



本文主要介绍Amazon MSK流量成本优化的最佳实践,通过KIP-392实现Consumer(消费端)对Amazon MSK节点在同Availability Zone(AZ,可用区)内消息就近读取,可以降低跨可用区数据传输成本、提升消费端的消费效率。
Amazon MSK
https://aws.amazon.com/cn/msk/
Amazon MSK拓扑结构
Amazon MSK是完全托管、高度可用的Apache Kafka服务,为了保证Amazon MSK服务自身的高可用性,Amazon MSK的多个Kafka节点均衡分布在一个亚马逊云科技Region的多个可用区中,这样有效避免了底层硬件的单点故障或可用区级别故障导致的Amazon MSK服务不可用。
此外Amazon MSK在开源的Kafka的基础上做了一些优化和增强,在100%兼容Kafka的基础上还额外提供分层存储、自动存储扩展、自动分区管理、Amazon MSK Serverless、节点配置灵活调整以及Amazon Graviton CPU等特色功能。这些功能给客户带来了高性能、低成本、灵活可靠、免运维的Kafka使用体验。
创建Amazon MSK的时候,需要选择可用区的数量(至少为2),并指定每个可用区中的节点数量,因此Amazon MSK的节点总是在可用区中处于均衡分布状态。
如下图是一个3可用区,每个可用区中2个节点的Amazon MSK集群结构:
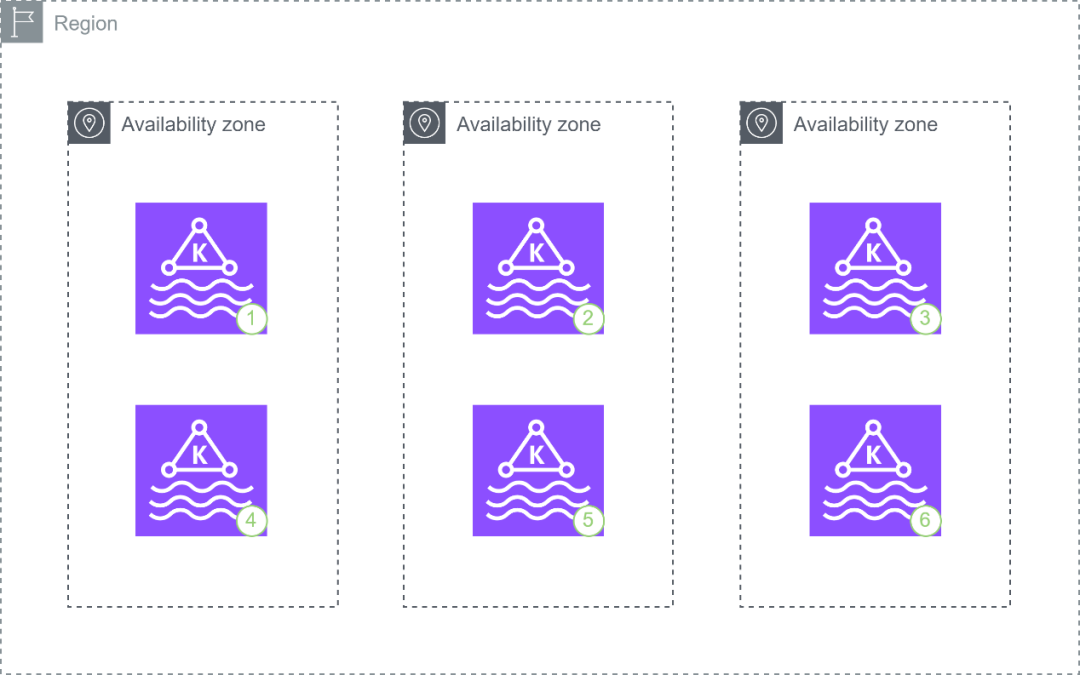
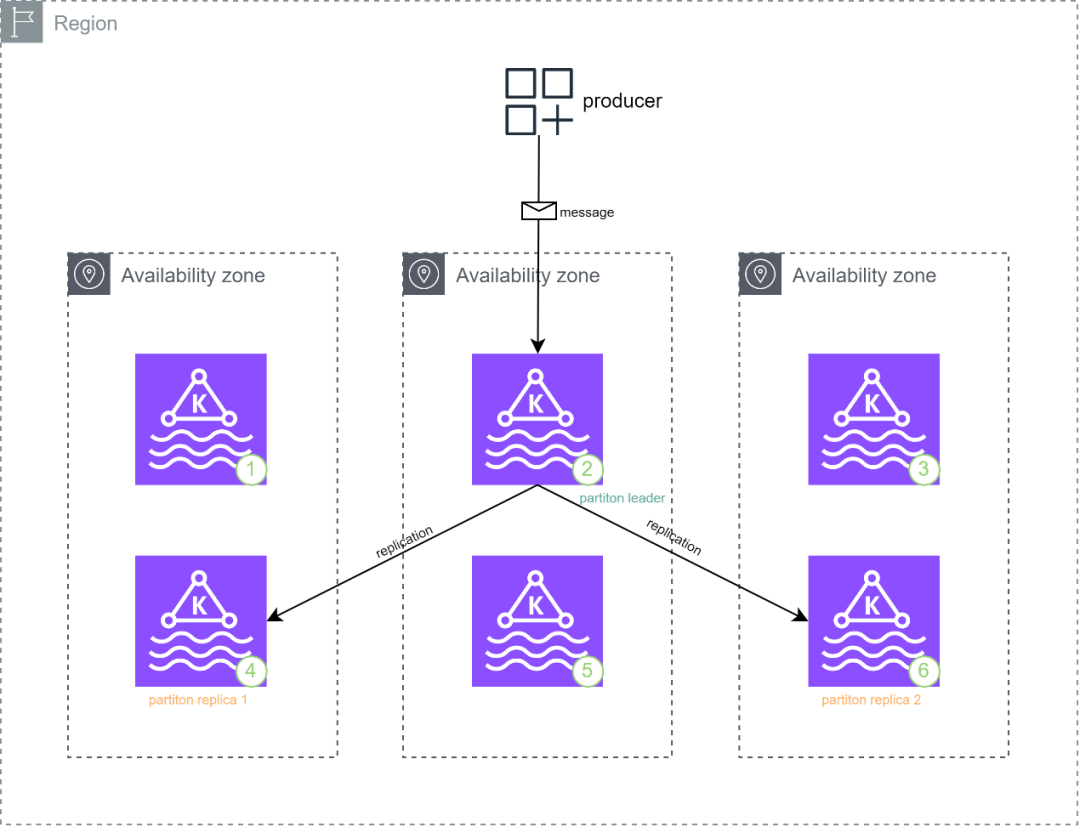
