



论文解读:LongAlign: A Recipe for Long Context Alignment of Large Language Models
-
摘要:
扩展大型语言模型以有效地处理长上下文需要对相似长度的输入序列进行指令微调。为了解决这个问题,我们提出了 LongAlign——一种用于长上下文对齐的指令数据、训练和评估的配方。首先,我们使用 Self-Instruct 构建了一个长指令跟踪数据集。为了确保数据的多样性,它涵盖了来自各种长上下文源的广泛任务。其次,我们采用
packing和sorted batching策略来加速对不同长度分布的数据的监督微调。此外,我们开发了一种loss weighting方法来平衡打包训练期间不同序列损失的贡献。第三,我们介绍了LongBench-Chat基准,用于评估长度为 10k-100k 的查询上的指令跟踪能力。实验表明,LongAlign 在长上下文任务中的表现优于现有的 LLM 配方高达 30%,同时还保持了它们在处理短文本 , 通用任务的熟练程度。 -
Introduction
-
- 长指令数据的数量和多样性都显着影响对齐模型处理长上下文的能力。
- 长指令数据量对长上下文任务的性能产生积极影响,而不会影响模型的一般能力。
- 采用的
packing和sorted batching策略可以在不损害性能的情况下将训练速度提高了 100% 以上。所提出的loss weighting技术将长上下文性能提高了 10% - 数据:从 9 种数据源收集长句子,采用
Self-Instruct方法,生成 10K 指令数据(长度区间 8k - 64k )。 - 计算效率:将序列打包在一起,直到最大长度。当包含不同数量的序列的包被分配相同的权重时,会引入
bias. 即:含有 target token越多的序列包 ,对梯度贡献就越大,因此提出loss weighting平衡策略,来平衡不同序列的贡献。 - 评估:
LongBench-Chat它涵盖了指令跟随能力的不同方面,例如长上下文中的推理、编码、摘要和多语言翻译。 - 数据:缺乏用于长指令跟随监督微调的数据集,缺乏构建此类数据的方法。
- 计算效率:长上下文数据的长度分布差异显著降低了传统批处理方法在多 GPU 设置下的训练效率,因为处理较短输入的 GPU 必须在等待处理较长输入的 GPU 完成任务,在此期间保持空闲。
- 评估:迫切需要一个强大的基准来评估llm对现实世界查询的长上下文能力。
-
长文本训练挑战:
-
-
解决方案:
-
- 数据:从 9 种数据源收集长句子,采用
Self-Instruct方法,生成 10K 指令数据(长度区间 8k - 64k )。 - 计算效率:将序列打包在一起,直到最大长度。当包含不同数量的序列的包被分配相同的权重时,会引入
bias. 即:含有 target token越多的序列包 ,对梯度贡献就越大,因此提出loss weighting平衡策略,来平衡不同序列的贡献。 - 评估:
LongBench-Chat它涵盖了指令跟随能力的不同方面,例如长上下文中的推理、编码、摘要和多语言翻译。
- 数据:从 9 种数据源收集长句子,采用
-
发现:
-
- 长指令数据的数量和多样性都显着影响对齐模型处理长上下文的能力。
- 长指令数据量对长上下文任务的性能产生积极影响,而不会影响模型的一般能力。
- 采用的
packing和sorted batching策略可以在不损害性能的情况下将训练速度提高了 100% 以上。所提出的loss weighting技术将长上下文性能提高了 10%
-
-
LongAlign
-
-
数据构造:
采用四种类型的任务提示来鼓励 Claude 产生更多样化的指令数据。General 、 Summary 、Reasoning 、Information extraction。例如:
-
User:In my younger and more vulnerable years my father gave mesome advice that I've been turning over in my mind ever since....
Given the above text, please propose 5 English questions thatrequire summarization or integration from multiple parts,make sure they are diverse and cover all parts of the text, inthe following format: "1: ", "2: ", ...
Assistant:1. Summarize the plots between Gatsby and Daisy...
