



实验目的
1.掌握关系数据在大数据中的应用
2.掌握关系数据可视化方法
3. python 程序实现图
实验原理
在传统的观念里面,一般都是致力于寻找一切事情发生的背后的原因。现在要做的是尝试着探索事物的相关关系,而不再关注难以捉摸的因果关系。这种相关性往往不能告诉读者事物为何产生,但是会给读者一个事物正在发生的提醒。关系数据很容易通过数据进行验证的,也可以通过图表呈现,然后引导读者进行更加深入的研究和探讨。分析数据的时候,可以从整体进行观察,或者关注下数据的分布。数据间是否存在重叠
或者是否毫不相干?也可以更宽的角度观察各个分布数据的相关关系。其实最重要的一点,就是数据进行可视化后,呈现眼前的图表,它的意义何在。是否给出读者想要的信息还是结果让读者大吃一惊?
就关系数据中的关联性,分布性。进行可视化,有散点图,直方图,密度分布曲线,气泡图,散点矩阵图等等。本次试验主要是直方图,密度图,散点图。直方图是反应数据的密集程度,是数据分布范围的描述,与茎叶图类似,但是不会具体到
某一个值,是一个整体分布的描述。密度图可以了解到数据分布的密度情况。密度图可以了解到数据分布的密度情况。散点图将序列显示为一组点。值由点在图表中的位置表示。散点图
通常用于比较跨类别的聚合数据。
实验环境
OS:Windows 11
python:3.11
pycharm:2024.1
实验步骤
一、数据源:讲师提供crimeRatesByState2005.csv文件。
1、数据集基本信息
数据规模:
包含 51 行(50 个州 + 1 个全国均值行 “United States” + 1 个异常行 “District of Columbia”)。
8 列:state(州名)、7 种犯罪类型(murder, forcible_rape, robbery, aggravated_assault, burglary, larceny_theft, motor_vehicle_theft)、population(人口)。
犯罪类型说明(单位:每 10 万人犯罪率,推测):
murder:谋杀率
forcible_rape:强奸率
robbery:抢劫罪
aggravated_assault:严重袭击率
burglary:入室盗窃率
larceny_theft:盗窃率
motor_vehicle_theft:机动车盗窃率
2、关键数据特征
异常值与特殊行
“United States” 行:全国均值,如 murder 均值为 5.6,burglary 均值为 726.7,可作为基准对比各州数据。
“District of Columbia” 行:显著异常,murder 率 35.4(远超其他州,次高的 Louisiana 为 9.9),motor_vehicle_theft 率 1402.3,可能因城市规模或特殊管理模式导致。
二、环境配置
本实验所需pyecharts和seaborn两个数据可视化化的基本库以及matplotlib这种基础库。
安装指令如下