按照Amazon MSK最佳实践和Amazon MSK可靠性最佳实践为Kafka中的主题设置了分区的默认replication factor为3、in-sync replicas为2时,Producer(写入端)向Amazon MSK写入的消息会先送达到分区主副本所在的节点,然后消息会在Amazon MSK集群内部自动向另外的2台分区副本所在的节点同步;只有这个分区所处的3台节点中的至少2个确认写入时这条消息才被认为是committed。
通过设置Amazon MSK集群中主题的分区多副本备份和多数副本确认机制,结合写入端的acks=all能保证Amazon MSK集群中消息的可靠性。
Amazon MSK最佳实践
https://docs.aws.amazon.com/zh_cn/msk/latest/developerguide/bestpractices.html
写入端写入消息的示意图如下:
在默认情况下,消费Amazon MSK中的消息和开源的Apache Kafka并无差别,写入端向主题中发送的消息可以大致均衡的分布在这个主题的多个分区上;每个分区的主副本分区负责承载写入端的写操作和消费端的读操作,其他的副本分区在Kafka集群内部同步主副本的消息,副本分区只负责保证数据的可靠性但是不承载读写操作压力。
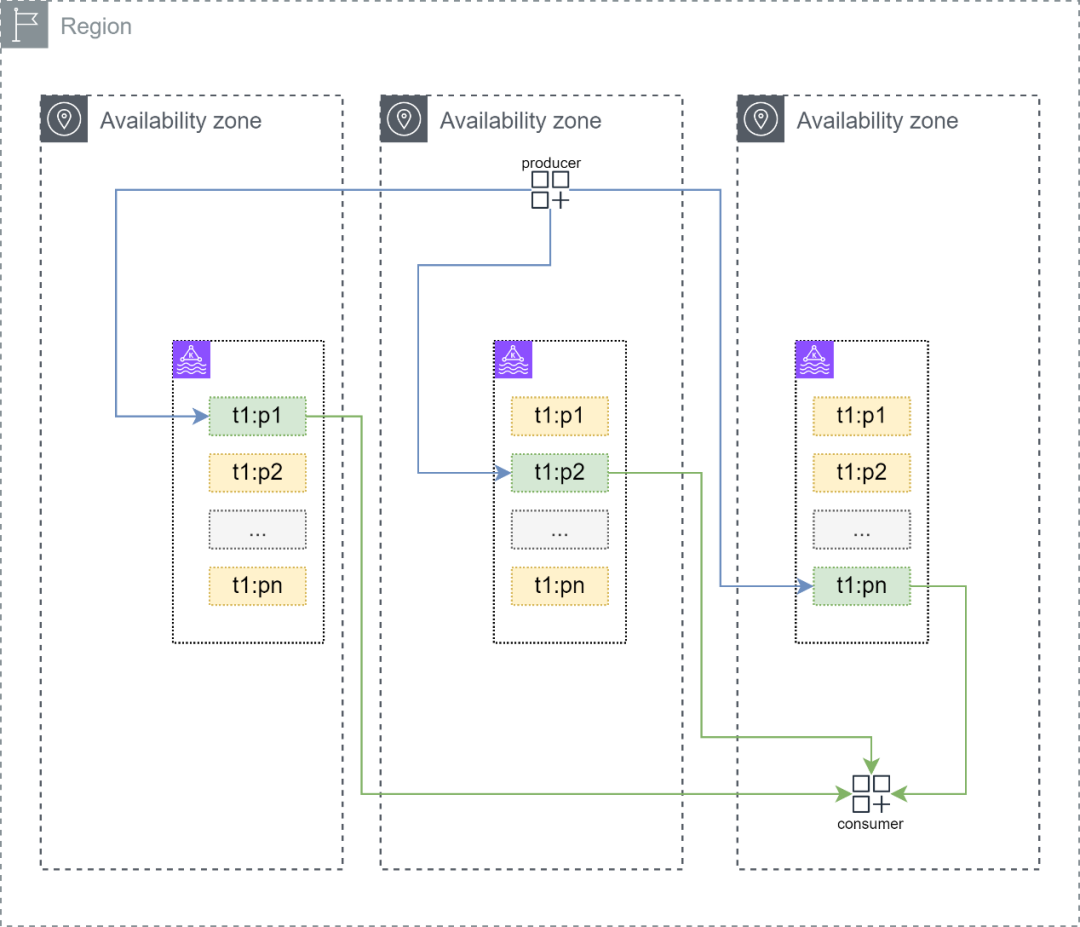
经过上面的拓扑分析,可以发现在理想情况下上述的结构可以在多个节点间均匀地分散读写压力,但也存在以下3个细节问题:
1.存在跨可用区流量成本,结合network traffic cost可以发现对写入端产生的一批消息而言,大致有2/3的消息是跨可用区被消费端消费的。理论上当可用区为n时,可能有1-1/n的消息被消费时产生额外的跨可用区流量成本。
2.当消费端跨可用区读取消息时,可能会有轻微的网络延迟上升。
3.极端情况下,如果用户对消息的分区key设置不合理时会产生分区倾斜,主副本分区会承载更大的读写压力并加剧上述1、2项问题。当然在任意情况下都要合理设置分区key来避免倾斜问题。