-
训练策略:
混合训练:长指令数据与通用指令数据集混合进行训练。
Packing:
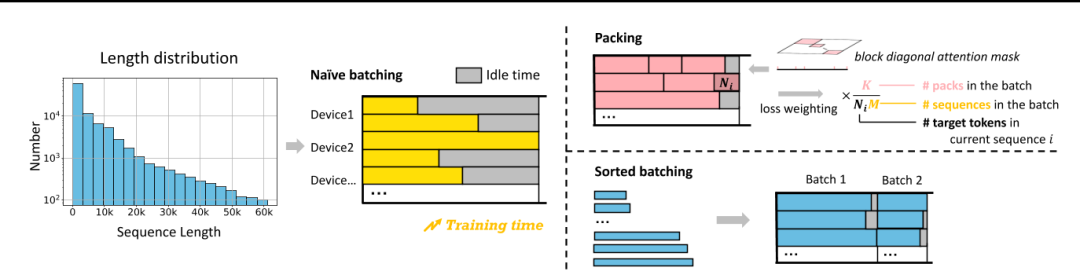 Figure 3. Under a long-tailed data length distribution, packing or sorted batching can reduce idle time and speed up the training process. Loss weighting is required during packing to balance the loss contribution across sequences.
Figure 3. Under a long-tailed data length distribution, packing or sorted batching can reduce idle time and speed up the training process. Loss weighting is required during packing to balance the loss contribution across sequences.图 3. 在长尾数据长度分布下,打包或排序批处理可以减少空闲时间并加快训练过程。打包期间需要进行损失加权,以平衡序列之间的损失贡献。
为了防止自注意计算过程中同一包内不同序列之间的交叉污染,我们通过一个包含不同序列的开始和结束位置的列表,并利用FlashAttention 2中的flash_attn_varlen_func,支持块对角注意的高效计算。与传统的使用 2D 注意掩码相比,它需要更少的计算和 IO 时间。(在打包训练期间,对于每批数据,我们传递一个特殊的一维注意掩码。在这个掩码中,第 i 个元素表示批次中第 i 个序列的起始索引。掩码的第一个元素为 0,最后一个元素等于 batch_size×seq_len。在注意力计算过程中,我们使用来自 FlashAttention 2 的 flash_attn_varlen_func 函数,并将注意力掩码传递给函数的 cu_seqlens_q 和 cu_seqlens_k 参数。该函数在掩码中相邻元素的开始和结束索引之间的序列中执行注意力计算)
loss weighting:
原因:在计算每个批次的平均损失时,包含较少序列的包(通常是较长的序列)或包含更多目标令牌的序列,对最终损失的影响更大。

Sorted batching:
为了确保每批中的序列长度相似,我们按长度对数据进行排序,并为每个批次选择一个随机连续的数据组,没有重复.然而,这种策略不可避免地会在不同批次的数据分布中引入偏差,其中批次由所有长序列或所有短序列组成。
解决方法: 梯度累积
-
LongBench-Chat
50 个长上下文真实世界查询,长度从 10k 到 100k. 涵盖各种关键的用户密集型场景,例如文档 QA、摘要和编码。避免在预训练期间使用模型可能看到和记忆的流行长文本。
-
实验:
Q1 : 在SFT期间,长指令数据的数量和多样性如何影响模型在下游任务中的性能。
Q2 : 在训练期间结合长指令数据是否会影响模型在短上下文场景中的通用能力及其指令跟随/会话能力。
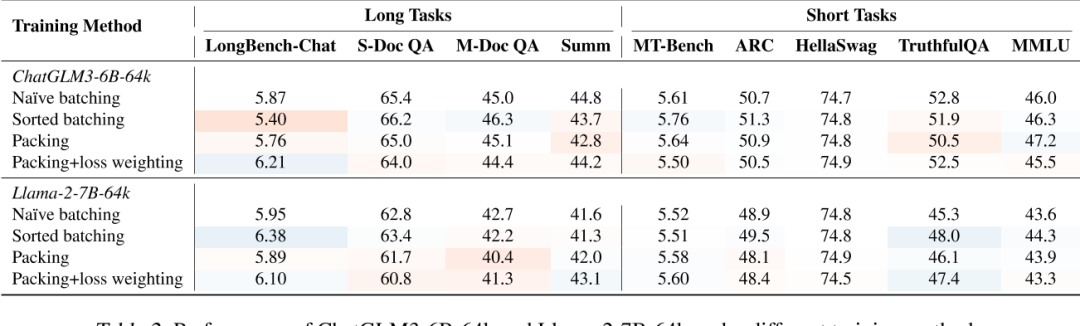
 Table 1. Performance of ChatGLM3-6B-64k after training on different quantities and types of long instruction data. The blue-to-red color transition indicates the level of performance, i.e., deeper blue signifies higher performance, while deeper red indicates lower performance, compared to the baseline method (LongAlign-0k).