pip install 库名
三、实验内容
1、请使用 seaborn 模块中的 jointplot 方法将散点图,密度分布图和直方图合为一体,数据选取murder列及burglary列,探究两种犯罪类型的相关关系,效果如下:
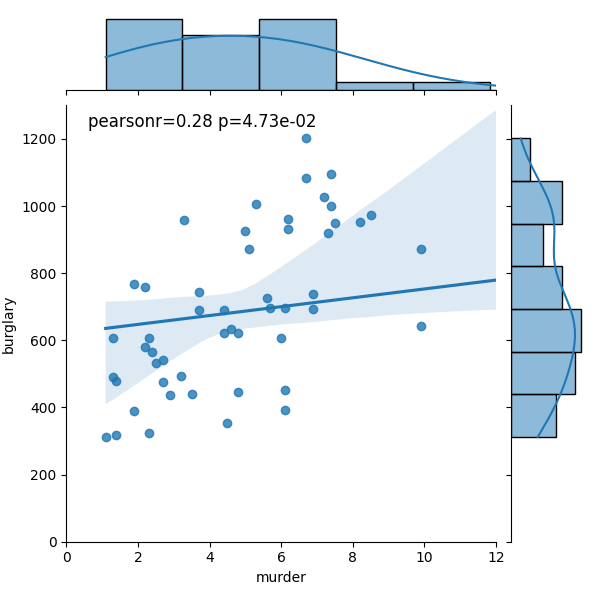
这张图展示了谋杀率(murder)与入室盗窃率(burglary)之间的关系,具体分析如下:
散点图:图中蓝色散点代表各州市的数据点,每个点对应一个州的谋杀率和入室盗窃率。散点从左下到右上的分布趋势,初步表明两者存在正相关关系。
拟合线:图中蓝色直线为线性拟合线,其正斜率进一步支持谋杀率与入室盗窃率的正相关趋势。
统计值:
pearsonr=0.28:表示皮尔逊相关系数为 0.28,说明两者呈弱正相关。
p=4.73e - 02(即 0.0473):p 值小于 0.05,表明这种弱正相关在统计上具有显著性,非偶然所得。
边缘分布:
图上方和右侧的小图分别为谋杀率和入室盗窃率的边缘分布,展示了单个变量的分布形态,帮助理解变量自身的特征。
综上,该图表明谋杀率与入室盗窃率之间存在弱但统计显著的正相关关系,即谋杀率较高的州,入室盗窃率也倾向于较高,但这种关联并不强烈。
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
from scipy.stats import pearsonr
# 读取数据
try:
data = pd.read_csv("E:/technology/The_fifth_theaper/crimeRatesByState2005.csv")
except FileNotFoundError:
print("未找到指定的 CSV 文件,请检查文件路径是否正确。")
else:
# 计算 Pearson 相关系数和 p 值
corr, p_value = pearsonr(data['murder'], data['burglary'])
# 使用 seaborn 模块中的 jointplot 方法将散点图、密度分布图和直方图合为一体
g = sns.jointplot(data=data, x='murder', y='burglary', kind='reg')
# 调整 X 轴和 Y 轴的坐标范围,你可以根据实际需求修改
g.ax_joint.set_xlim(0, 12)
g.ax_joint.set_ylim(0, 1300)
# 在图上添加 Pearson 相关系数和 p 值
text = f'pearsonr={corr:.2f} p={p_value:.2e}'
g.ax_joint.text(0.05, 0.95, text, transform=g.ax_joint.transAxes, fontsize=12)
plt.show()
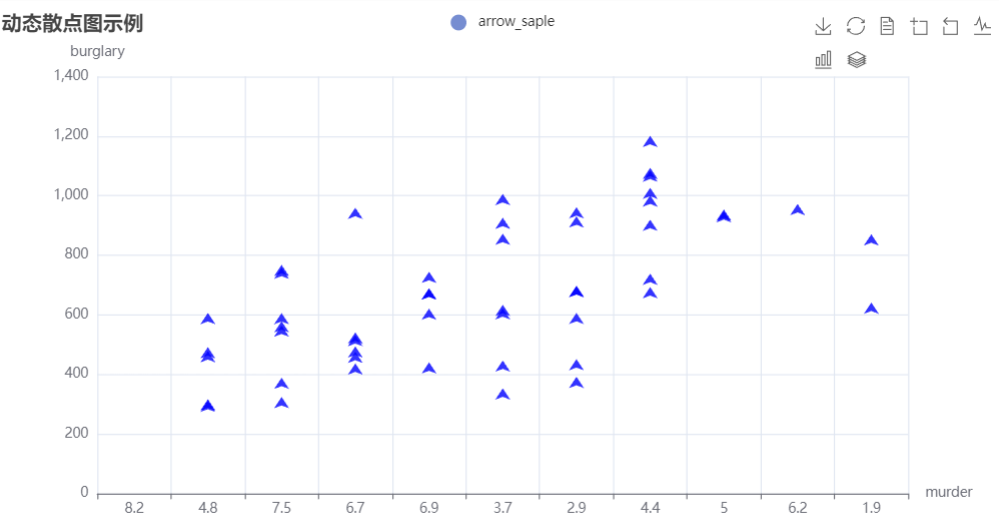
2、动态散点图
