




目录
前言
在V4L2设备中,一个常见的套路,注册设备的IO modes ,例如如下代码,以表示对于此设备,可以通过何种方式获取数据。mmap相对古老,而dma buf也并不新鲜。本文介绍不采用V4L2的一套黑盒子流程,而直接调用dma buf相关接口进行视频流的采集。
q->min_buffers_needed = 3;
q->type = V4L2_BUF_TYPE_VIDEO_CAPTURE_MPLANE;
q->io_modes = VB2_MMAP | VB2_DMABUF;
q->lock = &csi->lock;
q->drv_priv = csi;
q->buf_struct_size = sizeof(struct sun4i_csi_buffer);
q->ops = &sun4i_csi_qops;
q->mem_ops = &vb2_dma_contig_memops;
q->timestamp_flags = V4L2_BUF_FLAG_TIMESTAMP_MONOTONIC;
q->dev = csi->dev;头文件引用
在用户态调用dma buf和dma heap相关接口需要包括如下两个内核态的头文件,而单板系统中并没有。
#include <linux/dma-buf.h>
#include <linux/dma-heap.h>1) 通过如下命令,获取内核头文件
make headers_install INSTALL_HDR_PATH=/tmp/linux-headers2)打包后,拷贝到单板,并解压到/usr目录下。
sudo cp -r /tmp/usr-headers/include/* /usr/include/系统中CMA 的信息
heap类型
drivers/dma-buf/heaps/
├── cma_heap.c 物理地址连续内存分配器驱动
├── deferred-free-helper.c 内存延迟释放驱动
├── deferred-free-helper.h
├── Kconfig
├── Makefile
├── page_pool.c 内存⻚缓存驱动
├── page_pool.h
└──system_heap.c 物理地址不连续虚拟地址连续内存分配器驱动system-heap默认⽀持cpu cache,cpu访问该分配器分配的内存是有cache的,device和cpu之间要通过软件⾏为保持数据⼀致性
cma-heap默认⽀持cpu cache,cpu访问该分配器分配的内存是有cache的,访问速度快,但是device和cpu之间要通过软件⾏为保持数据⼀致性。
cma heap数量
已经分配了基于cma heap的dma buffer,但是当map时,报 out of memory错误。本应用申请的内存大小为1920*1080*2=4MB
dma_buf_map_attachment(dba, DMA_FROM_DEVICE);
if (IS_ERR(sgt)) {
pr_err("Error getting dmabuf scatterlist\n");
return -1;//-EINVAL;
}
Error getting dmabuf scatterlist:-12
define ENOMEM 12 /* Out of Memory */ 采用的节点: "/dev/dma_heap/cma" 1)总的大小:128MB,还剩余40MB
cat /proc/meminfo | grep -i cma
CmaTotal: 131072 kB
CmaFree: 41076 kB
2)剩余40MB 的分布情况如下,没有满足4M的了,全是小块的内存。
cat /proc/pagetypeinfo | grep -A 10 -B 5 "CMA"
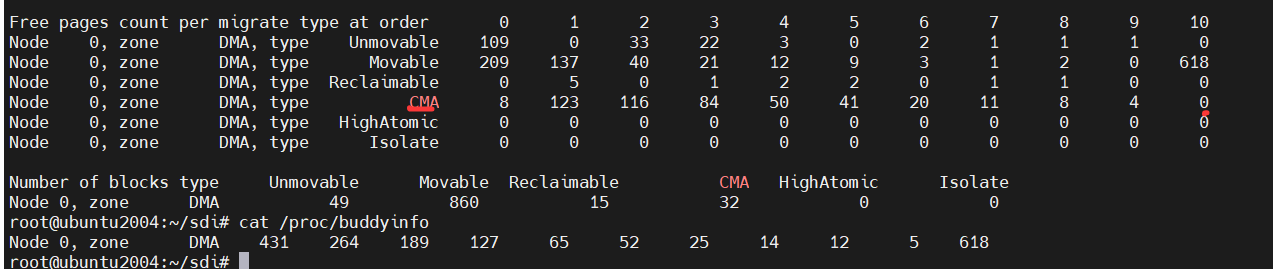
- CMA 内存可用情况:
- order 0: 8 个 4KB 页面
- order 1: 123 个 8KB 连续块
- order 2: 116 个 16KB 连续块
- order 3: 84 个 32KB 连续块
- order 4: 50 个 64KB 连续块
- order 5: 41 个 128KB 连续块
- order 6: 20 个 256KB 连续块
