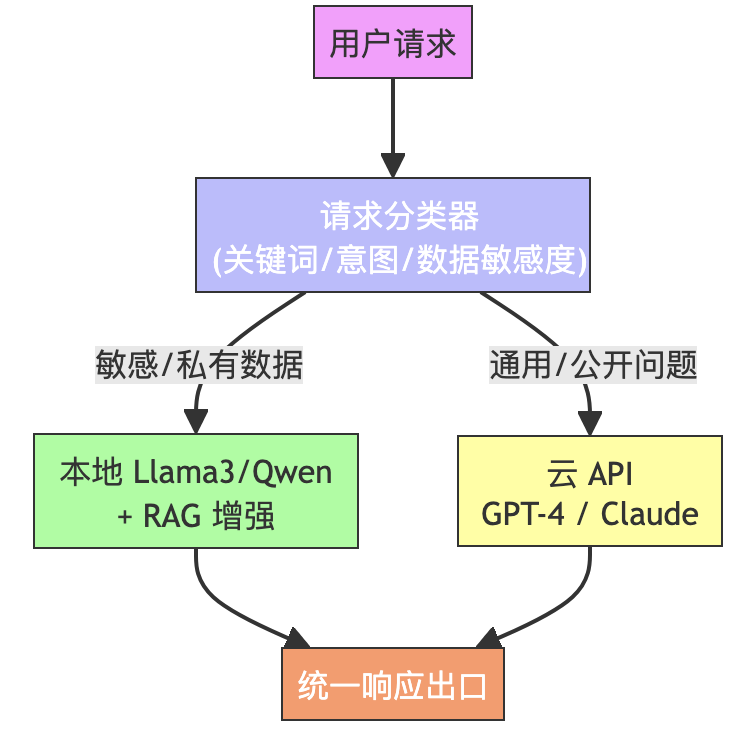
典型场景:
- 用户问:“我的订单状态?” → 本地模型 + RAG 查询内部数据库
- 用户问:“巴黎有哪些景点?” → 调用 GPT-4 获取最新旅游信息
此架构既保障核心数据安全,又利用云模型的广博知识,实现成本与能力的帕累托最优。
六、实战示例:用 vLLM 部署 Llama3-8B 并接入 RAG
以下为简化部署流程(假设已安装 CUDA 和 vLLM):
# 1. 安装 vLLMpip install vllm# 2. 下载量化模型(HuggingFace)# 推荐使用 TheBloke/Llama-3-8B-AWQ# 3. 启动推理服务python -m vllm.entrypoints.api_server \ --model TheBloke/Llama-3-8B-AWQ \ --quantization awq \ --dtype float16 \ --max-model-len 4096# 4. 接入 RAG# 在业务层:先向向量库(如 Milvus)检索相关文档,# 将文档拼接为 prompt,再调用本地 vLLM 接口
通过 vLLM 的 PagedAttention 和 Continuous Batching,单卡 A10 可实现 >50 tokens/s 的吞吐,支持数十并发请求。
七、总结:没有银弹,只有权衡
| 维度 | 云 API | 本地部署 |
| 性能 | 高(但受网络影响) | 可优化至极高 |
| 成本 | 高(随用量线性增长) | 前期高,长期低 |
| 合规 | 风险高 | 100% 可控 |
| 运维 | 无 | 需专业团队 |
建议策略:
- 初创公司/POC 阶段:优先使用云 API 快速验证。
- 中大型企业/强合规场景:必须构建本地推理能力,并采用混合架构。
- 长期主义团队:投资 vLLM + Llama3/Qwen 技术栈,掌握 AI 自主权。
最后提醒:大模型选型不是技术问题,而是战略问题。选择哪条路,决定了你未来三年在 AI 时代的主动权。
延伸阅读:
- vLLM 官方文档:https://vllm.readthedocs.io
- GGUF 量化指南:https://github.com/ggerganov/llama.cpp
- 《RAG 工程化实践:从向量检索到大模型融合》
想入门 AI 大模型却找不到清晰方向?备考大厂 AI 岗还在四处搜集零散资料?别再浪费时间啦!2025 年 AI 大模型全套学习资料已整理完毕,从学习路线到面试真题,从工具教程到行业报告,一站式覆盖你的所有需求,现在全部免费分享!
👇👇扫码免费领取全部内容👇👇