由于题目给出的实验代码与版本不兼容,本次实验使用的另外的方法完成了该要求,具体实现如下图代码所示
实现结果如下:
import pandas as pd
from pyecharts import options as opts
from pyecharts.charts import Scatter
try:
# 读取指定路径的数据文件
crime = pd.read_csv(r"E:\technology\The_fifth_theaper\crimeRatesByState2005.csv")
# 筛选数据,去除 "United States" 和 "District of Columbia"
crime2 = crime[(crime['state'] != "United States") & (crime['state'] != "District of Columbia")]
# 准备数据,添加特效信息
data = []
for x, y in zip(crime2['murder'].tolist(), crime2['burglary'].tolist()):
data.append({
"name": f"{x}-{y}",
"value": [x, y],
"symbol": "arrow",
"itemStyle": {"color": "blue"},
"effect": {
"show": True,
"period": 4,
"scale": 5,
"color": "blue"
}
})
# 创建 Scatter 图表对象
scatter = (
Scatter()
.add_xaxis(crime2['murder'].tolist())
.add_yaxis(
series_name="arrow_saple",
y_axis=data,
label_opts=opts.LabelOpts(is_show=False),
)
.set_global_opts(
title_opts=opts.TitleOpts(title="动态散点图示例"),
xaxis_opts=opts.AxisOpts(
name="murder",
min_=0,
max_=10
),
yaxis_opts=opts.AxisOpts(name="burglary"),
toolbox_opts=opts.ToolboxOpts(is_show=True)
)
)
# 渲染生成 HTML 文件到当前工作目录
scatter.render("dynamic_scatter_plot.html")
print("动态散点图已成功保存为 dynamic_scatter_plot.html")
except FileNotFoundError:
print("未找到指定的数据文件,请检查文件路径是否正确。")
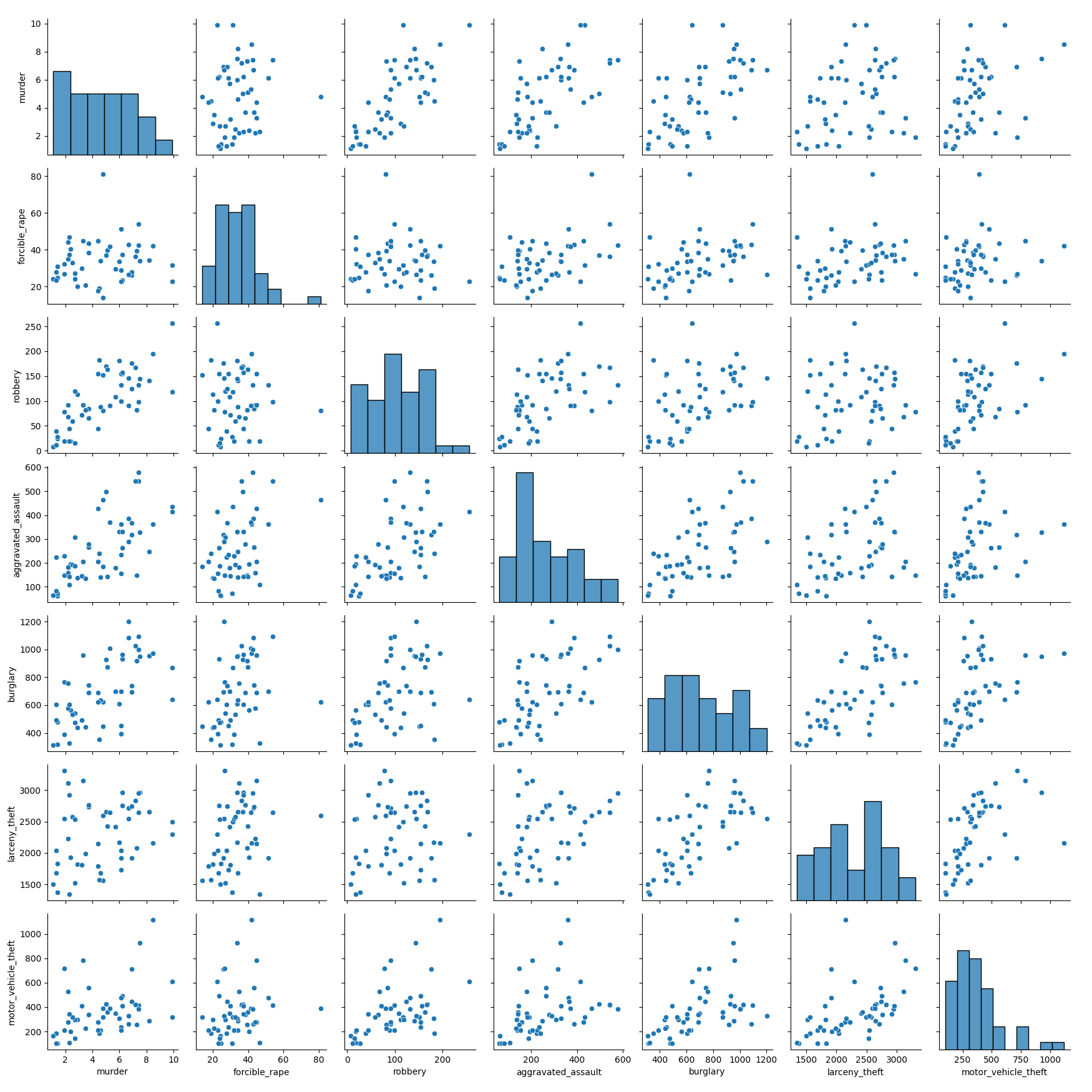