- order 7: 11 个 512KB 连续块
- order 8: 8 个 1MB 连续块
- order 9: 4 个 2MB 连续块
- order 10: 0 个 4MB 连续块
解决方法
1)临时合并
echo 1 > /proc/sys/vm/compact_memory2)调整cma的数量。麒麟V10默认有2G的空间,可参考。
数据需求分析:
帧大小 = 1920 * 1080 * 2 (YUV422) = 4MB
缓冲区数量 = 双缓冲 + 处理中 = 3-4 个
单帧需求 = 4 MB * 4 = 16 MB
编码器输入/输出: 8-16 MB
显示缓冲区: 8-16 MB
单路48*2(2倍余量)=96MB 预留128MB可以。同时基于系统中其他程序已经占用了100MB。
三路视频预留128*3+100=512MB
修改dts配置
kernel\arch\arm64\boot\dts\rockchip\rk3588-linux.dtsi
reserved-memory {
// CMA 配置为 512MB
cma_region: linux,cma {
compatible = "shared-dma-pool";
reusable;
size = <0x20000000>; // 512MB
alignment = <0x1000>;
linux,cma-default;
};
cat /proc/meminfo | grep -i cma
CmaTotal: 524288 kB
CmaFree: 139740 kB
dmesg | grep -i cma
[ 1.114730] Reserved memory: created CMA memory pool at 0x00000000cdc00000, size 512 MiB
[ 1.123456] OF: reserved mem: initialized node cma, compatible id shared-dma-pool
[ 1.437702] Memory: 3211680K/3913728K available (16960K kernel code, 3396K rwdata, 6360K rodata, 6784K init, 592K bss, 177760K reserved, 524288K cma-reserved)
通过上面两个命令可以看到,确认已经修改到了512MB,但是剩余的也只有140M了。说明系统版本中很多功能用到了cma内存,而原先只有128MB,完全不够用。
同时看到4M的空间已经有了28个,理论上应该满足我们的需求了。
dma 映射报错

比如对一个物理设备,例如FPGA。基于此物理设备实现四个逻辑设备功能。
1) 在初始化时,设置物理设备的DMA 掩码。
if (!dev->dma_mask) {
dev->dma_mask = kmalloc(sizeof(*dev->dma_mask), GFP_KERNEL);
if (!dev->dma_mask) {
dev_err(dev, "Failed to allocate DMA mask\n");
return -ENOMEM;
}
}
// 2. 设置 DMA 掩码
// RK3588 通常支持 64 位 DMA,但先尝试 32 位
ret = dma_set_mask_and_coherent(dev, DMA_BIT_MASK(32));
if (ret) {
dev_warn(dev, "32-bit DMA not supported, trying 64-bit\n");
ret = dma_set_mask_and_coherent(dev, DMA_BIT_MASK(64));
if (ret) {
dev_err(dev, "No suitable DMA addressing capability\n");
kfree(dev->dma_mask);
dev->dma_mask = NULL;
return ret;
}
dev_info(dev, "Using 64-bit DMA mask\n");
} else {
dev_info(dev, "Using 32-bit DMA mask\n");
}2) 为每个逻辑设备创建一个字符设备,并初始化字符设备对应的struct device字段。