Table 1. Performance of ChatGLM3-6B-64k after training on different quantities and types of long instruction data. The blue-to-red color transition indicates the level of performance, i.e., deeper blue signifies higher performance, while deeper red indicates lower performance, compared to the baseline method (LongAlign-0k).结论:较长的指令数据提高了长任务的性能,而不影响短任务的性能,长指令数据的多样性有利于模型的指令跟随能力。
Q3 : 打包和排序批处理训练方法对模型的训练效率和模型最终性能的影响。
 img
img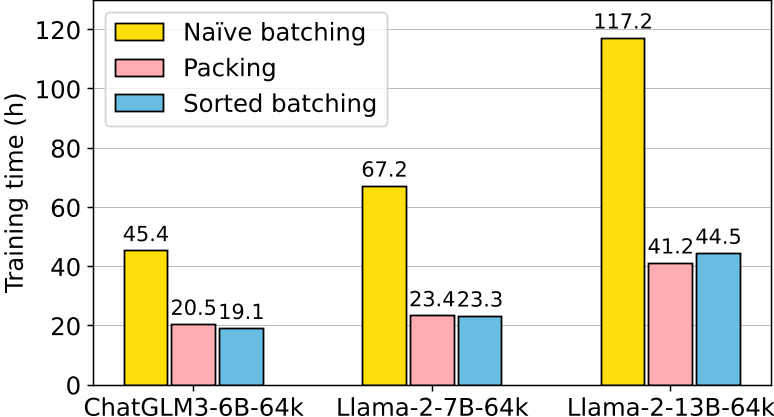 img
img
结论:打包和排序批处理使训练效率加倍,同时表现出良好的性能。损失加权显著提高了打包训练中长指令任务的表现。
博客解读:GLM Long: Scaling Pre-trained Model Contexts to Millions
- Training Process:逐步激活并维持模型的长文本能力。
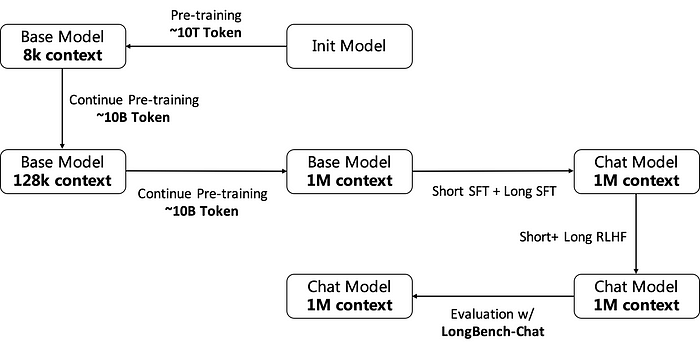
- Pretrain Data
对于第一阶段扩充到128K的训练数据,其组成主要包括以下几个部分:
- 原始分布的预训练数据包含大约 4B 个 token。
- 基于预训练数据,上采样长度超过8K的数据,大约是3B个token。
- 基于预训练数据,对长度超过 32K 的数据进行上采样,其中也包含约 3B 个 token。
在处理这两类上采样数据时,我们尽量保证每个长度区间内的token总数是一致的。
对于第二阶段扩充到 1M 的训练数据, 人工构造长文本数据:
这种类型的数据是通过拼接现有数据(包括来自预训练语料库和公开可用文档数据),进行生成的。为了保证拼接数据的合理性,设计了两阶段聚类策略。
首先,我们对文档数据进行采样并使用语言模型对其进行分类。然后,在每个分类下,我们利用Embedding模型来得到数据的向量表示。
通过这种方法,我们确保了8K到1M长度范围内的总令牌数量平衡,从而生成所需的人工长文本数据。
-
原始分布的预训练数据包含大约 3.5B 个 token。
-
基于预训练数据,上采样长度超过8K的数据,约为1.5B个token。
-
基于预训练数据,上采样长度超过32K的数据,约为1.5B个token。
-
基于预训练数据,对长度超过128K的数据进行上采样,这也约为1.5B个token。
-
人工长文本数据,大约包含2B个token。
-
Training
上文
packing策略:packing training strategy with Attention separation img
img -
Sft Data
人工标注:与仅需从文档中提取信息片段以回答的问题相比,复杂问题需要从文档中提取多个事实来回答,能够更有效地激发模型的长文本推理能力。对此,我们根据长文本的实际应用场景筛选并区分了相应的数据源和任务类型,并指导标注员尽可能标注复杂的问题及其相应的答案,从而构建了我们的长文本SFT数据集。考虑到标注的难度和成本,我们仅标注长度在128K以内的数据。