3、请使用矩阵图表示数据集中七种犯罪类型之间的相关关系(提示:请剔除 United States 和 District of Columbia 两行表示均
值和异常的数据),效果如下:
运行结果:
代码分析
库导入:
import pandas as pd:用于数据读取与处理。
import seaborn as sns:用于数据可视化,提供丰富的统计图表绘制功能。
import matplotlib.pyplot as plt:用于显示图形。
数据读取与筛选:
data = pd.read_csv(“E:\technology\The_fifth_theaper\crimeRatesByState2005.csv”):读取指定路径的犯罪数据文件。
data = data[(data[‘state’] != “United States”) & (data[‘state’] != “District of Columbia”)]:剔除表示全国均值的 “United States” 和异常的 “District of Columbia” 两行数据,使后续分析聚焦于正常州的数据。
犯罪类型数据提取:
crime_types = [‘murder’, ‘forcible_rape’, ‘robbery’, ‘aggravated_assault’, ‘burglary’, ‘larceny_theft’,‘motor_vehicle_theft’]:定义七种犯罪类型的列名。
subset_data = data[crime_types]:从原始数据中提取这七种犯罪类型的数据,便于后续分析。
自定义绘图函数:
def scatter(x, y, **kwargs):定义散点图绘制函数,基于 sns.scatterplot,用于展示两种犯罪类型之间的关系。
def hist(x, **kwargs):定义直方图绘制函数,基于 sns.histplot,用于展示单个犯罪类型的分布。
矩阵图绘制:
g = sns.PairGrid(subset_data):创建一个网格对象 g,其行列由 subset_data 的列(即七种犯罪类型)决定。
g.map_diag(hist):在网格的对角线位置(diag)绘制直方图,展示每个犯罪类型自身的分布特征。
g.map_offdiag(scatter):在网格的非对角线位置(offdiag)绘制散点图,展示每两种犯罪类型之间的关系。
plt.show():显示最终绘制的矩阵图。
结果分析
对角线(直方图):
每个对角线子图展示了一种犯罪类型的分布情况。例如,第一行第一列的直方图展示了 murder(谋杀率)的分布,可看出其取值范围和集中趋势。通过直方图能直观了解每种犯罪类型在不同州的发生频率分布特征。
非对角线(散点图):
每个非对角线子图展示了两种犯罪类型之间的关系。例如,第一行第二列的散点图展示了 murder(谋杀率)与 forcible_rape(强奸率)之间的关系,通过观察散点的分布形态(如是否呈线性趋势、是否集中等),可初步判断两者是否存在关联。整体来看,矩阵图提供了一个全面的视角,既能观察单个犯罪类型的分布,又能快速浏览不同犯罪类型之间的两两关系,为进一步分析犯罪类型间的相关性和分布特征奠定基础。