3) 在DMA 分配、使用相关接口时,需要传递一个struct device参数,如果采用2)中的,则会报错如下,
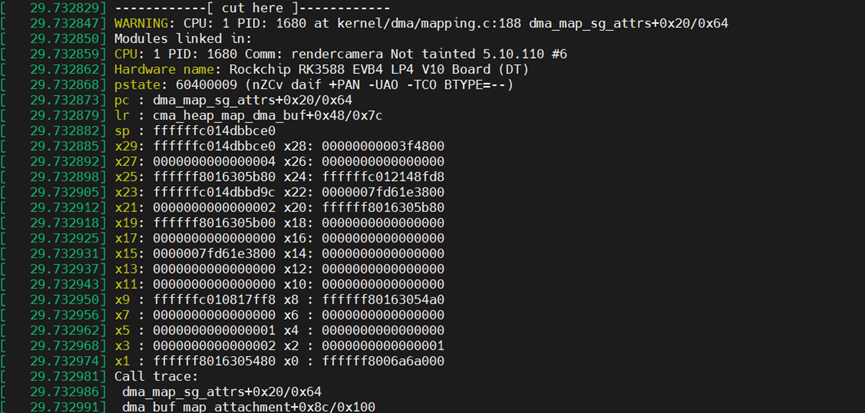
即如下高亮的部分过不了。虽然都是struct device,但是字符设备的此字段并没有设置dma_mask,导致异常。
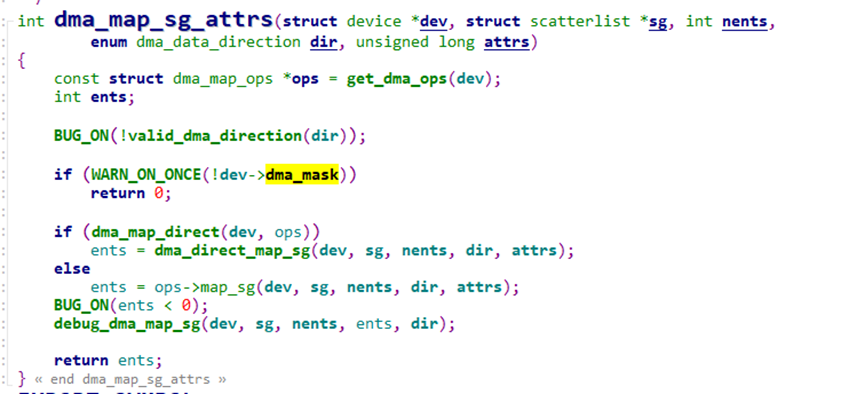
正确示例代码
struct pci_dev *pdev = fpga_dev.pci_dev;
struct device *dev = &pdev->dev;
dba = dma_buf_attach(dbuf, dev);hugetlb_cma= [HW] The size of a cma area used for allocation of gigantic hugepages.
Format: nn[KMGTPE]
Reserve a cma area of given size and allocate gigantic
hugepages using the cma allocator. If enabled, the
boot-time allocation of gigantic hugepages is skipped.用户态部分代码
dma_buf分配
int num_buffers = g_req_buf;//CAPTURE_NUM_BUFFERS;
dma_heap_fd = open(DMA_HEAP_DEVICE_FILE, O_RDWR);
if (dma_heap_fd == -1) {
perror(DMA_HEAP_DEVICE_FILE);
return EXIT_FAILURE;
}
memset(&(dma_buffers[0]) , 0, sizeof(dma_buffers));
for (int i = 0; i < num_buffers; i++) {
void* dma_heap_start;
size_t dma_heap_size = IMAGE_SIZE;
struct dma_heap_allocation_data alloc_data = {
.len = dma_heap_size,
.fd = 0,
.fd_flags = (O_RDWR | O_CLOEXEC),
.heap_flags = 0,
};
if (ioctl(dma_heap_fd, DMA_HEAP_IOCTL_ALLOC, &alloc_data)) {
perror("DMA_HEAP_IOCTL_ALLOC");
return EXIT_FAILURE;
}
dma_heap_start = mmap(NULL,
dma_heap_size,
PROT_READ | PROT_WRITE,
MAP_SHARED,
alloc_data.fd,
0);
if (dma_heap_start == MAP_FAILED) {
perror("mmap");
return EXIT_FAILURE;
}
usr_buf[i].length = dma_heap_size;
usr_buf[i].start = dma_heap_start;
usr_buf[i].fd=alloc_data.fd;dma_buf同步
int dma_buf_fd = usr_buf[buf.index].fd;
const struct dma_buf_sync dma_buf_sync = {
.flags = DMA_BUF_SYNC_READ | DMA_BUF_SYNC_START
};
if (ioctl(dma_buf_fd, DMA_BUF_IOCTL_SYNC, &dma_buf_sync)) {
perror("DMA_BUF_IOCTL_SYNC START");
return EXIT_FAILURE;
}内核代码代码
dbuf = dma_buf_get(vb->fd); //1) 根据用户态通过cma_heap 分配到的dma buf fd获取dma buf结构体
if (IS_ERR_OR_NULL(dbuf)) {
printk("invalid dmabuf fd for plane %d\n",index);
// 打印错误码(数字)