短窗口模型标注(SCM):
Single chunk self-instruct, SCI: 从给定的文本中随机选择一个片段,其长度与SCM模型的上下文窗口匹配。从多个长文本任务模板中选择一个,并让SCM模型生成一个具有挑战性的问题及其答案。最终的SFT数据由原始文本、问题和答案连接而成。
Multi- chunk self-instruct ( MCI):从给定的文本中随机选择多个片段。这些片段的总长度相当于SCM模型的上下文窗口,如果文本由多个文档组成,则这些片段应在每个文档中均匀分布。然后,从长文本任务模板中选择一个,并让SCM模型生成一个需要综合多个片段信息的问题及其答案。最终的SFT数据也由原始文本、问题和答案组成。
Multi-level summary: 在给定的文本中,根据摘要任务模板选择一个,将文本分成多个短于SCM上下文窗口的片段,并要求SCM模型为每个片段生成摘要。最后,对这些摘要进行总结,并根据任务模板中的提示生成答案。最终的SFT数据由原始文本、问题和答案连接而成。
为了验证这些方法的有效性,我们使用长度为128K的标注SFT数据训练了一个具有16K上下文窗口的模型作为SCM模型,并自动生成了新的128K长度的SFT数据。在LongBench-Chat等下游评估集上的实验结果表明,使用新的128K长度SFT数据训练的模型与使用标注的128K长度SFT数据训练的模型性能相似,证明了我们基于SCM模型的方法可以几乎无损地构建更长的SFT数据。
-
Training
结合了Packing和Sorted Batching的优势,提出了
Sorted Packing训练方法。根据计算复杂度, 在同一个批次内构建包,以确保同一个批次中每个包的计算复杂度相似,从而减少气泡时间。此外,我们引入了层累积技术以避免排序带来的偏差。 -
RLHF(DPO)
我们使用与短文本相同的奖励模型对长文本的答案进行评分。为了避免超过奖励模型的上下文限制,我们只保留问题和答案,并丢弃等长的输入。我们还尝试使用GLM4–128K等语言模型作为长文本的奖励模型,根据所有输入自动生成最终答案的排名。然而,实验结果表明,当直接使用长文本语言模型作为奖励模型时,结果波动很大,并未产生预期的效果,因此最好直接使用短文本的奖励模型。我们认为,训练长文本奖励模型对于长文本RLHF至关重要。然而,目前长文本奖励模型的数据标注极其困难,我们仍需继续探索,以找到一种合理的方式来训练长文本奖励模型。
-
Training of the Infra
在长文本训练大型模型的过程中,基础设施面临的主要挑战是中间变量激活(Activation)的内存使用量显著增加。然而,在分析现有的主流3D并行策略后,我们发现它们在解决这个问题上都存在一定的不足。
张量并行(Tensor Parallel, TP):这种方法可以减少激活内存的使用,但由于通信量巨大,通常不适合跨机器使用,并且并行度一般不超过8。
管道并行(Pipeline Parallel, PP):为了保持效率,通常需要增加微批次大小,但这样做虽然能确保效率,却对降低激活内存使用量没有明显效果。
数据并行(Data Parallelism, DP):无法减少单个数据样本的激活内存使用量。
为了解决这个问题,一种名为**序列并行(Sequence Parallelism)**的新并行方法被提出。其核心动机在于,在Transformer架构中,令牌(tokens)仅在执行注意力计算时需要相互交互,而在其他部分,令牌是相互独立的。基于这一观察,序列并行仅在注意力部分进行并行处理,而在其他模块中,将长序列视为多个数据片段,类似于数据并行DP进行处理。