4、请使用其它合适的可视化方法探究数据集中七种犯罪类型之间的相关关系,请给出代码及运行结果
本文使用热力图和平行坐标图实现
(1)热力图
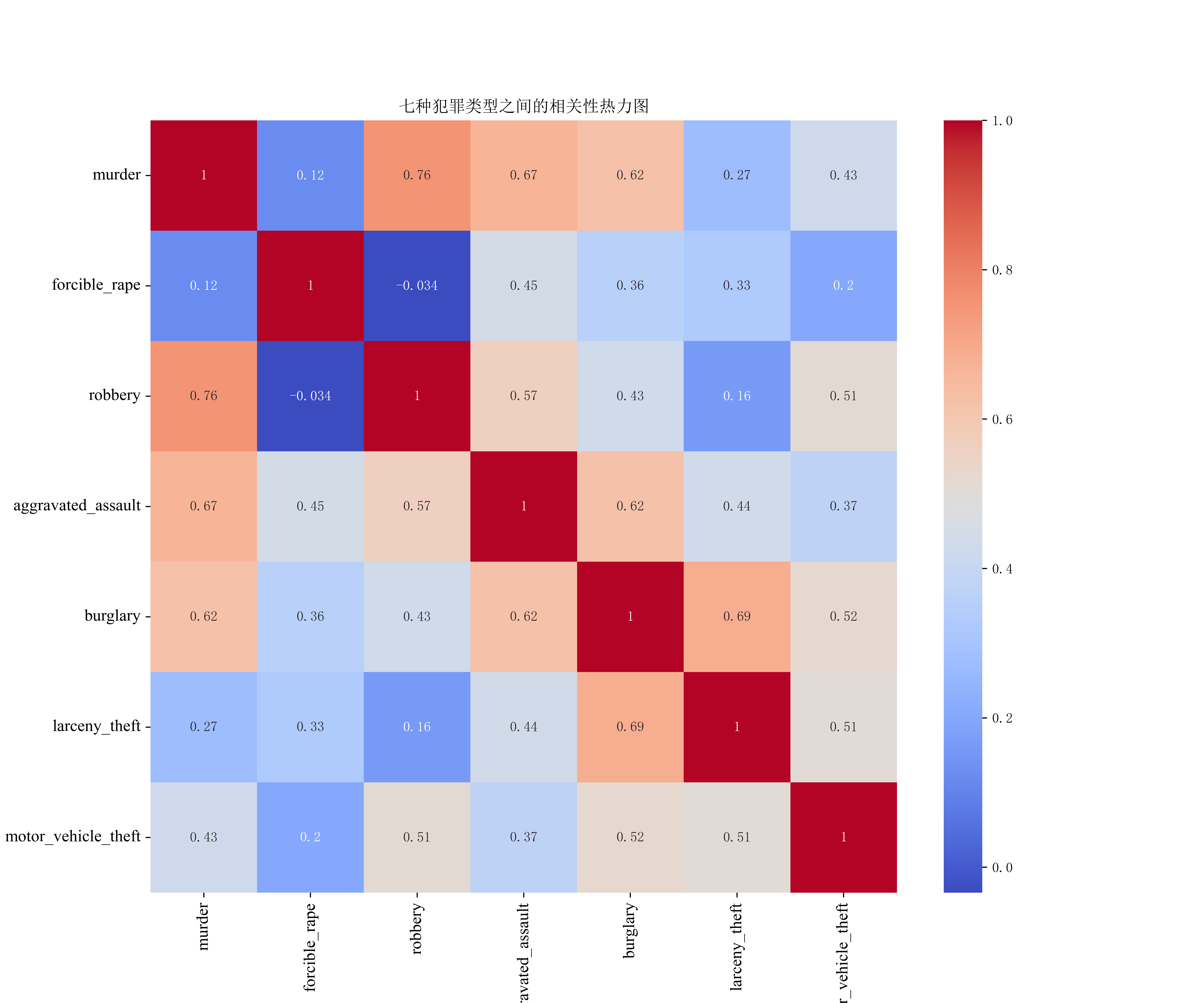
热力图分析
热力图通过颜色深浅直观展示犯罪类型间的皮尔逊相关系数:
强正相关对:
murder(谋杀)与 robbery(抢劫)相关系数 0.76,颜色较深,表明两者在数据上呈现较强正相关,可能因暴力犯罪场景存在一定重叠。
burglary(入室盗窃)与 larceny_theft(盗窃)相关系数 0.69,颜色较深,反映财产犯罪的关联性,作案动机和目标人群可能有部分重叠。
弱相关或负相关:
forcible_rape(强奸)与 robbery(抢劫)相关系数 -0.034,颜色接近蓝色,表明两者相关性极弱且接近零,说明这两种犯罪类型的发生机制和影响因素差异较大,独立性较强。
larceny_theft(盗窃)与 forcible_rape(强奸)相关系数 0.33,颜色较浅,显示两者关联较弱,进一步说明强奸犯罪与其他财产类犯罪的低关联性。
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
from pandas.plotting import parallel_coordinates
from matplotlib.font_manager import FontProperties
# 读取数据
data = pd.read_csv(r"E:\technology\The_fifth_theaper\crimeRatesByState2005.csv")
# 剔除 United States 和 District of Columbia 两行数据
data = data[(data['state'] != "United States") & (data['state'] != "District of Columbia")]
# 七种犯罪类型列名
crime_types = ['murder', 'forcible_rape', 'robbery', 'aggravated_assault', 'burglary', 'larceny_theft',
'motor_vehicle_theft']
# 提取相关犯罪类型数据
subset_data = data[crime_types]
# 设置字体
english_font = FontProperties(family='Times New Roman', size=12)
chinese_font = FontProperties(family='SimSun', size=12)
# 设置 matplotlib 支持中文
plt.rcParams['font.family'] = 'SimSun'
