



一、什么 是LLaMA Factory
LLaMA Factory 是一个简单易用且高效的大型语言模型(Large Language Model)训练与微调平台,是一款专为大型语言模型(LLM)微调而设计的工具集。
它基于Facebook的LLaMA(Large Language Model Meta AI)模型,提供了从数据处理、模型训练到部署的一站式解决方案。LLaMA Factory的核心理念是简化大模型微调的复杂度,使更多开发者能够轻松定制和优化自己的语言模型。

-
可微调的模型种类:LLaMA、LLaVA、Mistral、Mixtral-MoE、Qwen、Yi、Gemma、Baichuan、ChatGLM、Phi 等100+种。
-
训练算法:(增量)预训练、(多模态)指令监督微调、奖励模型训练、PPO 训练、DPO 训练、KTO 训练、ORPO 训练等等。
-
运算精度:16 比特全参数微调、冻结微调、LoRA 微调和基于 AQLM/AWQ/GPTQ/LLM.int8/HQQ/EETQ 的 2/3/4/5/6/8 比特 QLoRA 微调。
-
优化算法:GaLore、BAdam、DoRA、LongLoRA、LLaMA Pro、Mixture-of-Depths、LoRA+、LoftQ 和 PiSSA。
-
加速算子:FlashAttention-2 和 Unsloth。
-
推理引擎:Transformers 和 vLLM。
-
实验监控:LlamaBoard、TensorBoard、Wandb、MLflow、SwanLab 等等。
二、如何安装LLaMA Factory
一、系统要求与硬件适配
1. 硬件配置建议
| 模型规模 | 最低配置(单卡) | 推荐配置(多卡) |
|---|---|---|
| 7B | RTX 3090(24GB) | RTX 4090(24GB) |
| 13B | A10(24GB) | A100(40GB) |
| 30B+ | A100(80GB) | 多卡集群(NVLink 互联) |
| 特殊硬件 | 昇腾 910B (需安装 CANN 8.0+) | Apple M1/M2 (支持 7B 模型) |
2. 操作系统支持
- Linux(推荐):Ubuntu 22.04 LTS 或 CentOS 8
- macOS:13.0+(需启用 Metal 加速)
- Windows:11(需安装 WSL2 或 Docker)
二、安装LLaMA Factory
1.从https://github.com/hiyouga/LLaMA-Factory,将源码下载到本地安装
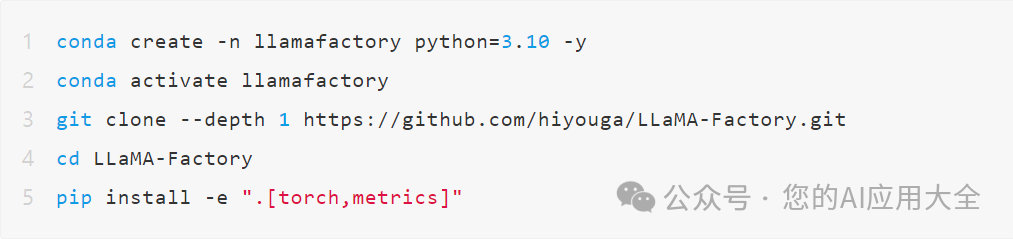
在根目录启动webui。记住一定要在LLaMA Factory的根目录启动。