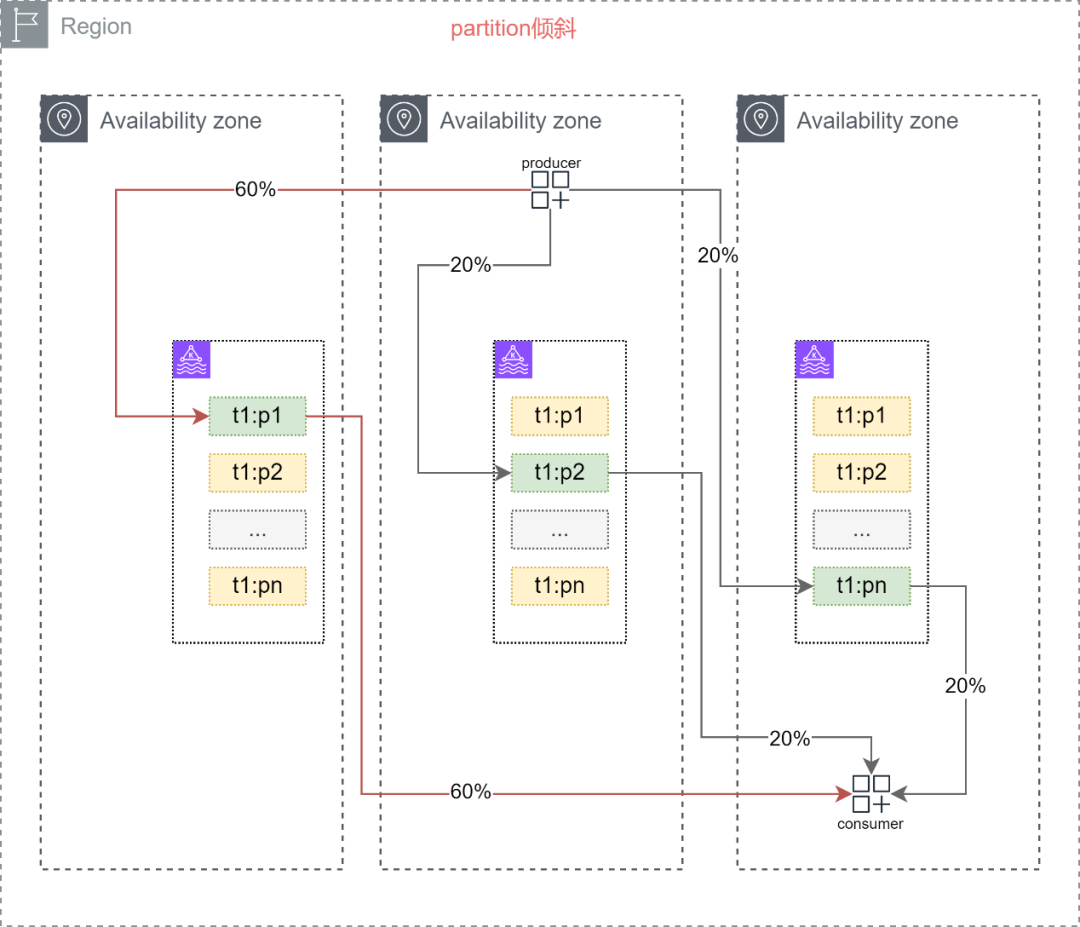
Amazon MSK支持
KIP-392机架感知
KIP-392在Apache Kafka 2.4中被引入,旨在通过机架感知来为消费端提供同机架内的消息消费能力;这会降低消费端跨机架消费消息的网络延迟、充分利用同机架的更高的网络带宽提升消费速度。Amazon MSK从2.4.1开始引入KIP-392特性并提供KIP-480粘性分区器提升消费组分区分配效率,详情请参阅下方链接:
Amazon MSK增加对Apache Kafka版本2.4.1的支持
https://aws.amazon.com/cn/about-aws/whats-new/2020/04/amazon-msk-adds-support-for-apache-kafka-version-2-4-1/
利用KIP-392新特性,Amazon MSK集群的消费端,可以在同可用区内就近消费分区中的数据,该特性允许消费端从副本分区所在的节点进行数据拉取并消费,而以往消费端只能在主副本分区上进行数据拉取。
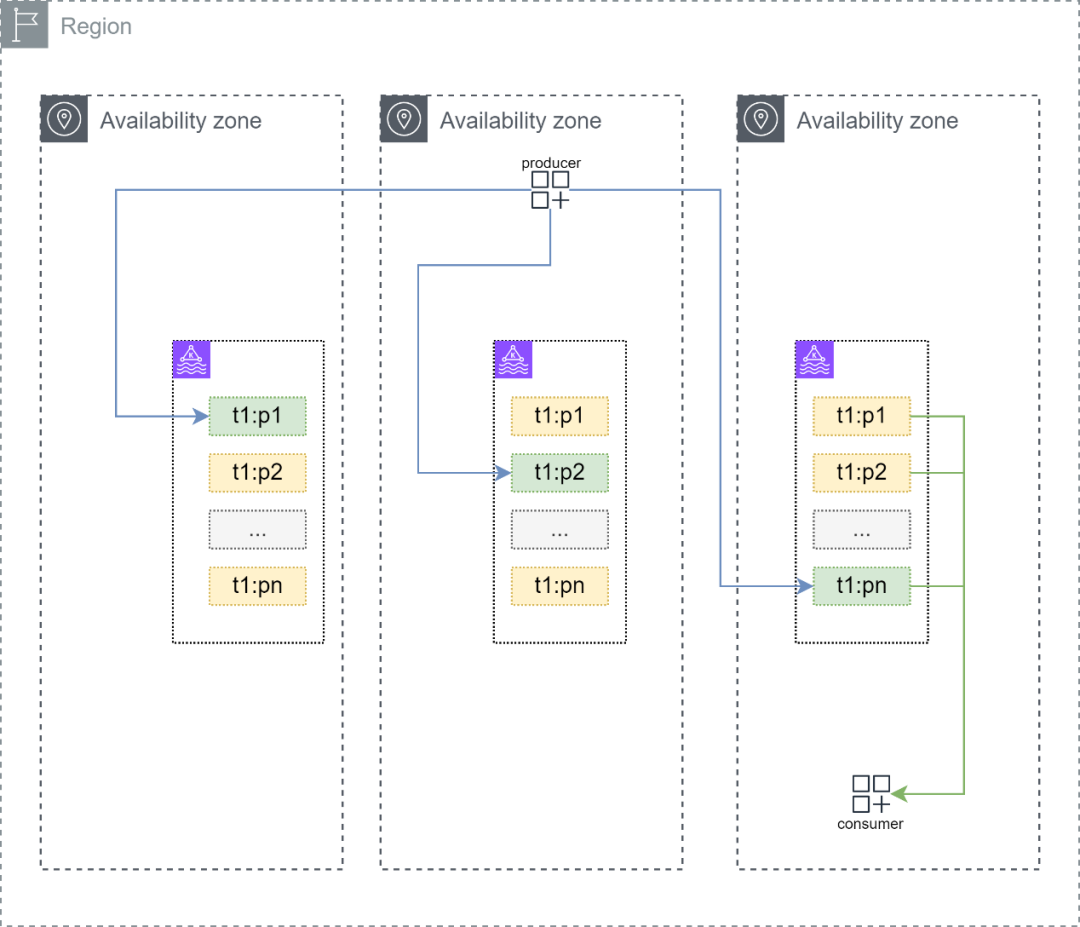
通过上图,可以发现消费端消费消息的流量可以保持在同可用区内,理论上这将消费端产生的流量费降为0。在某些情况下消费端所在的可用区中没有节点或者节点短暂处于维护期时,这个消费端的消费逻辑可以回退到标准的Apache Kafka状态。
使用spring integration kafka
完成就近读取
要正确启用KIP-392,必须让节点和消费端间完成rack协商,这需要节点和消费端都拥有正确的rack id消息。在Amazon MSK中,rack id就是可用区id,实际上可用区id是Amazon EC2实例元数据的一部分。
