



本文内容概览:
☑️LLM各个岗位的*常规技能需求*
· DE
· DS
· AS/Modeling DS
· MLE
· SWE
☑️如何 零基础入门LLM 及具体个人project sample
· Personalized Recommendation
· Costumer Support
☑️实习tips
LLM各个岗位的常规技能需求
首先,我们从Stanford DS coursework出发,总结出了以下4个必备技能点:

\1. Machine Learning:比较常见的课程包括NLP、CV、GNN,更传统的一些ML,比如说Random Forest,Boosted Trees;
\2. Stats & Math:更多是数学方面,也有stochastic processes,A/B testing等;
\3. Data & Business Sense:如何进行data analytics,例如理解一个domain里数据的意义,怎样去做特定数据的ETL,怎么去处理数据以使其达到更适合去训练模型的状态;
\4. Data Structure & Algorithm
其次,大厂LLM项目里不同岗位需要掌握的技能点各不相同。因此要想好自己喜欢哪一种类型的工作,同时也要想哪些岗位是最合适自己的,再有的放矢地学习前述技能。
01
DE
主要是把控数据,提高数据质量,使得数据可以直接用于模型训练。作为DE,需要关注数据源以一个怎样的streaming的形式存下来的,有什么schema,怎样更高效地去提取数据、清理数据,使数据可以直接用作下游训练模型的或者统计数据的input。
02
DS
更偏analytics,需要对数据进行分析。作为DS,在一个新的模型上线后,需要去判断新的模型feature做得好不好。尤其是对于AI产品,在产品形态和用户交互方面与以往的互联网产品完全不同,以往网页上常用的CTR (Click-through Rate),Dura time在新的产品形态下并不适用。DS需要重新定义一些metrics,去衡量新的feature或者新的模型是否有效。
同时,DS也需要提供insightful analysis,指导产品未来的改进。例如DS可以通过分析目前产品的不足,写一个报告去推动新feature的开发。

03
AS/Modeling DS
在Microsoft或者Amazon比较多。更偏modeling,主要负责提升模型的表现,包括独立去develop一个新的machine learning algorithm,或者提升现有模型。
AS日常工作主要需要看paper,implement其中的方法并提升这个方法, 也要对模型进行训练并且deploy到线上。
04
MLE
在Google和Meta会比较多。这些公司内有明显的research team和production team的区分。Research team会负责模型的研发,MLE负责把模型更好地deploy到线上。在这样的情况下,MLE更多需要考虑:
1)Scalability:模型怎样可以更高效,在并发情况下没有问题;
2)Inference Optimization:怎样更快地去更快更稳定地去运行模型;
当发现一些模型上的不足,主动和research team去提出,并参与到下一版本algorithm的improvement。
05
SWE
所有的ML project都有software engineer。SWE一方面要写爬虫程序,保证能够顺利爬取大量的网页文本Web Corpus用作LLM的训练,去读取、处理、存储一个data pipeline。另一方面,SWE也需要负责LLM training和inference的infra,保证训练的高效性,以及推理的正确性。