默认启动的端口是7860 。

三、大模型微调入门
1.选择一个大模型
我们下载 Qwen1.5-7B-Chat到本地,对该模型进行微调训练。
#模型下载
from modelscope import snapshot_download
model_dir = snapshot_download(‘Qwen/Qwen2.5-7B-Chat’,cache_dir=“/root/autodl-tmp/llm”)
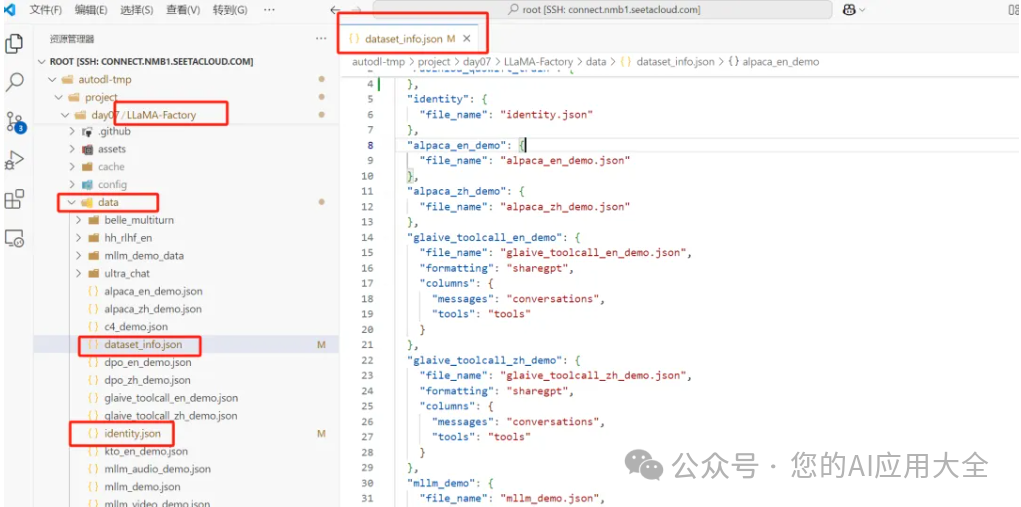
2.选择一个数据集
LLaMA Factory的源码里默认提供了很多种可直接训练的数据集,在data目录下。我们就拿identity.json身份认知训练集来做微调,将里面的占位符替换成合适的文字,并且保存。
3.指令监督微调数据集介绍
核心要素
- 三位一体结构(指令-输入-输出):****{ “instruction”: “将以下文本分类为正面/负面情感”, “input”: “这部电影太精彩了”, “output”: “正面”}
- 质量要求:
- 指令多样性(开放/封闭/推理/创作类)
- 输出需准确且符合人类表达习惯
-
数据增强技巧
from transformers import pipelinegenerator = pipeline(“text-generation”, model=“gpt-3.5-turbo”) def augment_data(example): prompt = f"请生成与以下指令相似的5个新指令:{example[‘instruction’]}" new_instructions = generator(prompt, max_length=500) return {“augmented”: new_instructions}
4.微调实操
步骤1:环境准备
git clone https://github.com/hiyouga/LLaMA-Factory.gitpip install -e .[bitsandbytes]
步骤2:启动QLoRA微调
python src/train_bash.py \ --model_name_or_path Qwen/Qwen1.5-7B-Chat \ --dataset ./formatted_data \ --template chatml \ # Qwen专用模板 --lora_target_modules q_proj v_proj \ --load_in_4bit \ --use_peft \ --per_device_train_batch_size 4 \ --lr_scheduler_type cosine \ --warmup_ratio 0.1 \ --max_length 1024 \ --output_dir ./qwen_lora
步骤3:实时监控
# 查看GPU利用率(需安装nvtop)nvtop# 查看损失曲线tensorboard --logdir ./qwen_lora/runs
步骤4:测试模型