Amazon EC2实例元数据
https://docs.aws.amazon.com/zh_cn/AWSEC2/latest/UserGuide/ec2-instance-metadata.html
为Amazon MSK节点
开启KIP-392机架感知
Amazon MSK中节点自带了可用区id,需要先设置好Amazon MSK集群配置,加上以下代码来让Amazon MSK集群使用RackAwareReplicaSelector正确匹配到消费端传来的rack id。配置修改好后需要重启Amazon MSK集群生效配置。
replica.selector.class=org.apache.kafka.common.replica.RackAwareReplicaSelector
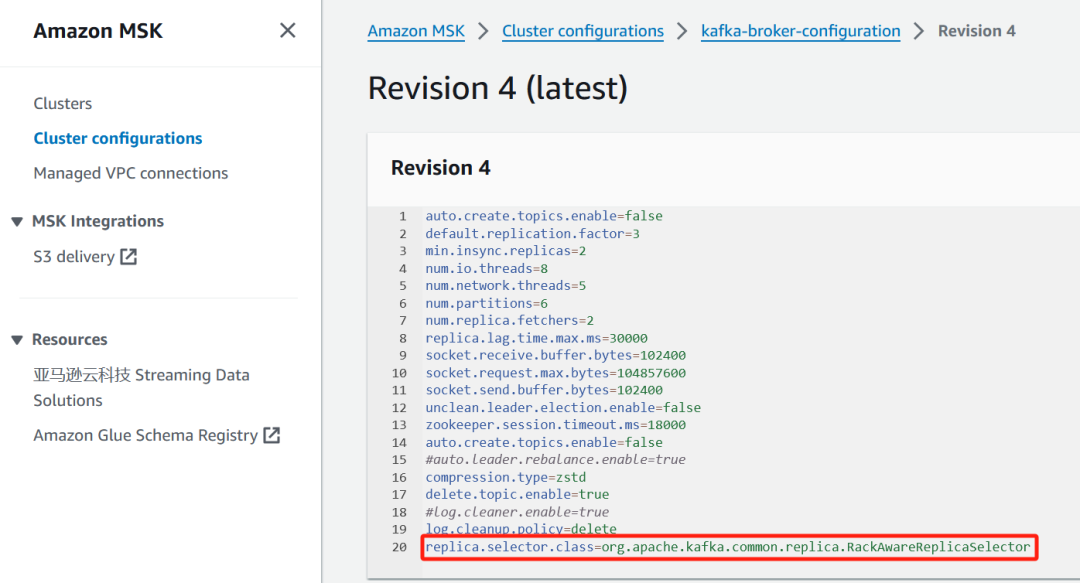
为消费端开启KIP-392机架感知
按照KIP-392的规范,在节点设置好RackAwareReplicaSelector后,消费端只需要传入rack id即可,目前大多数语言的Kafka客户端都支持该功能,比如java、go、python等。
下面以java为例进行演示,首先一个亚马逊云科技上运行的程序无论是在Amazon EC2还是容器或者其他的地方,它的宿主机必然是处于某一个亚马逊云科技Region内的某个可用区的。但是为了保证高可用性,一般需要对这个程序进行多可用区部署,程序所在的可用区id就是一个变量,所以无法将可用区id写死在配置文件里面或者在编译阶段固定下来。最佳的方式是在程序启动时做到动态加载。
可以使用Amazon SDK或者直接使用http访问Amazon EC2实例的实例元数据来获取可用区id。对Amazon Java SDK v2而言,可以使用Ec2MetadataClient来读取它。
