



 本文提供了一种利用Python脚本将YOLO数据集按照7:2:1的比例随机划分成训练集、验证集和测试集的方法。包括项目准备、代码实现以及对原数据集的路径进行修改。此外,还提供了两种不同划分比例的实现方式。
本文提供了一种利用Python脚本将YOLO数据集按照7:2:1的比例随机划分成训练集、验证集和测试集的方法。包括项目准备、代码实现以及对原数据集的路径进行修改。此外,还提供了两种不同划分比例的实现方式。
1.将训练集、验证集、测试集按照7:2:1随机划分
1.项目准备
1.在项目下新建一个py文件,名字就叫做splitDataset1.py
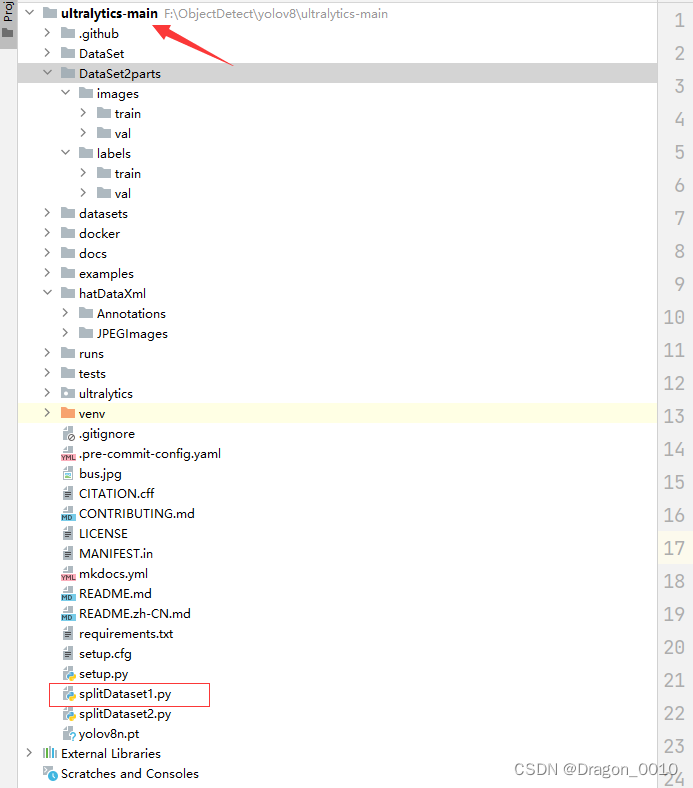
2.将自己需要划分的原数据集就放在项目文件夹下面
以我的为例,我的原数据集名字叫做hatDataXml
里面的JPEGImages装的是图片
Annotations里面装的是xml标签
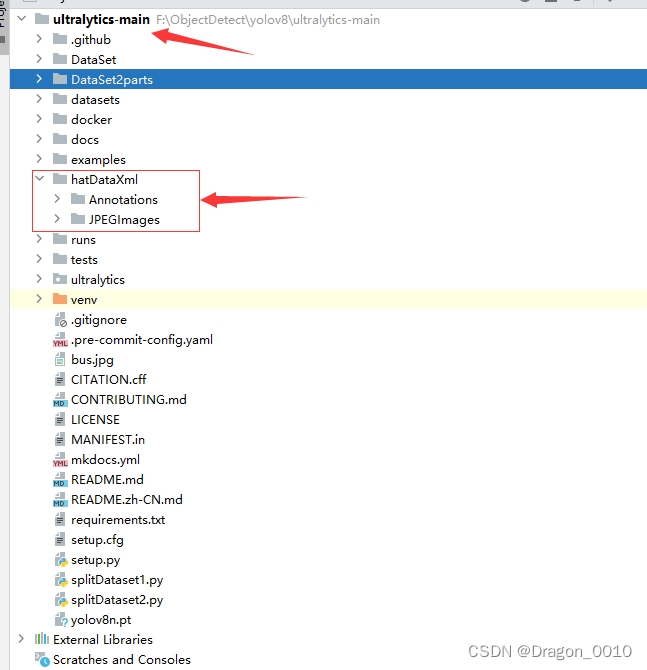
2.代码实现
# 将标签为xml格式的数据集按照7:2:1的比例划分为训练集,验证集和测试集
import os, shutil, random
from tqdm import tqdm
def split_img(img_path, label_path, split_list):
try:
Data = 'DataSet'
# Data是你要将要创建的文件夹路径(路径一定是相对于你当前的这个脚本而言的)
os.mkdir(Data)
train_img_dir = Data + '/images/train'
val_img_dir = Data + '/images/val'
test_img_dir = Data + '/images/test'
train_label_dir = Data + '/labels/train'
val_label_dir = Data + '/labels/val'
test_label_dir = Data + '/labels/test'
# 创建文件夹
os.makedirs(train_img_dir)
os.makedirs(train_label_dir)
os.makedirs(val_img_dir)
os.makedirs(val_label_dir)
os.makedirs(test_img_dir)
os.makedirs(test_label_dir)
except:
print('文件目录已存在')
train, val, test = split_list
all_img = os.listdir(img_path)
all_img_path = [os.path.join(img_path, img) for img in all_img]
# all_label = os.listdir(label_path)
# all_label_path = [os.path.join(label_path, label) for label in all_label]
train_img = random.sample(all_img_path, int(train * len(all_img_path)))
train_img_copy = [os.path.join(train_img_dir, img.split('\\')[-1]) for img in train_img]
train_label = [toLabelPath(img, label_path) for img in train_img]
train_label_copy = [os.path.join(train_label_dir, label.split('\\')[-1]) for label in train_label]
for i in tqdm(range(len(train_img)), desc='train ', ncols=80, unit='img'):
_copy(train_img[i], train_img_dir)
_copy(train_label[i], train_label_dir)
all_img_path.remove(train_img[i])
val_img = random.sample(all_img_path, int(val / (val + test) * len(all_img_path)))
val_label = [toLabelPath(img, label_path) for img in val_img]
for i in tqdm(range(len(val_img)), desc='val ', ncols=80, unit='img'):
_copy(val_img[i], val_img_dir)
_copy(val_label[i], val_label_dir)
all_img_path.remove(val_img[i])
test_img = all_img_path
test_label = [toLabelPath(img, label_path) for img in test_img]
for i in tqdm(range(len(test_img)), desc='test ', ncols=80, unit='img'):
_copy(test_img[i], test_img_dir)
_copy(test_label[i], test_label_dir)
def _copy(from_path, to_path):
shutil.copy(from_path, to_path)
def toLabelPath(img_path, label_path):
img = img_path.split('\\')[-1]
label = img.split('.jpg')[0] + '.xml' # 因为这个数据集的标签是xml格式,所以将这里改成xml,如果标签格式是txt格式,就将这里改成txt
return os.path.join(label_path, label)
def main():
# 需要修改的地方:装图片的文件夹以及装标签的文件夹
img_path = 'hatDataXml/JPEGImages'
label_path = 'hatDataXml/Annotations'
split_list = [0.7, 0.2, 0.1] # 数据集划分比例[train:val:test]
split_img(img_path, label_path, split_list)
if __name__ == '__main__':
main()
3.需要修改的地方
1.代码65行,如果你的标签格式是txt,就将这里的xml改成txt即可
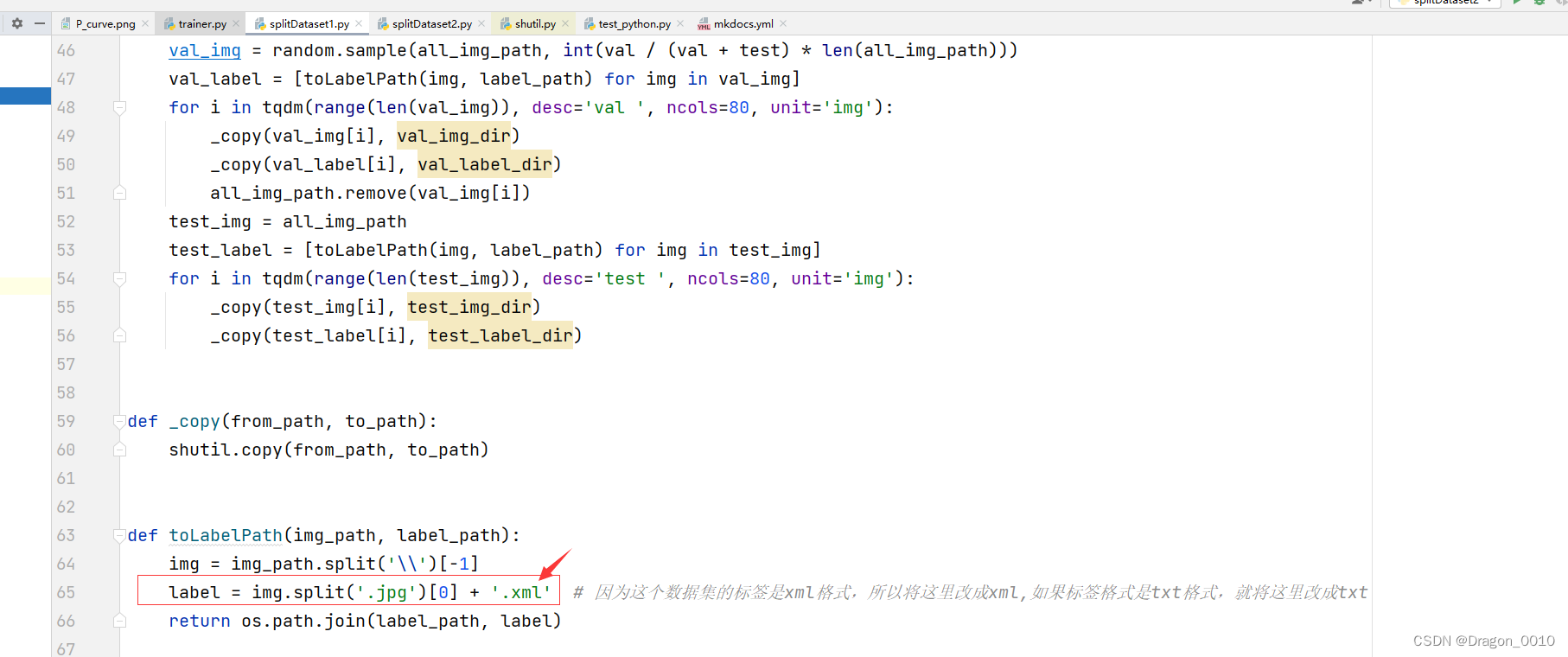
2.代码71,72行,将原数据集的图片路径和标签路径填写在这里
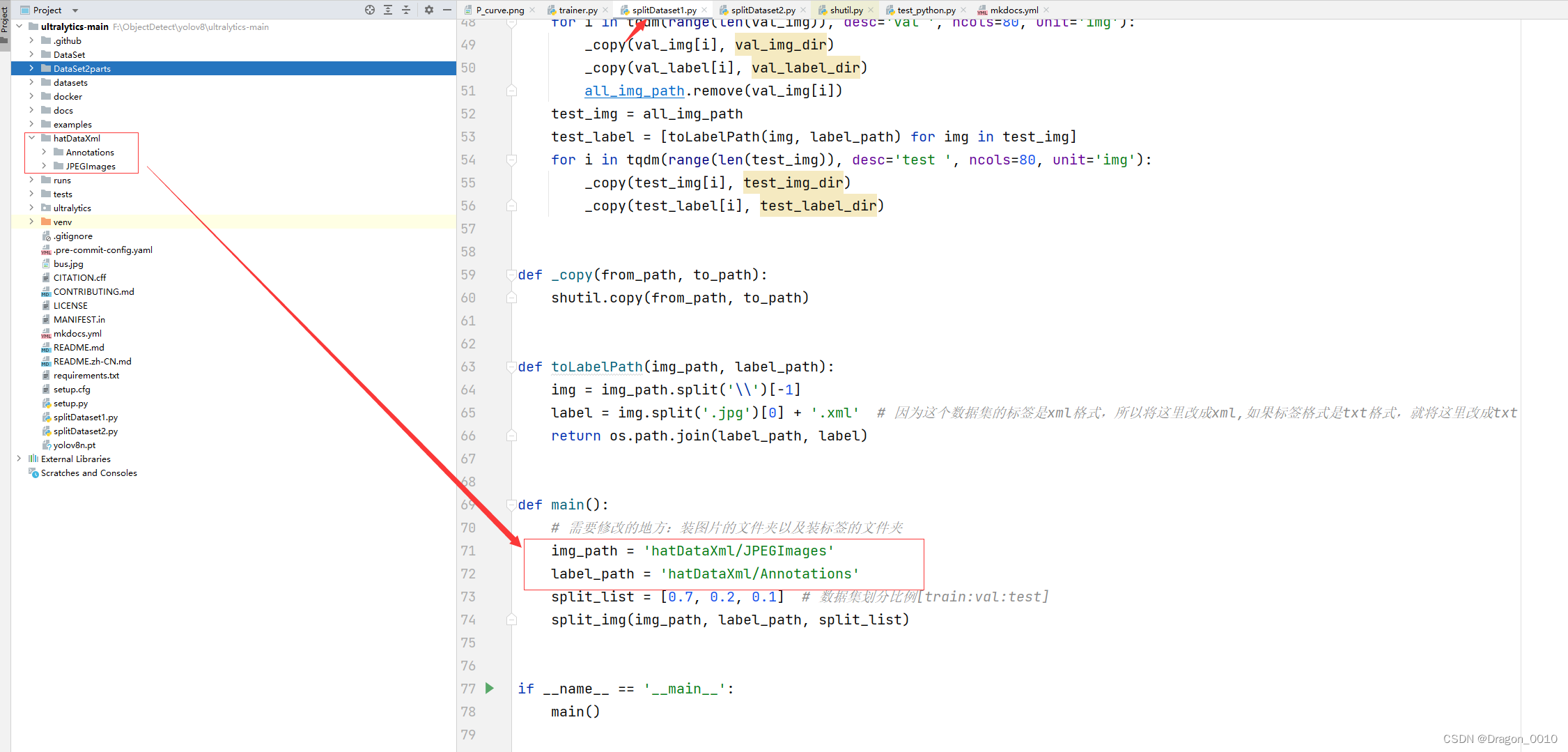
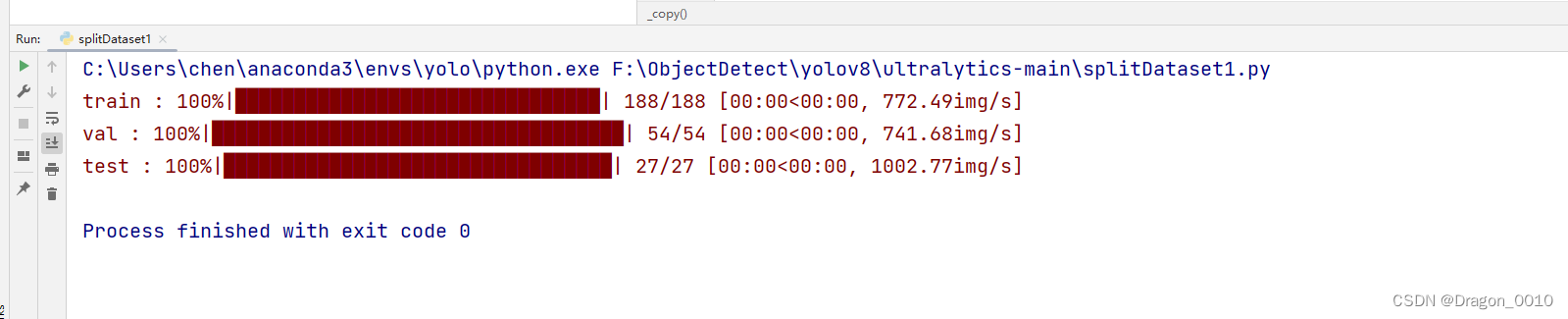
4.直接运行splitDataset1.py,转换成功
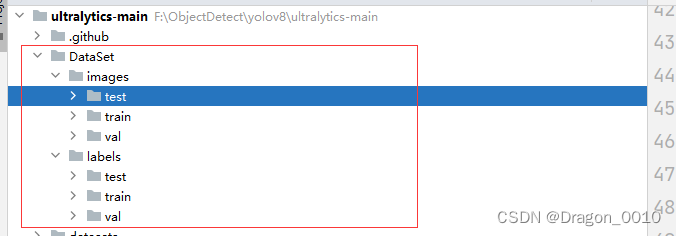
2.将训练集、验证集按照8:2随机划分
在项目下新建一个py文件,名字叫做splitDataset2.py
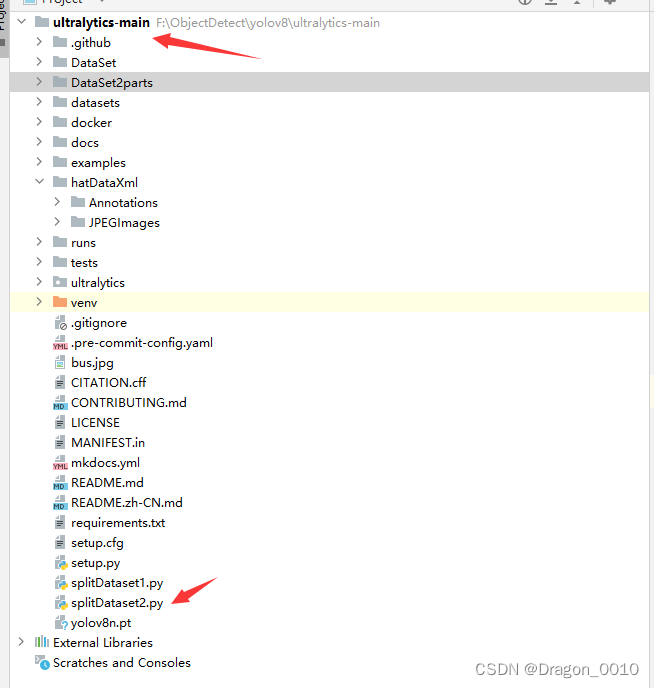
1.代码实现