pr_err("Error code: %ld\n", PTR_ERR(dbuf));
ret = -1;//-EINVAL;
return ret;
}
/* create attachment for the dmabuf with the user device */
dba = dma_buf_attach(dbuf, q->dev); //2) 将此buffer与fpga进行关联
if (IS_ERR(dba)) {
pr_err("failed to attach dmabuf\n");
kfree(vb);
return -1;
}
/* get the associated scatterlist for this buffer */
sgt = dma_buf_map_attachment(dba, DMA_FROM_DEVICE); //3) 将分配到的内存映射成sg
if (IS_ERR(sgt)) {
pr_err("Error getting dmabuf scatterlist:%ld\n",PTR_ERR(sgt));
return -1;//-EINVAL;
}
/* checking if dmabuf is big enough to store contiguous chunk */
contig_size = zh_get_contiguous_size(sgt);
if (contig_size < vb->buf_size) {
pr_err("contiguous chunk is too small %lu/%u\n",
contig_size, vb->buf_size);
dma_buf_unmap_attachment(dba, sgt, DMA_FROM_DEVICE);
kfree(vb);
return -1;//-EFAULT;
}
vb->bus_addr = sg_dma_address(sgt->sgl); //4) 根据sg获取总线地址,用于填充外设问题:
1) 例如mipi 控制器,接入多个摄像头,dma mask与控制器、摄像头的关系。理论上讲控制器与dma mask对应。
2) 即使增加了CMA的总大小,但是最大的空间也只有4M的,如何支持8MB,甚至更大空间的物理地址连续的数据传递。
时延统计
采用sdl 接口,将采集到的视频输出到屏幕。
1) 视频格式 SDL_UYVY_OVERLAY,一帧大小w*h*2
2) 进行拷贝操作
int width = 1920;//fmt.fmt.pix.width;
int height = 1080;//fmt.fmt.pix.height;
pscreen =
SDL_SetVideoMode(screen_w, screen_h, 16,
SDL_SWSURFACE|SDL_RESIZABLE );
overlay =
SDL_CreateYUVOverlay(width, height,
/*SDL_YUY2_OVERLAY*/SDL_UYVY_OVERLAY, pscreen);//format:YUYV use SDL_YUY2_OVERLAY
p = (unsigned char *) overlay->pixels[0];
memcpy(p, buf->start, width * height * 2 /*buf->length*/);| dma_buf | mmap |
| 880-700=180 | 440-280=160 |
| 160-030=130 | 860-720=140 |
| 300-160=140 | 680-450=230 |
| 670-520=150 | 300-170=130 |
| 780-600=180 | 107-87=200 |
| 950-820=130 | 77-61=160 |
| 230-60=170 | 430-270=160 |
| 360-230=130 | 160-20=140 |
| 550-400=150 | 730-570=160 |
| 720-570=150 | 1110-980=130 |


















 1721
1721

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