访问Amazon EC2实例的实例元数据
https://docs.aws.amazon.com/zh_cn/AWSEC2/latest/UserGuide/instancedata-data-retrieval.html
Amazon Java SDK v2
https://docs.aws.amazon.com/zh_cn/sdk-for-java/latest/developer-guide/home.html
具体的核心代码为:
Ec2MetadataClient ec2MetadataClient = Ec2MetadataClient.create()Ec2MetadataResponse response = ec2MetadataClient.get("/latest/metadata/placement/availability-zone-id");String availabilityZoneId = response.asString();左右滑动查看完整示意
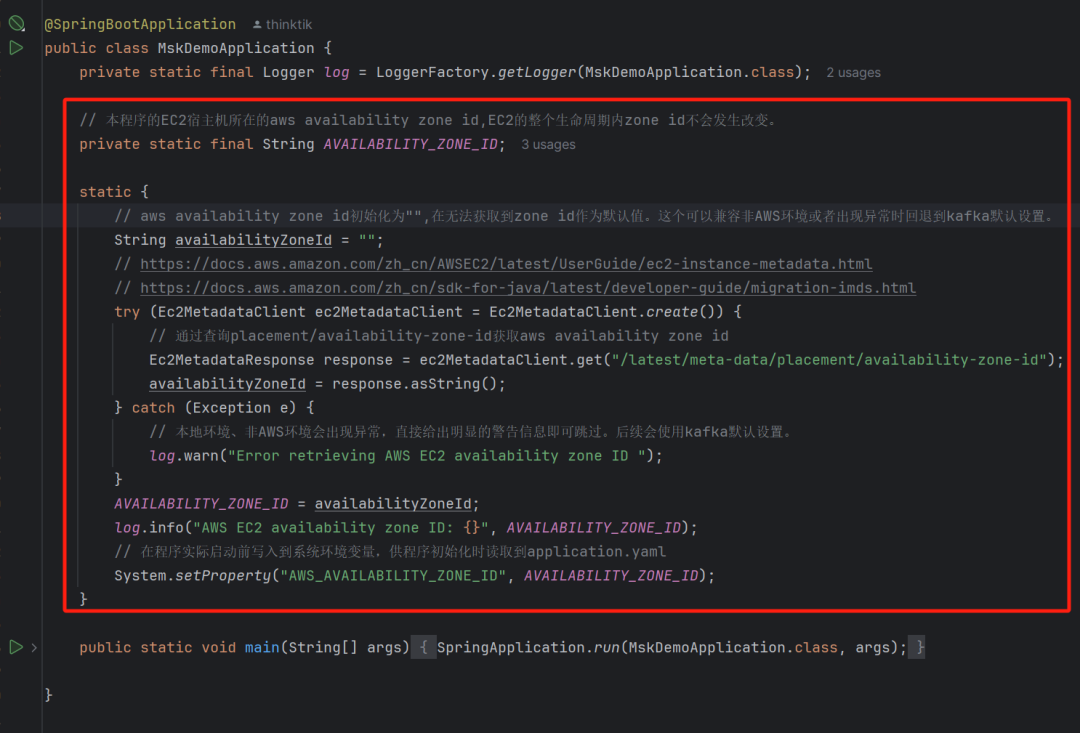
在上图中,使用核心代码读取了程序所在的Amazon EC2宿主机上的metadata后得到了可用区id,上述代码得到可用区id后立即将它设置为环境变量,名称为AVAILABILITY_ZONE_ID,代码片段会在spring程序容器加载前执行,发生于Kafka客户端初始化前。
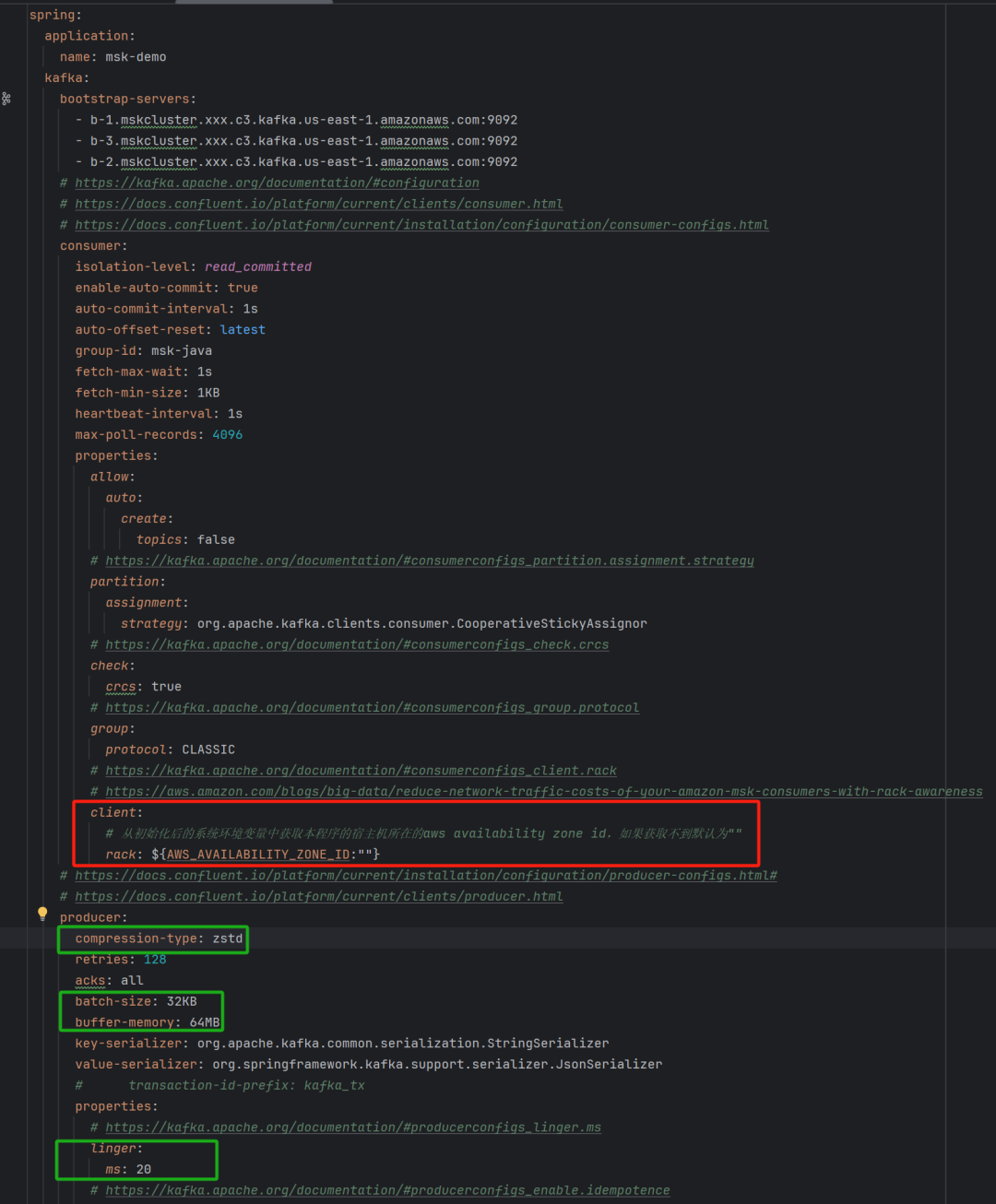
然后在spring的application.yaml配置文件中设置client rack,spring启动时会读取AVAILABILITY_ZONE_ID环境变量来初始化Kafka客户端,从而完成了全部的KIP-392设置,如下图红色部分。图中绿色部分也是推荐的最佳实践,通过开启写入端消息压缩可以在牺牲少量CPU的情况下减少客户端和Amazon MSK节点间的数据传输量、减少Amazon EC2的带宽消耗、减少Amazon MSK的数据存储成本。