from transformers import AutoModelForCausalLM, AutoTokenizer
model_path = "./qwen_lora"tokenizer = AutoTokenizer.from_pretrained(model_path, trust_remote_code=True)model = AutoModelForCausalLM.from_pretrained(model_path, device_map=“auto”)
query = "如何用Python读取Excel文件?"response, _ = model.chat(tokenizer, query, history=[])print(response)
重要参数说明:
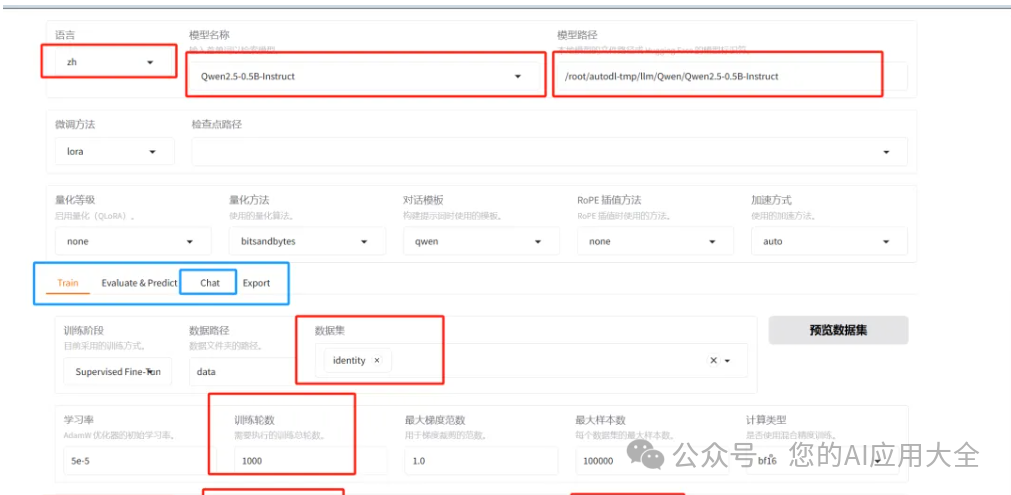
- 模型路径:一定要选择本地的模型路径,否则就会去hugging face上下载
- 微调方法:默认lora
- 检查点路径:训练过程中保存的权重,可从其中的一个权重重新训练。
- 对话模板:不同的模型对应的对话模板是不一样的。选择模型名称,会自动选择对话模板
- 中间的4个任务:train训练,Evalate@predict 测试 ,Chat对话,Export 模型导出。
- 训练方式:lora默认的训练方式就是Supervised Fine-Tuning
- 数据路径:data
- 数据集:选择一个数据集,identity,可以点击预览查看数据集。
- 训练轮次:至少300
- 最大样本数:可以控制样本的数量上限。
- 截断长度:长度越长越占显存,根据样本里的文本长度,大部分数据的最大长度值即可,比如,有90%的样本数据的长度是200,这里填写200.
- 批处理大小:超参数,需要根据你服务器的配置,尝试运行几次,找到资源利用率最高的数值。
- 验证集比例:0.1,也可以不给。
- 输出目录:会自动生成一个路径,要确保每次的目录都不相同,若已存在,则需要去服务器上删除,目录在llamafactory-save目录下。
参数配置完毕后,点击“开始”进行微调。可以看右下角的这个曲线图,也可以看下服务器控制台的日志输出,以及nvitop查看显存的使用情况。
 四、总结
四、总结
通过上述步骤,您可以对像LLaMA这样的大规模语言模型进行微调,以适应特定的任务或应用场景。重要的是要仔细选择合适的模型和数据集,并精心设计微调过程中的各个组成部分。尽管这里提供的指导较为通用,但希望能为您的工作提供一个良好的起点。对于“LLaMA Factory”具体的功能和使用方法,请参考其官方文档或相关资源获取最准确的信息。
想入门 AI 大模型却找不到清晰方向?备考大厂 AI 岗还在四处搜集零散资料?别再浪费时间啦!2025 年 AI 大模型全套学习资料已整理完毕,从学习路线到面试真题,从工具教程到行业报告,一站式覆盖你的所有需求,现在全部免费分享!
👇👇扫码免费领取全部内容👇👇