# 将标签格式为xml的数据集按照8:2的比例划分为训练集和验证集
import os
import shutil
import random
from tqdm import tqdm
def split_img(img_path, label_path, split_list):
try: # 创建数据集文件夹
Data = 'DataSet2parts'
os.mkdir(Data)
train_img_dir = Data + '/images/train'
val_img_dir = Data + '/images/val'
# test_img_dir = Data + '/images/test'
train_label_dir = Data + '/labels/train'
val_label_dir = Data + '/labels/val'
# test_label_dir = Data + '/labels/test'
# 创建文件夹
os.makedirs(train_img_dir)
os.makedirs(train_label_dir)
os.makedirs(val_img_dir)
os.makedirs(val_label_dir)
# os.makedirs(test_img_dir)
# os.makedirs(test_label_dir)
except:
print('文件目录已存在')
train, val = split_list
all_img = os.listdir(img_path)
all_img_path = [os.path.join(img_path, img) for img in all_img]
# all_label = os.listdir(label_path)
# all_label_path = [os.path.join(label_path, label) for label in all_label]
train_img = random.sample(all_img_path, int(train * len(all_img_path)))
train_img_copy = [os.path.join(train_img_dir, img.split('\\')[-1]) for img in train_img]
train_label = [toLabelPath(img, label_path) for img in train_img]