最后将以下代码的日志设置为debug级别,这会打印关键的调试信息。
org.apache.kafka.clients.consumer.internals.AbstractFetch

编译后运行的日志如下:
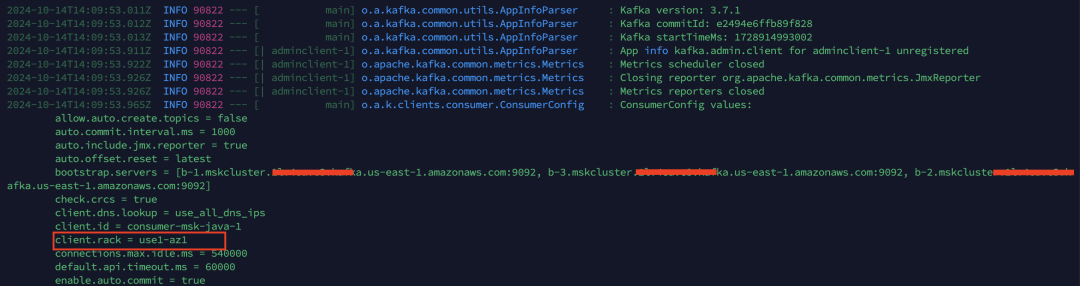
启动时程序打印出了消费端的连接设置,可以看到,正确地得到了可用区id。
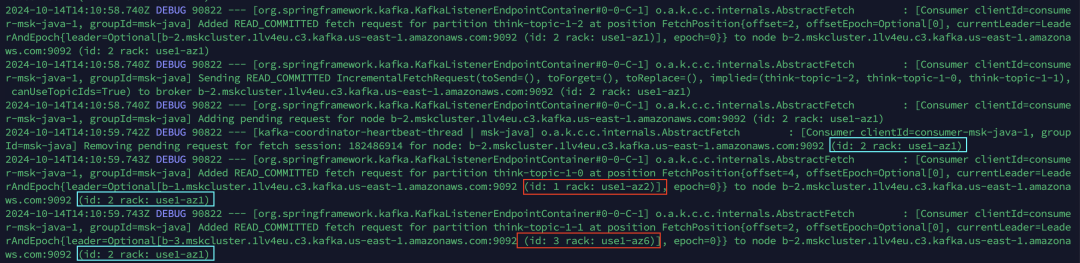
持续观察debug日志,会看到消费端会不断地在同可用区id内拉取committed后的消息。
总结
KIP-392是一个很实用的Kafka特性,当消费Amazon MSK中的消息时,通过它提供的机架感知技术可以实现就近数据拉取。和以前从主副本分区拉取相比,它减少了主副本分区所在的节点的压力并消除了跨可用区流量费,是一个非常经济高效的流量降本技术。如果结合消息压缩功能,使用Amazon MSK的整体流量成本会进一步的降低。

参考链接
1.Reduce network traffic costs of your Amazon MSK consumers with rack awareness
https://aws.amazon.com/cn/blogs/big-data/reduce-network-traffic-costs-of-your-amazon-msk-consumers-with-rack-awareness/
2.KIP-392: Allow consumers to fetch from closest replica