一、学习必备:100+本大模型电子书+26 份行业报告 + 600+ 套技术PPT,帮你看透 AI 趋势
想了解大模型的行业动态、商业落地案例?大模型电子书?这份资料帮你站在 “行业高度” 学 AI:
1. 100+本大模型方向电子书

2. 26 份行业研究报告:覆盖多领域实践与趋势
报告包含阿里、DeepSeek 等权威机构发布的核心内容,涵盖:

- 职业趋势:《AI + 职业趋势报告》《中国 AI 人才粮仓模型解析》;
- 商业落地:《生成式 AI 商业落地白皮书》《AI Agent 应用落地技术白皮书》;
- 领域细分:《AGI 在金融领域的应用报告》《AI GC 实践案例集》;
- 行业监测:《2024 年中国大模型季度监测报告》《2025 年中国技术市场发展趋势》。
3. 600+套技术大会 PPT:听行业大咖讲实战
PPT 整理自 2024-2025 年热门技术大会,包含百度、腾讯、字节等企业的一线实践:

- 安全方向:《端侧大模型的安全建设》《大模型驱动安全升级(腾讯代码安全实践)》;
- 产品与创新:《大模型产品如何创新与创收》《AI 时代的新范式:构建 AI 产品》;
- 多模态与 Agent:《Step-Video 开源模型(视频生成进展)》《Agentic RAG 的现在与未来》;
- 工程落地:《从原型到生产:AgentOps 加速字节 AI 应用落地》《智能代码助手 CodeFuse 的架构设计》。
二、求职必看:大厂 AI 岗面试 “弹药库”,300 + 真题 + 107 道面经直接抱走
想冲字节、腾讯、阿里、蔚来等大厂 AI 岗?这份面试资料帮你提前 “押题”,拒绝临场慌!

1. 107 道大厂面经:覆盖 Prompt、RAG、大模型应用工程师等热门岗位
面经整理自 2021-2025 年真实面试场景,包含 TPlink、字节、腾讯、蔚来、虾皮、中兴、科大讯飞、京东等企业的高频考题,每道题都附带思路解析:

2. 102 道 AI 大模型真题:直击大模型核心考点
针对大模型专属考题,从概念到实践全面覆盖,帮你理清底层逻辑:

3. 97 道 LLMs 真题:聚焦大型语言模型高频问题
专门拆解 LLMs 的核心痛点与解决方案,比如让很多人头疼的 “复读机问题”:

三、路线必明: AI 大模型学习路线图,1 张图理清核心内容
刚接触 AI 大模型,不知道该从哪学起?这份「AI大模型 学习路线图」直接帮你划重点,不用再盲目摸索!

路线图涵盖 5 大核心板块,从基础到进阶层层递进:一步步带你从入门到进阶,从理论到实战。

L1阶段:启航篇丨极速破界AI新时代
L1阶段:了解大模型的基础知识,以及大模型在各个行业的应用和分析,学习理解大模型的核心原理、关键技术以及大模型应用场景。

L2阶段:攻坚篇丨RAG开发实战工坊
L2阶段:AI大模型RAG应用开发工程,主要学习RAG检索增强生成:包括Naive RAG、Advanced-RAG以及RAG性能评估,还有GraphRAG在内的多个RAG热门项目的分析。

L3阶段:跃迁篇丨Agent智能体架构设计
L3阶段:大模型Agent应用架构进阶实现,主要学习LangChain、 LIamaIndex框架,也会学习到AutoGPT、 MetaGPT等多Agent系统,打造Agent智能体。

L4阶段:精进篇丨模型微调与私有化部署
L4阶段:大模型的微调和私有化部署,更加深入的探讨Transformer架构,学习大模型的微调技术,利用DeepSpeed、Lamam Factory等工具快速进行模型微调,并通过Ollama、vLLM等推理部署框架,实现模型的快速部署。

L5阶段:专题集丨特训篇 【录播课】

四、资料领取:全套内容免费抱走,学 AI 不用再找第二份
不管你是 0 基础想入门 AI 大模型,还是有基础想冲刺大厂、了解行业趋势,这份资料都能满足你!
现在只需按照提示操作,就能免费领取:
👇👇扫码免费领取全部内容👇👇
2025 年想抓住 AI 大模型的风口?别犹豫,这份免费资料就是你的 “起跑线”!


















 21万+
21万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