序列并行的主流实现有两种,分别是 Ring Attention 和 DeepSpeed Ulysses
Ring Attention:
优点:并行扩展性好,没有明显的限制;在使用GQA(Grouped Query Attention)时,通信仅限于组内的kv(key-value),通信量相对较小。、缺点:需要良好的计算与通信掩码(masking)来实现高效率;对稀疏注意力(Sparse Attention)和其他注意力变体的修改不够友好,侵入性地修改了注意力的实现。
DeepSpeed Ulysses:
优点:对注意力实现的修改不具有侵入性,对各种稀疏注意力(Sparse Attention)及相关变化相对友好;通信频率较低。
缺点:所有并行副本需要完整的模型参数,对ZeRO(Zero Redundancy Optimizer)之外的并行切片策略不够友好;并行度相对有限,一般不超过GQA(Grouped Query Attention)组的数量,否则需要额外的通信。
论文解读:LONGWRITER: UNLEASHING 10,000+ WORD GENERATION FROM LONG CONTEXT LLMS
-
摘要: 当前的长上下文大型语言模型(LLMs)可以处理输入高达100,000个token,但在生成超过2,000个单词的输出时仍然面临困难。通过控制实验,我们发现模型所能生成的最大长度本质上受限于其SFT数据中存在的输出长度上限。为了解决这个问题,我们引入了AgentWrite,一个基于代理的流水线,将超长生成任务分解为子任务,使现成的LLMs能够生成超过20,000个单词的连贯输出。利用AgentWrite,我们构建了LongWriter-6k,一个包含6,000个SFT数据的数据集,输出长度从2k到32k个单词不等。通过将这个数据集纳入模型训练,我们成功地将现有模型的输出长度扩展到超过10,000个单词,同时保持输出质量。我们还开发了LongBench-Write,一个用于评估超长生成能力的综合基准。我们的9B参数模型通过DPO(Direct Preference Optimization)进一步改进,在这个基准上达到了最先进的性能,甚至超过了更大规模的专有模型。总的来说,我们的工作表明,现有的长上下文LLM已经具备了更大的输出窗口的潜力——你所需要的只是在模型对齐过程中使用扩展输出的数据来解锁这种能力。
-
主要工作
-
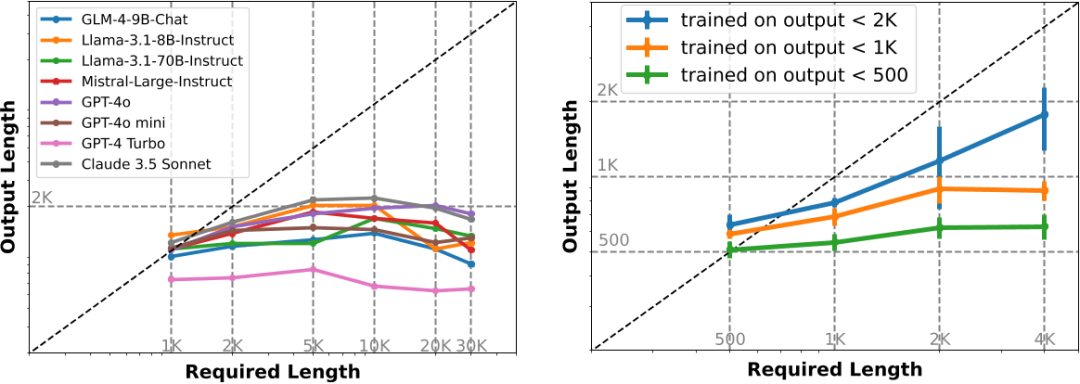
LongWrite-Ruler:验证模型所能生成的最大长度本质上受限于其SFT数据中存在的输出长度上限。创建了8个不同的指令,每个指令在中文和英语中,并在指令中改变输出长度要求“L”。
-
-
 img
img结论:
\1. 左图:现有长文本模型输出长度上限为2000字左右;
\2. 左图:对于要求输出更长的测试样例,拒绝回复率增高,导致平均输出长度反而下降;
\3. 右图:模型所能生成的最大长度 与 SFT数据中存在的输出长度 呈正相关;
-
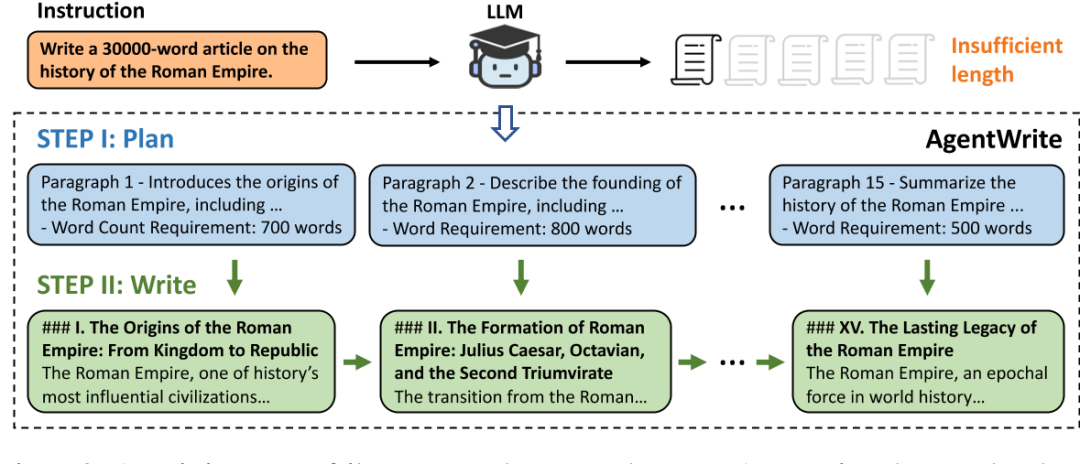
AgentWrite:将长文写作任务分解为多个子任务,每个子任务负责撰写一段;最终将各个子任务拼接,得到长输出;
 img