https://cwiki.apache.org/confluence/display/KAFKA/KIP-392%3A+Allow+consumers+to+fetch+from+closest+replica
3.Amazon MSK增加对Apache Kafka版本2.4.1的支持
https://aws.amazon.com/cn/about-aws/whats-new/2020/04/amazon-msk-adds-support-for-apache-kafka-version-2-4-1/
4.Overview of Data Transfer Costs for Common Architectures
https://aws.amazon.com/cn/blogs/architecture/overview-of-data-transfer-costs-for-common-architectures/
5.Consuming messages from closest replicas in Apache Kafka 2.4.0 and AMQ Streams
https://developers.redhat.com/blog/2020/04/29/consuming-messages-from-closest-replicas-in-apache-kafka-2-4-0-and-amq-streams
6.Improving Performance and Reducing Cost Using Availability Zone Affinity
https://aws.amazon.com/blogs/architecture/improving-performance-and-reducing-cost-using-availability-zone-affinity/
7.Amazon MSK可靠性最佳实践
https://aws.amazon.com/cn/blogs/china/msk-reliability-best-practice/
8.如何通过互联网安全地访问Amazon MSK集群
https://aws.amazon.com/cn/blogs/china/how-to-safely-access-amazon-managed-streaming-for-apache-kafka-amazon-msk-cluster-through-the-internet-i/
9.Message compression in Apache Kafka
https://developer.ibm.com/articles/benefits-compression-kafka-messaging/
10.Apache Kafka Message Compression
https://www.confluent.io/blog/apache-kafka-message-compression/
本篇作者

罗新宇
亚马逊云科技解决方案架构师,在架构设计与开发领域有非常丰富的实践经验,目前致力于Serverless在云原生架构中的应用。
我们正处在Agentic AI爆发前夜。企业要从"成本优化"转向"创新驱动",通过完善的数据战略和AI云服务,把握全球化机遇。亚马逊将投入1000亿美元在AI算力、云基础设施等领域,通过领先的技术实力和帮助“中国企业出海“和”服务中国客户创新“的丰富经验,助力企业在AI时代突破。

















 298
298

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