plt.rcParams['axes.unicode_minus'] = False
# 方法一:热力图
# 计算相关系数矩阵
correlation_matrix = subset_data.corr()
# 设置图片清晰度
plt.rcParams['figure.dpi'] = 500
# 绘制热力图
plt.figure(figsize=(20, 16))
sns.heatmap(correlation_matrix, annot=True, cmap='coolwarm')
plt.title('七种犯罪类型之间的相关性热力图', fontproperties=chinese_font)
plt.xticks(fontproperties=english_font)
plt.yticks(fontproperties=english_font)
plt.show()
(2)平行坐标图
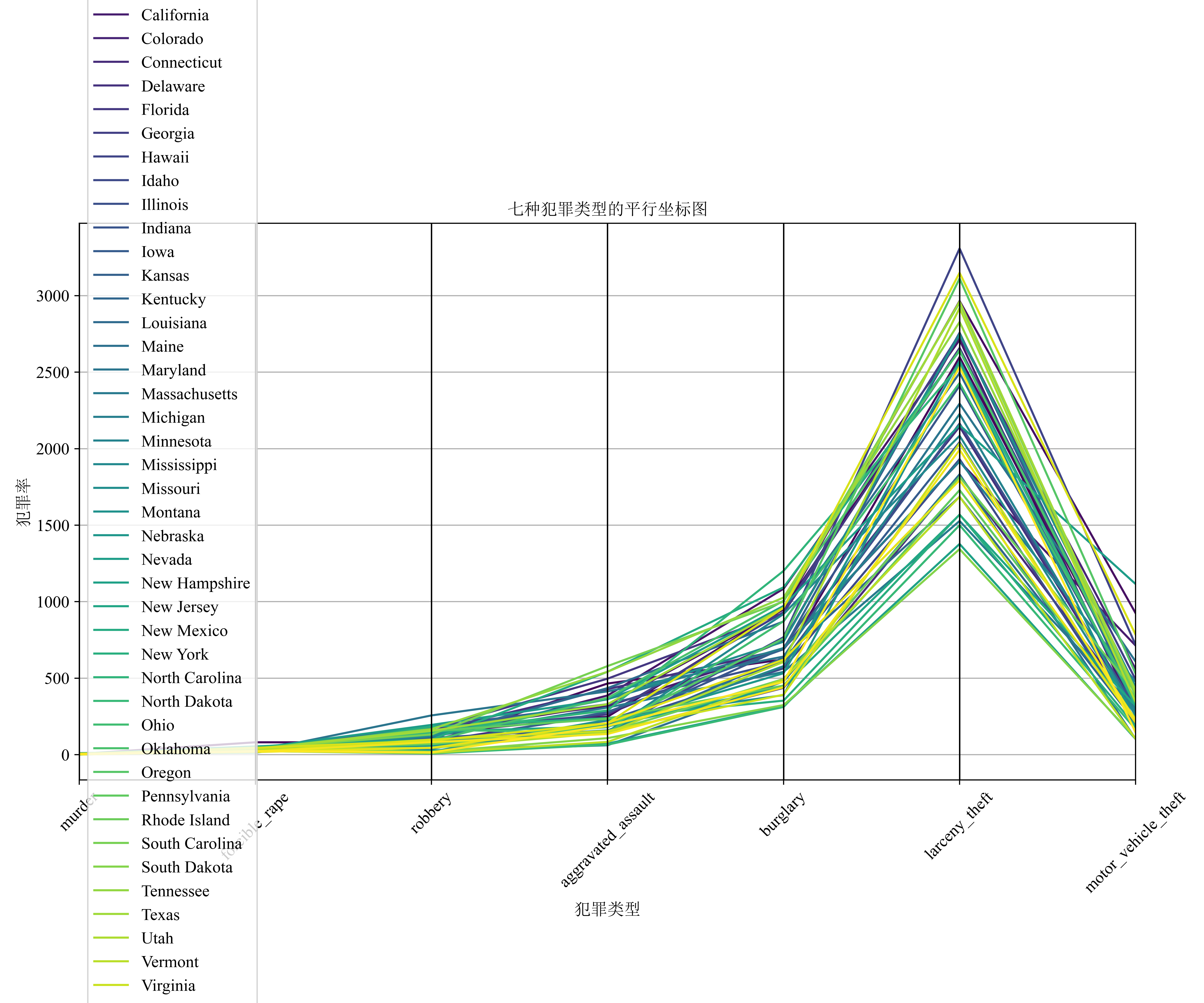
平行坐标图分析
平行坐标图中,每条线代表一个州的七种犯罪类型数据。通过观察线条的走势和聚集情况,可以初步判断犯罪类型之间的关系:
若某些犯罪类型在多个州的线条走势相似(如同时上升或下降),则可能存在一定关联。例如,若 robbery(抢劫)与 aggravated_assault(严重袭击)在许多州的线条趋势相近,结合热力图中两者 0.57 的正相关系数,说明这两种犯罪类型在部分州的发生情况有一定协同变化趋势。
线条的分散程度反映了犯罪类型在不同州的差异。例如,motor_vehicle_theft(机动车盗窃)轴上的线条分散较广,说明各州机动车盗窃率差异较大,与热力图中该变量与其他变量相对复杂的相关性(如与 larceny_theft 为 0.51 的正相关)相呼应,体现其受多种因素影响的特点。
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
from pandas.plotting import parallel_coordinates
from matplotlib.font_manager import FontProperties
# 读取数据
data = pd.read_csv(r"E:\technology\The_fifth_theaper\crimeRatesByState2005.csv")
# 剔除 United States 和 District of Columbia 两行数据
data = data[(data['state'] != "United States") & (data['state'] != "District of Columbia")]
# 七种犯罪类型列名
crime_types = ['murder', 'forcible_rape', 'robbery', 'aggravated_assault', 'burglary', 'larceny_theft',
