




Entropy Law:多数据集组合时的数据筛选方法
Entropy Law: The Story Behind Data Compression and LLM Performance
数据是大型语言模型(LLM)的基石。大多数方法侧重于评价单个样本的质量,而忽略了样本间的组合效应。
受LLMS信息压缩特性的启发,我们发现了一个将LLM性能与数据压缩比和第一个epoch训练损失联系起来的“熵定律”,它们分别反映了数据集的信息冗余度和对该数据集中编码的固有知识的掌握。
基于熵定律的结果,我们提出了一种非常有效和通用的数据选择方法ZIP来训练LLMS,该方法旨在对压缩比较低的数据子集进行优先排序。基于贪婪地选择不同数据的多阶段算法,我们可以得到一个具有满意多样性的良好数据子集。
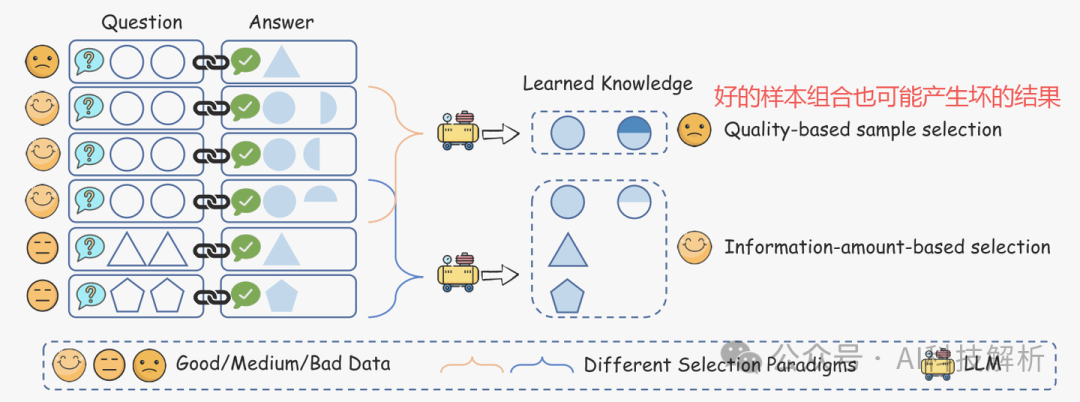
虽然有多个好的样本数据,但它们编码的知识可能是冗余的和相互冲突的。而由几个相对较低质量但不同的样本组成的另一个数据子集可能比上述子集传递更多的信息。(这说明多数据组合时要去重。。。)
在论文《Compression Represents Intelligence Linearly》中提到:LLMS中自回归语言建模的基本机制是信息压缩。(就是训练总数据集的token数/总数据集的char个数,其实并不能完全代表模型的能力,只能说表示了tokenizer的能力)

使用每条消息的平均编码长度(即比特每字符,BPC)来评估模型的压缩效率。
将LLM的性能表示为Z,它预计会受到以下因素的影响:
- 数据压缩比R: 该度量可以通过将压缩前的数据大小除以压缩后的大小得出,该大小可以通过各种现有的压缩算法来计算。直观地说,压缩比较低的数据集表示较高的信息密度。
- 训练损失L: 表示数据是否难以被模型记住。在给定相同的基本模型的情况下,高训练损失通常是由于数据集中的噪声或不一致的信息造成的。在实践中,第一个训练周期中少量训练步长的平均损失足以产生指示性的L值,从而使模型不会对数据进行过度拟合。
- 数据一致性C: 数据的一致性由给定先前上下文的下一个令牌的概率的熵来反映。较高的数据一致性通常会产生较低的训练损失。
- 平均数据质量Q: 这反映了数据的平均样本级质量。
那么有
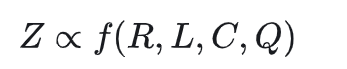
其中数据一致性C通常和L相关,因此选一个就行。数据质量不会随选择而变化,视为常数,则有
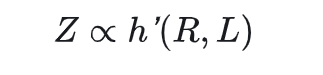
模型的性能与数据压缩比和训练损失有关。将这种关系称为“熵定律”。
ZIP筛选
该方法的目标是在有限的训练数据预算下最大化有效信息量。
- 1、首先全局选择压缩比最低的多个候选样本构建样本池,目的是找到信息密度较高的样本。直观地说,样本内信息冗余度高的数据不太可能具有良好的全局多样性。
- 2、然后采用粗粒度局部选择阶段,将剩余的每个样本添加进样本池,计算总样本池的压缩比。选择总压缩比较小的样本添加进来。这一步计算了多样本之间的组合效果。
- 3、从样本池中选择一个局部样本。和其他样本逐个计算压缩比,压缩比低表明差异大,可保留。最终得到信息差异最大的一个子样本池。

ZIP
这个方法本质上就是通过信息压缩率衡量数据集的信息冗余程度,从而选出差异性最大的数据集**(去重)**进行训练。
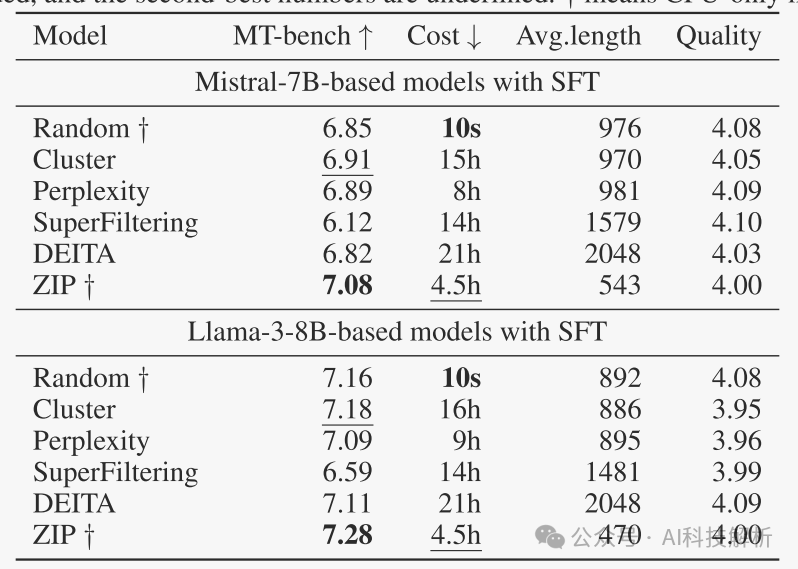
ZIP数据筛选方法比随机选择和其他筛选方法取得了更好的效果。
总结
其实就是去掉重复度高的数据集。但是实际场景中,即使是重复度高的数据集中也会包含大量不重复的内容,这部分内容对拓展模型知识范围有用,因此不如直接对数据去重好用。
类似的还有《Data curation via joint example selection further accelerates multimodal learning》,通过模型loss筛选出最有价值的数据集单独进行训练,减少了训练数据、降低了迭代次数,提高了效率。
高质量微调数据集探索
From Complex to Simple: Enhancing Multi-Constraint Complex Instruction Following Ability of Large Language Models
https://github.com/meowpass/FollowComplexInstruction
本文提出了三个问题:1:什么样的数据能增强SFT的效果?2:如何得到这类数据?3:如何利用上述数据进行有效微调?

Constraints data
- 1、什么样的数据能增强SFT的效果?
复杂约束的数据具有更好的微调结果。也就是数据的描述越详细、准确,微调效果越好。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 9109
9109

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