img -
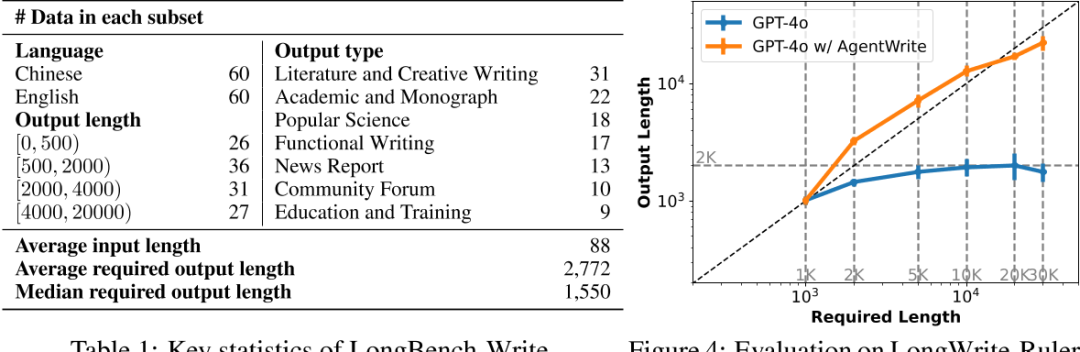
LongBench-Write :
在长度和写作质量方面,对AgentWrite方法合理性进行评估验证;
 img
img评测:质量指标(SQ) + 长度指标(SL)
输出质量SQ则使用GPT-4o,从以下6个维度来评价:
-
Relevance
-
Accuracy
-
Coherence
-
Clarity
-
Breadth and Depth
-
Reading Experience
-
-
输出质量SL 由下述公式计算:
-
 img
img注:Parallel 是指 plan_write中,write是并行输出所有段的内容,不依赖前文已生长的章节段落。
-
LongWriter-6K数据:选择了6,000个需要长输出(超过2,000字)的用户指令;
-
GLM-4的SFT数据中选择了3,000个指令(中文);WildChat-1M 中选择了3,000个指令(英文)
进一步应用基于规则的匹配来过滤掉有毒指令和用于数据抓取的指令。并手动检查了自动选择的指令,并验证了超过95%的指令确实需要数千字的响应。
对于这6,000个指令,我们随后使用AgentWrite流水线与GPT-4o来获取响应。我们对获取的数据进行了进一步的后处理,包括过滤掉过短的输出和由于AgentWrite第一步中获取的规划步骤过多而导致模型输出崩溃的情况。大约0.2%的数据被过滤掉。同时,清理了模型可能在每个输出部分开头添加的不相关标识符,如“段落1”、“段落2”等。我们将最终获得的长输出数据集称为“LongWriter-6k”。
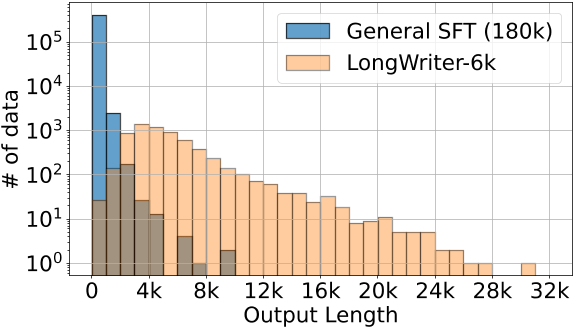
将 LongWriter-6k 与180k的GLM-4通用chat SFT 数据结合,形成整个训练集。从下图中,LongWriter-6k 有效补充了输出长度超过 2k 字的通用chat SFT 数据的稀缺性,且LongWriter-6k 的输出长度在 2k-10k 之间的分布相对均匀。
-
-
训练:
packing training with loss weighting:如果我们按序列平均损失,即取批处理中每个序列的平均损失的平均值,那么在长输出数据中,每个目标标记对损失的贡献将显著低于短输出。在我们的实验中,我们还发现这会导致模型在长输出任务上的性能次优。因此,我们选择了一种按标记平均损失的权重策略,其中损失是通过计算该批处理中所有目标标记的损失的平均值来计算的. -
结果:
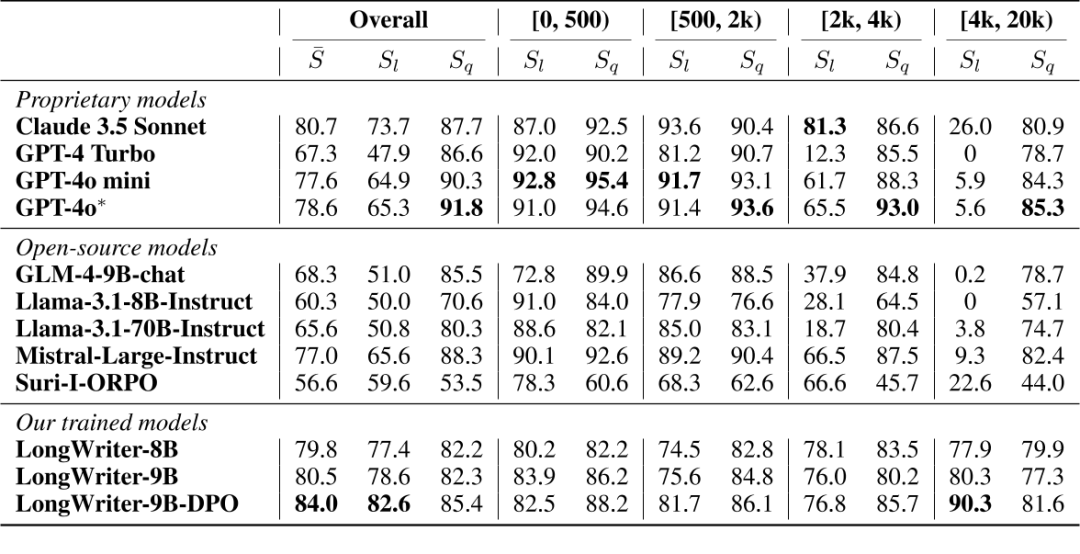 img
img
Github:https://github.com/THUDM/LongWriter
LongWriter/
├── agentwrite/ # 与代理写入相关的文件夹
├── data/ # 数据文件夹
├── evaluation/ # 评估文件夹
├── train/ # 训练文件夹
│ ├── ds_config/ # deepspeed 配置文件
│ └── output/glm4/longwriter/ # 输出结果文件夹
│ ├── patch/ # 补丁或更新文件夹
│ ├── modeling_chatglm.py # ChatGLM 模型相关脚本
│ ├── modeling_llama.py # Llama 模型相关脚本