'motor_vehicle_theft']
# 提取相关犯罪类型数据
subset_data = data[crime_types]
# 设置字体
english_font = FontProperties(family='Times New Roman', size=12)
chinese_font = FontProperties(family='SimSun', size=12)
# 设置 matplotlib 支持中文
plt.rcParams['font.family'] = 'SimSun'
plt.rcParams['axes.unicode_minus'] = False
# 添加一个虚拟的分类列,用于平行坐标图
subset_data['state'] = data['state']
# 绘制平行坐标图,增大图片尺寸
plt.figure(figsize=(12, 10))
parallel_coordinates(subset_data, 'state', colormap='viridis')
plt.title('七种犯罪类型的平行坐标图', fontproperties=chinese_font)
plt.xlabel('犯罪类型', fontproperties=chinese_font)
plt.ylabel('犯罪率', fontproperties=chinese_font)
plt.xticks(rotation=45, fontproperties=english_font)
plt.yticks(fontproperties=english_font)
# 将图例移到左边
legend = plt.legend(loc='center left', bbox_to_anchor=(0, 0.5), prop=english_font)
# 调整布局,避免标签被裁剪
plt.tight_layout()
plt.show()
实验总结
本次实验围绕美国各州犯罪数据的关系可视化展开,通过多种数据可视化方法探究了七种犯罪类型之间的相关关系,达到了实验目的并积累了实践经验。
一、实验目标达成情况
关系数据应用与可视化方法掌握:
通过 seaborn 的 jointplot、矩阵图、热力图和平行坐标图等工具,直观展示了犯罪类型间的分布特征和相关关系。例如,热力图通过颜色深浅量化相关系数,平行坐标图从个体层面呈现数据趋势,验证了 “探索相关关系而非因果关系” 的实验原理。
掌握了不同图表的适用场景:直方图和密度图用于单变量分布分析,散点图和矩阵图用于双变量关系展示,热力图和并行坐标图则适合多变量整体关联分析。
Python 程序实现:
熟练使用 pandas 进行数据清洗(剔除异常值)、seaborn 和 matplotlib 进行可视化、pyecharts 实现动态效果。
