




在本篇文章中,我们将探索如何训练一个能够将喜爱的人物置入任何场景中并实现高度一致性的LoRA模型。借助LoRA,我们能够创造出极为逼真的人物图像,就如同我为斯嘉丽训练的LoRA模型所展示的那样。

那么,让我们一起深入了解如何训练LoRA。
Kohya训练器
在多种工具中,Kohya训练器因其全面的功能——不仅限于训练LoRA,也包括DreamBooth和Text Inversion——而广受欢迎。
国内也有一些开发者制作出了一些好用的训练器,比如赛博丹炉和秋叶丹炉。它们的原理和Kohya一样,设置好参数以后,最终都会转化为脚本进行训练。所以说,掌握了Kohya训练器以后,其他的训练器也不在话下。
安装Kohya相对简单,其详细的安装指南可在项目的Github主页(github.com/bmaltais/ko…)找到。
此外,B站的知名UP主Nenly也提供了一份详细的安装攻略(gf66fxi6ji.feishu.cn/wiki/Q4EYwQ…),非常值得参考。
LoRA训练流程

训练LoRA的流程包括以下几个关键步骤:
1️⃣ 准备数据集:选取适合训练的图片。
2️⃣ 图片预处理:进行裁剪和打标,为图片添加合适的标注或提示词。
3️⃣ 设置训练参数:在Kohya训练器中进行参数设置。
4️⃣ 开启训练:通过命令行查看训练进度。
5️⃣ 测试训练结果:挑选出效果最佳的LoRA文件进行测试。
LoRA训练的底层逻辑
为了解决可能出现的疑惑,本段落将深入解释LoRA训练的底层逻辑。通过深入了解这一过程,您将能更清晰地把握如何训练出一个高质量的LoRA模型。
LoRA训练概述
LoRA模型的训练目标是生成的图片与原训练图像高度相似。这是通过在Diffusion模型上添加额外权重来实现的,这些权重被保存在一个称作LoRA文件的单独文件中。可以将LoRA文件视为Diffusion模型的一种插件,这种插件会根据训练过程不断调整权重,以达到与原始训练图相似的效果。
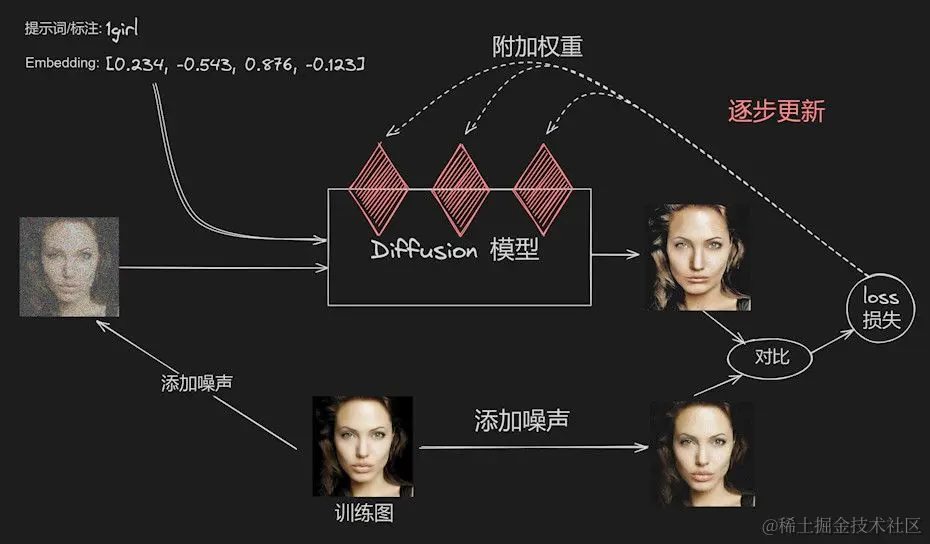
训练过程详解
- 添加初始噪声:首先,我们会给训练图像添加一些初始噪声,这一步骤是为了模拟Diffusion过程中的噪声添加和去除过程,提高模型的泛化能力。
- 打标与去噪:在添加噪声后,Diffusion模型将根据训练图上的标注(例如“1girl”)进行去噪处理。这解释了为何我们需要在训练前为训练图打上标签的重要性。
- 计算Loss值:去噪后,我们将得到一张新的图片,用于与之前添加噪声的图片进行对比,通过这一比较,计算出两张图片之间的差异性,即Loss值。这个值反映了经过初步训练后的图片与原始训练图之间的差异。根据这个Loss值,AI会调整附加在Diffusion模型上的权重,使得模型去噪后的图片与原始训练图更加接近。
- 迭代优化:这一过程会不断重复,通过迭代调整权重,LoRA文件的训练效果将逐步提升。这个迭代次数也就是我们在Kohya训练器里设置的最大训练步数。
- 重复次数和轮次:在训练过程中,每张图都会被训练多次,这一次数称为重复次数(Repeats)。所有图片经过若干重复次数的训练后,完成的总体过程称为一个轮次(Epoch),这个参数也是在Kohya训练器中进行设置的。
通过上述步骤,LoRA模型的训练涉及到精细的权重调整和优化,确保了生成图像与原始训练图之间的高度相似性。希望这一解析能帮助您更好地理解LoRA模型的训练机制。
正式开始LoRA训练:以斯嘉丽为例
在理解了LoRA训练的底层逻辑后,我们现在可以开始实际的训练过程了。本次我们将以众所周知的好莱坞明星斯嘉丽·约翰逊为例,展开训练。下面是详细的步骤和一些建议,希望能帮助你顺利完成LoRA模型的训练。
第一步:准备训练集
成功的LoRA训练起始于高质量的数据集。以下是一些建议,帮助你准备一个合格的训练集:

选择合适的图片作为训练集是至关重要的第一步。优质的数据集直接影响训练结果的质量。
第二步:图片预处理
裁剪
为了让AI更好地学习人物的脸部特征,建议以1比1的宽高比进行裁剪,主要聚焦于头部区域。稍微包含一些肩膀部分也是可以的。这样的裁剪策略有助于生成更加逼真的LoRA图像。这样可以让AI充分学习人物的脸部特征,生成的LoRA也更像。如果到时候我们训练出的LoRA生成的图片只有大头照也没关系,因为我们可以先生成其他人物的全身照,然后用LoRA生成的大头照进行换脸。 这几张斯嘉丽的图片我就是这样生成的。灵活度很高,想要什么风格就什么风格。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 4652
4652

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