train_label_copy = [os.path.join(train_label_dir, label.split('\\')[-1]) for label in train_label]
for i in tqdm(range(len(train_img)), desc='train ', ncols=80, unit='img'):
_copy(train_img[i], train_img_dir)
_copy(train_label[i], train_label_dir)
all_img_path.remove(train_img[i])
val_img = all_img_path
val_label = [toLabelPath(img, label_path) for img in val_img]
for i in tqdm(range(len(val_img)), desc='val ', ncols=80, unit='img'):
_copy(val_img[i], val_img_dir)
_copy(val_label[i], val_label_dir)
def _copy(from_path, to_path):
shutil.copy(from_path, to_path)
def toLabelPath(img_path, label_path):
img = img_path.split('\\')[-1]
label = img.split('.jpg')[0] + '.xml'
return os.path.join(label_path, label)
def main():
img_path = 'hatDataXml/JPEGImages'
label_path = 'hatDataXml/Annotations'
split_list = [0.8, 0.2] # 数据集划分比例[train:val]
split_img(img_path, label_path, split_list)
if __name__ == '__main__':
main()
2.需要修改的地方
跟上面的一样,如果标签类型不一样就修改标签类型,然后修改原数据集的图片路径以及标签路径。
3.结果展示

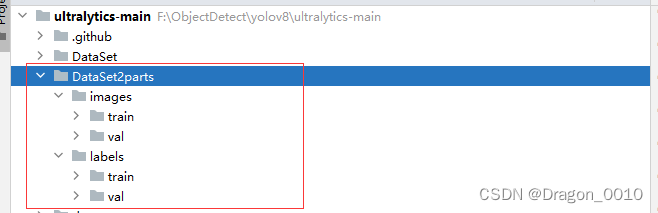


















 871
871









 到【灌水乐园】发言
到【灌水乐园】发言