│ ├── tokenization_chatglm.py # ChatGLM 分词器相关脚本
│ ├── scripts/ # 脚本文件夹
│ ├── glm4_longwriter.sh # glm4_longwriter 模型启动脚本
│ ├── llama3_longwriter.sh
│ ├── dataset.py # 数据集处理脚本
│ ├── main.py # 主程序入口脚本
│ ├── pre_tokenize_glm4.py # GLM4 预分词脚本
│ ├── pre_tokenize_llama3.py # Llama3 预分词脚本
│ ├── sort_and_group.py # 排序和分组脚本
│ └── trainer.py # 训练器脚本
└── __init__.py # Python 包初始化文件(可选)
对于 packing 训练,请修改注意力计算以支持传入标记了每个序列在 pack 中起止位置的 1D 注意力掩码,以及模型前向计算函数以支持 loss weighting。已GLM4为例,需要修改 modeling_chatglm.py 中的 CoreAttention.forward 和 ChatGLMForConditionalGeneration.forward,参考 patch目录下文件。
以GLM4 为例,pre_tokenize_glm4.py \ sort_and_group.py 将原始训练数据转化模型输入,即 input_ids 、 attention_mask、labels、
-
weighting
在
longalign中, 因为packing需要做Loss weighting操作,需要传入1D 的weight信息。
weight = torch.where(label[:eos_indice+1] == -100, 0, 1)
if weight.sum() > 0.5:
weight = weight / weight.sum()
第i个序列的损失按 进行缩放 ,即每个seqence 中 target_tokens 的权重,根据target_tokens 数量总和均分, 主要避免每个patch或者 sample 对梯度贡献不一致;
'''weights: 1D '''
shift_weights = weights[..., 1:].contiguous()
loss_fct = CrossEntropyLoss(ignore_index=-100, reduction='none')
loss = loss_fct(shift_logits.view(-1, shift_logits.size(-1)), shift_labels.view(-1))
loss = (loss * shift_weights).sum()
在longwriter 中, 是按 标记平均损失的权重策略,即一个batch里,不同的sample会有不同的 seqence数量或者 target_tokens 数量;但每个target_tokens 的权重是一致的。在不同batch里,需要为每个batch 分配个 weight,这个weight 只和这个 batch 内 seqence数量有关;代码里将这个weight 设置为常量 batch_seq_num / 30。
'''weights: scaled '''
loss_fct = CrossEntropyLoss(ignore_index=-100)
