






 本文介绍了爬虫相关知识,包括通用、聚焦、增量式爬虫的使用场景,以及反爬与反反爬机制、robots.txt协议。还阐述了HTTP协议,介绍其常用请求和响应头信息。同时讲解了HTTPS协议的三种加密方式,如对称、非对称和证书秘钥加密,并分析了非对称加密的缺点。
本文介绍了爬虫相关知识,包括通用、聚焦、增量式爬虫的使用场景,以及反爬与反反爬机制、robots.txt协议。还阐述了HTTP协议,介绍其常用请求和响应头信息。同时讲解了HTTPS协议的三种加密方式,如对称、非对称和证书秘钥加密,并分析了非对称加密的缺点。
爬虫:通过编写程序,模拟浏览器上网,然后让其去互联网抓取数据的过程。
爬虫在使用场景中的介绍:
1.通用爬虫
抓取系统重要组成部分,即抓取互联网中一整张页面数据。
2.聚焦爬虫
是建立在通用爬虫的基础上,抓取的是页面中特定的局部的内容。
3.增量式爬虫
检测网站中数据更新的情况,只会抓取或者爬取网站中最新更新出的数据。
爬虫的矛与盾:
反趴机制:
相关的门户网站通过制定相应的策略或者技术手段,防止爬虫程序进行网站数据的爬取。
反反爬策略:
爬虫程序可以通过制定相关的策略或者技术手段,破解门户网站中具备的反爬机制,从而可以获取门户网站中的数据(信息)。
robots.txt协议:
规定了网站中哪些数据可以被爬取,哪些数据不可以被爬取。(君子协议)
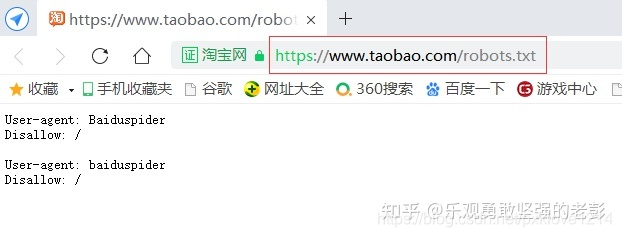
eg:
查看淘宝的robots协议:
https://www.taobao.com/robots.txt
(防君子不防小人的协议)
http协议:
即超文本传输协议
概念:就是服务器和客户端进行数据交互的一种形式。
常用请求头信息:
1.user-agent:请求载体和身份的标识。
2.connection:请求完成后是断开连接还是保持连接。
常用响应头信息:
Content-Type:服务器响应回客户端的数据类型。
HTTPS协议:
安全的http协议,即安全的超文本传输协议。
三种加密方式:
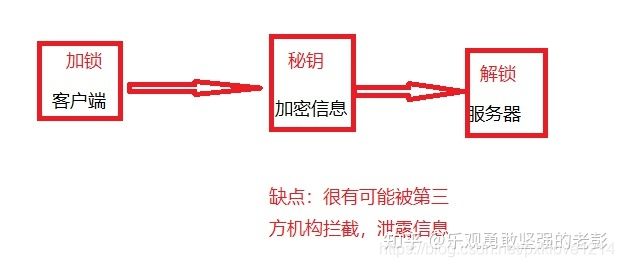
1.对称秘钥加密:
2.非对称秘钥加密:
“非对称加密”使用的时候有两把锁,一把叫做“私有秘钥”,一把是“公开秘钥”,使用非对象加密的加密方式的时候,服务器首先告诉客户端按照自己给定的公开密钥进行处理,客户端按照公开密钥加密以后,服务器接收到信息再通过自己的私有秘钥进行解密,这样做的好处就是解密的钥匙根本就不会进行传输,因此也就避免了被挟持的风险。就算公开秘钥被窃听者拿到了,它也很难进行解密,因为解密过程是相对离散对数求值,这可不是轻而易举就能做到的事。

缺点:
一.如何保证接收端向发送端发出公开秘钥的时候,发送端确保收到的是预先发送的,而不会被挟持。只要是发送秘钥,就有可能被挟持的风险。
二.非对称加密的方式效率比较低,它处理起来更为复杂,通信过程中使用就有一定的效率问题而影响通信速度。
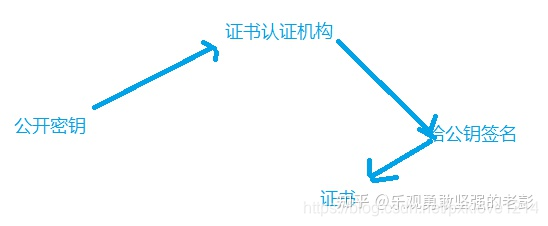
3.证书秘钥加密
由于非对称加密的缺点,其中第一个就是公钥很可能存在被挟持的情况,无法保证客户端收到的公开秘钥就是服务器发行的公开密钥。此时就引出了公开密钥的证书机制。数字证书认证机构是客户端与服务器都可信赖的第三方机制。具体传播过程如下:
一、服务器的开发者携带公开密钥,向数字证书认证机构提出公开密钥的申请,数字证书认证机构在认清申请者的身份,审核通过后,会对开发者申请的公开秘钥做数字签名,然后分配这个已签名的公开秘钥,并将秘钥放在证书里面,绑定在一起。
二、服务器将这份数字证书发送给客户端,因为客户端也认可证书机构,客户端通过数字机构中的数字签名来验证公钥的真伪,来确保服务器传过来的公开秘钥是真实的。一般情况下,证书的数字签名是很难被伪造的,这取决于认证机构的公信力。一旦确认信息无误之后,客户端就会通过公钥对报文进行加密发送,服务器接收到以后用自己的私钥进行解密。

















 485
485

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