如何零基础入门LLM
首先第一步是入门学习LLM所需的基础理论。非常推荐学习NLP类型的基础课程,其中强推CS224N: Natural Language Processing with Deep Learning。这个可以在Google上找到这门课程,有往年的录屏,建议把这门课的slides、作业以及course project都认真完成。另外也可以在Coursera上学习prompt engineering的基础课程。LImma和千问的Report也是很好的学习资源。
其次是通过hands-on project来实际理解和应用LLM。下面是两个个人project sample,用来具体展示如何在做project中应用LLM:
01
Personalized Recommendation
假设我们要做一个类似小红书的推荐系统,需要根据用户的历史浏览记录、笔记、是否点赞等历史数据去预测这位用户会接下来会对哪些topic感兴趣,并进行topic generation。
可以从Kaggle上获取数据集或者自己收集一些真实数据作为ground truth data。在prompt engineering的过程中,把数据划分为training set和test set(比如用户的interaction history、以及用户后续实际会点开的笔记),搭建evaluation metric并评估模型的表现,从而对prompt进行迭代。
到此,我们就搭建了一个很简单的产品。除此之外,可以用之前提到的low cost的方式,去生成数据,再手把手FinetuneLIama – 3.1-8B或者一个更小的model,在自己的电脑上运行。
02
Costumer Support
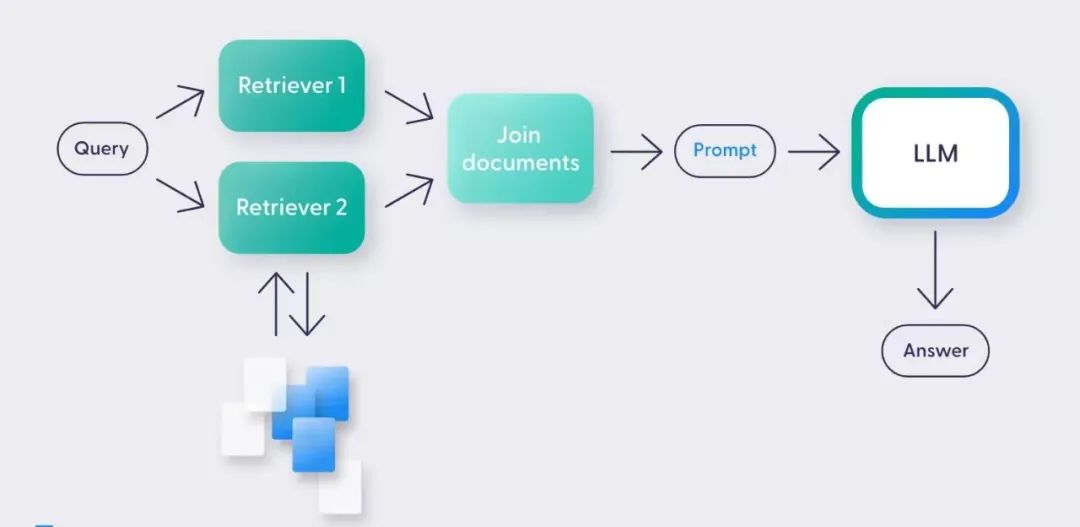
假设我们要用LLM来搭建一个网站客服的自动回复。这个case会多一层RAG(retrieval augmented generation) Layer,也就是说我们可以把关于这个产品的所有信息放到一个vector database里,要有一个embedding model,需要build一个RAG workflow。
在实际运用时,用户发出query后,在文档里去搜索并找到相关文档,把找到的文档和问题以及给到大模型去回答。在将文档和问题给到大模型这一步也需要做一个prompt engineering,通过一个prompt来触发大模型回答问题。
有了RAG以及prompt engineering,也可以做一个简单的产品了。
最后,LLM的发展实在是日新月异,让自己stay up to date也很重要。可以设置Google scholar的notification,关注和学习LLM领域新发表的论文;另外Twitter也是很好的stay up to date的途径,在Twitter上关注这个领域的researcher,他们会定期分享有意思的研究。
另外,在LLM时代也要把LLM作为效率提升工具用起来,帮助自己形成一个human and machine both in the loop 的workflow。这里也推荐一些工具:1)Notebook LLM:可以利用Notebook LLM去高效地学习文献和视频教程,有问题和它一起解决。2)Claude:可以用到brainstorming帮助自己写code或者做experiment。例如你有一个很简单的idea,想做成APP或一个项目,可以让Claude去coding,然后自己再对code进行review。3)Sakana AI’s Scientist:是一个workflow, Sakana AI’s Scientist有capability完成整个research的流程,不过还是需要人类的supervision和reward。

实习tips
目前LLM相关的工作机会中会有很多target PhD的,硕士生如果想在其中脱颖而出的话,有一些小tips可以给到大家:
1)可以考虑多在学校和老师做LLM的研究。一些老师也会有业界的资源,也有可能可以帮助你进入相关的Lab。
2)更常见的是一般大厂都会有Residency Program,例如Google DeepMind、OpenAI、Anthropic等,target的就是本科生和研究生。
3)在普通的DS实习中,也可以主动跟自己的manager去沟通自己想要尝试针对某一个问题应用LLM的想法,一般manager都会鼓励你去尝试
4)保持好奇心,积极学习和探索,让自己背景够强,也是有可能拿到LLM相关的实习。

结语
以上就是关于LLM领域所需技能和应用实例
的全部内容~
如何零基础入门 / 学习AI大模型?
大模型时代,火爆出圈的LLM大模型让程序员们开始重新评估自己的本领。 “AI会取代那些行业?”“谁的饭碗又将不保了?”等问题热议不断。
不如成为「掌握AI工具的技术人」,毕竟AI时代,谁先尝试,谁就能占得先机!
想正式转到一些新兴的 AI 行业,不仅需要系统的学习AI大模型。同时也要跟已有的技能结合,辅助编程提效,或上手实操应用,增加自己的职场竞争力。
但是LLM相关的内容很多,现在网上的老课程老教材关于LLM又太少。所以现在小白入门就只能靠自学,学习成本和门槛很高
那么我作为一名热心肠的互联网老兵,我意识到有很多经验和知识值得分享给大家,希望可以帮助到更多学习大模型的人!至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
这份完整版的大模型 AI 学习资料已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】

👉 福利来袭优快云大礼包:《2025最全AI大模型学习资源包》免费分享,安全可点 👈
全套AGI大模型学习大纲+路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。




👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
👉 福利来袭优快云大礼包:《2025最全AI大模型学习资源包》免费分享,安全可点 👈

这份完整版的大模型 AI 学习资料已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】
作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。

















 3511
3511

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