一、学习必备:100+本大模型电子书+26 份行业报告 + 600+ 套技术PPT,帮你看透 AI 趋势
想了解大模型的行业动态、商业落地案例?大模型电子书?这份资料帮你站在 “行业高度” 学 AI:
1. 100+本大模型方向电子书

2. 26 份行业研究报告:覆盖多领域实践与趋势
报告包含阿里、DeepSeek 等权威机构发布的核心内容,涵盖:

- 职业趋势:《AI + 职业趋势报告》《中国 AI 人才粮仓模型解析》;
- 商业落地:《生成式 AI 商业落地白皮书》《AI Agent 应用落地技术白皮书》;
- 领域细分:《AGI 在金融领域的应用报告》《AI GC 实践案例集》;
- 行业监测:《2024 年中国大模型季度监测报告》《2025 年中国技术市场发展趋势》。
3. 600+套技术大会 PPT:听行业大咖讲实战
PPT 整理自 2024-2025 年热门技术大会,包含百度、腾讯、字节等企业的一线实践:

- 安全方向:《端侧大模型的安全建设》《大模型驱动安全升级(腾讯代码安全实践)》;
- 产品与创新:《大模型产品如何创新与创收》《AI 时代的新范式:构建 AI 产品》;
- 多模态与 Agent:《Step-Video 开源模型(视频生成进展)》《Agentic RAG 的现在与未来》;
- 工程落地:《从原型到生产:AgentOps 加速字节 AI 应用落地》《智能代码助手 CodeFuse 的架构设计》。
二、求职必看:大厂 AI 岗面试 “弹药库”,300 + 真题 + 107 道面经直接抱走
想冲字节、腾讯、阿里、蔚来等大厂 AI 岗?这份面试资料帮你提前 “押题”,拒绝临场慌!

1. 107 道大厂面经:覆盖 Prompt、RAG、大模型应用工程师等热门岗位
面经整理自 2021-2025 年真实面试场景,包含 TPlink、字节、腾讯、蔚来、虾皮、中兴、科大讯飞、京东等企业的高频考题,每道题都附带思路解析:

2. 102 道 AI 大模型真题:直击大模型核心考点
针对大模型专属考题,从概念到实践全面覆盖,帮你理清底层逻辑:

3. 97 道 LLMs 真题:聚焦大型语言模型高频问题
专门拆解 LLMs 的核心痛点与解决方案,比如让很多人头疼的 “复读机问题”:

三、路线必明: AI 大模型学习路线图,1 张图理清核心内容
刚接触 AI 大模型,不知道该从哪学起?这份「AI大模型 学习路线图」直接帮你划重点,不用再盲目摸索!

路线图涵盖 5 大核心板块,从基础到进阶层层递进:一步步带你从入门到进阶,从理论到实战。

L1阶段:启航篇丨极速破界AI新时代
L1阶段:了解大模型的基础知识,以及大模型在各个行业的应用和分析,学习理解大模型的核心原理、关键技术以及大模型应用场景。

L2阶段:攻坚篇丨RAG开发实战工坊
L2阶段:AI大模型RAG应用开发工程,主要学习RAG检索增强生成:包括Naive RAG、Advanced-RAG以及RAG性能评估,还有GraphRAG在内的多个RAG热门项目的分析。

L3阶段:跃迁篇丨Agent智能体架构设计
L3阶段:大模型Agent应用架构进阶实现,主要学习LangChain、 LIamaIndex框架,也会学习到AutoGPT、 MetaGPT等多Agent系统,打造Agent智能体。

L4阶段:精进篇丨模型微调与私有化部署
L4阶段:大模型的微调和私有化部署,更加深入的探讨Transformer架构,学习大模型的微调技术,利用DeepSpeed、Lamam Factory等工具快速进行模型微调,并通过Ollama、vLLM等推理部署框架,实现模型的快速部署。

L5阶段:专题集丨特训篇 【录播课】

四、资料领取:全套内容免费抱走,学 AI 不用再找第二份
不管你是 0 基础想入门 AI 大模型,还是有基础想冲刺大厂、了解行业趋势,这份资料都能满足你!
现在只需按照提示操作,就能免费领取:
👇👇扫码免费领取全部内容👇👇
2025 年想抓住 AI 大模型的风口?别犹豫,这份免费资料就是你的 “起跑线”!

















 2070
2070

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