loss = loss_fct(shift_logits.view(-1, shift_logits.size(-1)), shift_labels.view(-1))
loss *= weights
-
attention_mask
基于 FlashAttention 2 的 flash_attn_varlen_func 函数来实现 CP 并行,
attention_mask是1D的tensor, 元素表示不同序列的开始和结束位置。与常规(0 或1) 不同。例如:
attention_mask
>>> tensor([ 0, 2769, 7758, 14141, 16624, 20809, 23171, 32768], device='cuda:0', dtype=torch.int32)
flash_attn_varlen_func 实现:
from flash_attn.flash_attn_interface import flash_attn_varlen_func as flash_attn_unpadded_func
cu_seqlens_q = attention_mask
cu_seqlens_k = cu_seqlens_q
context_layer = flash_attn_unpadded_func(
query_layer, key_layer, value_layer, cu_seqlens_q, cu_seqlens_k, seqlen_q, seqlen_k,
self.attention_dropout,
softmax_scale=1.0 / self.norm_factor, causal=is_causal
)
"""在embed阶段做维度转换,即 query_layer, key_layer , value_layer 维度信息:[sq, b, np, hn]"""
如何学习大模型
现在社会上大模型越来越普及了,已经有很多人都想往这里面扎,但是却找不到适合的方法去学习。
作为一名资深码农,初入大模型时也吃了很多亏,踩了无数坑。现在我想把我的经验和知识分享给你们,帮助你们学习AI大模型,能够解决你们学习中的困难。
下面这些都是我当初辛苦整理和花钱购买的资料,现在我已将重要的AI大模型资料包括市面上AI大模型各大白皮书、AGI大模型系统学习路线、AI大模型视频教程、实战学习,等录播视频免费分享出来,需要的小伙伴可以扫取。

一、AGI大模型系统学习路线
很多人学习大模型的时候没有方向,东学一点西学一点,像只无头苍蝇乱撞,我下面分享的这个学习路线希望能够帮助到你们学习AI大模型。

二、AI大模型视频教程

三、AI大模型各大学习书籍

四、AI大模型各大场景实战案例

五、结束语
学习AI大模型是当前科技发展的趋势,它不仅能够为我们提供更多的机会和挑战,还能够让我们更好地理解和应用人工智能技术。通过学习AI大模型,我们可以深入了解深度学习、神经网络等核心概念,并将其应用于自然语言处理、计算机视觉、语音识别等领域。同时,掌握AI大模型还能够为我们的职业发展增添竞争力,成为未来技术领域的领导者。
再者,学习AI大模型也能为我们自己创造更多的价值,提供更多的岗位以及副业创收,让自己的生活更上一层楼。
因此,学习AI大模型是一项有前景且值得投入的时间和精力的重要选择。

















 717
717

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