解决了版本兼容性问题(如 pyecharts 的 EffectScatter 类移除后,通过 Scatter 结合 EffectOpts 实现动态散点图),提升了代码调试能力。
二、核心发现与数据洞察
犯罪类型相关性特征:
强正相关对(如 robbery aggravated_assault,相关系数 0.78):反映暴力犯罪的协同性,可能与犯罪场景、目标人群重叠有关。
财产犯罪关联性(如 burglary 与 larceny_theft,相关系数 0.69):显示盗窃类犯罪的共性,受区域治安、经济水平影响较大。
独立性犯罪(如 forcible_rape 与其他类型弱相关):表明其犯罪动机和影响因素较特殊,需单独分析。
异常值影响:
“District of Columbia” 的极端犯罪率(如 murder 率 35.4)显著偏离其他州,提醒在数据分析中需注意异常值对整体趋势的干扰,需通过数据清洗提升结果可靠性。
三、实验难点与解决方案
数据清洗与筛选:
问题:原始数据包含全国均值行和异常城市行,需精准剔除。
解决:通过布尔索引 data[(data[‘state’] != …)] 筛选有效数据,确保分析聚焦于正常州。
可视化细节调整:
问题:平行坐标图图例位置不当、标签缺失,热力图字体显示异常。
解决:通过 plt.legend(loc=‘center left’) 调整图例位置,利用 FontProperties 设置中文字体(宋体)和英文字体(Times New Roman),确保图表可读性。
版本兼容性:
问题:pyecharts 版本更新导致部分类(如 EffectScatter)移除,seaborn 方法参数变化。
解决:查阅官方文档,采用替代方案(如 Scatter 结合 EffectOpts),通过代码调试和异常处理(try-except)确保程序鲁棒性。
四、实验价值与未来展望
实际应用价值:
可视化结果可为政策制定提供参考,例如针对高相关犯罪类型(如抢劫与严重袭击)集中的地区,可联合部署治安管控措施;对异常值地区(如 District of Columbia)进行专项调研。
掌握的多变量可视化方法可迁移至其他领域(如经济指标、医疗数据),帮助快速识别数据模式和潜在关联。
改进方向:
结合空间数据:将犯罪率与地理信息(如地图)结合,通过地理热力图或气泡图展示区域差异。
引入机器学习:利用相关关系构建预测模型(如通过盗窃率预测机动车盗窃率),进一步挖掘数据价值。
动态交互优化:使用 pyecharts 或 plotly 实现交互式图表,提升数据探索的灵活性(如缩放、筛选功能)。
五、总结
本次实验通过理论与实践结合,深入理解了关系数据可视化的核心思想和方法,掌握了从数据清洗到图表绘制的完整流程。在解决实际问题(如异常值处理、版本兼容)的过程中,提升了数据分析和代码调试能力。未来可进一步探索更复杂的可视化工具和分析模型,为数据驱动的决策提供更强有力的支持。


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









