




目录
用户层接口
struct kiocb *iocb, struct iov_iter *from
static ssize_t tty_write(struct kiocb *iocb, struct iov_iter *from)
{
return file_tty_write(iocb->ki_filp, iocb, from);
}
tty内存分配及数据拷贝
\kernel\drivers\tty\tty_io.c
获取的同步信号
ret = tty_write_lock(tty, file->f_flags & O_NDELAY);
struct mutex atomic_write_lock;
static int tty_write_lock(struct tty_struct *tty, int ndelay)
{
if (!mutex_trylock(&tty->atomic_write_lock)) {
if (ndelay)
return -EAGAIN;
if (mutex_lock_interruptible(&tty->atomic_write_lock))
return -ERESTARTSYS;
}
return 0;
}分配数据块的大小
chunk = 2048;
if (test_bit(TTY_NO_WRITE_SPLIT, &tty->flags))
chunk = 65536;
if (count < chunk)
chunk = count;
/* write_buf/write_cnt is protected by the atomic_write_lock mutex */
if (tty->write_cnt < chunk) {
unsigned char *buf_chunk;
if (chunk < 1024)
chunk = 1024;1) 块大小模式是2KB.。写入数据分割成临时缓冲区进行处理。这极大地简化了底层驱动的实现,因为它们不需要处理锁的问题和用户模式访问。
2) 当检测有 TTY_NO_WRITE_SPLIT,块大小默认为64KB
-
保证数据完整性 - 防止协议数据包被分割
-
提高性能 - 减少系统调用次
3) 1和2中为单次发送的最大数据块,如果发送的数据块长度小于这些值,则按照实际的发送。
写入过程
tty的写入比较简单,即将数据分 数据块大小(2K 或者64K)传递给下层ldisc
do_tty_write(ld->ops->write, tty, file, from);
if (signal_pending(current))
break;
cond_resched();1) 当前写入的进程如果有待处理的信号,则停止写入。此次未写入的数据就丢失了。
2) cond_resched() 的作用是在长时间运行的内核代码路径中主动让出CPU,提供调度机会。
假如用户写入大量的数据,导致写入过程一直循环,导致其他进程得不到调度。
计算写入耗时时,并不仅仅考虑硬件的速率,此处还有写入进程被调度走的时间。
ldisc写入过程
\kernel\drivers\tty\n_tty.c
第一步tty分配内存,写入数据后,调用ldisc层的写入接口继续下发数据。
获取同步信号
down_read(&tty->termios_rwsem);
struct rw_semaphore termios_rwsem;等待队列
DEFINE_WAIT_FUNC(wait, woken_wake_function);add_wait_queue(&tty->write_wait, &wait);将当前进程加入到 TTY 写入等待队列中,以便在条件满足时被唤醒。
-
当 TTY 写入条件变得可用时(如缓冲区有空间),内核可以通过这个队列找到并唤醒所有等待的进程
-
为后续的唤醒操作提供目标列表
wait_woken(&wait, TASK_INTERRUPTIBLE, MAX_SCHEDULE_TIMEOUT); 的作用是让当前进程进入可中断的睡眠状态,直到被显式唤醒或收到信号。
分为两种情况:
1)阻塞模式。当底层驱动的buffer已经满了,则将进程休眠。
2)非阻塞模式,直接返回
驱动写入同步信号
struct mutex output_lock;
mutex_lock(&ldata->output_lock);两种模式判断
启用时(加工模式)
调用驱动层 flush_chars接口
-
适用于交互式终端会话
-
提供用户友好的输出格式
-
自动处理终端控制序列
禁用时(原始模式)
调用驱动层write接口
-
适用于二进制数据传输
-
保持数据的原始格式不变
-
用于串口通信、文件重定向等场景
这一层的buffer依旧来源于上一层。
通用驱动层的写入
\kernel\drivers\tty\serial\serial_core.c
获取同步信号
端口的spinlock
spinlock_t lock; /* port lock */
#define uart_port_lock(state, flags) \
({ \
struct uart_port *__uport = uart_port_ref(state); \
if (__uport) \
spin_lock_irqsave(&__uport->lock, flags); \
__uport; \
})核心写入过程
while (port) {
c = CIRC_SPACE_TO_END(circ->head, circ->tail, UART_XMIT_SIZE);
if (count < c)
c = count;
if (c <= 0)
break;
memcpy(circ->buf + circ->head, buf, c);
circ->head = (circ->head + c) & (UART_XMIT_SIZE - 1);
buf += c;
count -= c;
ret += c;
}缓存大小 #define UART_XMIT_SIZE PAGE_SIZE,通常是4K
1)查看驱动层缓存的余量,如果余量大于待写入的数据量count。
2) 如果缓存没有空间,则返回0,即通知上一层进入 休眠的流程。
3) 将数据拷贝到缓存中。
4) 移动缓存的head指针。即这里发送进程作为生产者,采用head指针操控buffer。
这里head的移动并没有加同步信号,还是用了port的同步信号?
芯片驱动层的写入(8250)
通用层调用芯片驱动的start_tx进行数据发送
使能发送中断及发送控制
if (up->ier & UART_IER_THRI)
return false;
up->ier |= UART_IER_THRI;
#if defined(CONFIG_ARCH_ROCKCHIP) && defined(CONFIG_NO_GKI)
up->ier |= UART_IER_PTIME;
#endif
serial_out(up, UART_IER, up->ier);
return true;1) 如果已经使能了发送空中断,则当前已经处于发送数据的流程中,则直接返回false。
2) 如果没有使能发送空中断,则使能。并开始发送数据。
第一次使能发送空中断,理论上芯片里面发送寄存器和发送FIFO都是空的,为何还要软件触发一次主动发送,而非直接通过发送空的中断来触发?
那就是第一次的时候,即使空也不会触发中断,只有发送数据后为空才会触发中断。
发送数据
serial8250_tx_chars
此接口即会在上述总体流程中初始时调用;主要在中断里面会调用。
count = up->tx_loadsz;
do {
serial_out(up, UART_TX, xmit->buf[xmit->tail]);
xmit->tail = (xmit->tail + 1) & (UART_XMIT_SIZE - 1);
port->icount.tx++;
if (uart_circ_empty(xmit))
break;
} while (--count > 0);
if (uart_circ_chars_pending(xmit) < WAKEUP_CHARS)
uart_write_wakeup(port);1)获取发送芯片FIFO的大小
2)从circ队列中获取数据写满FIFO
3) 如果circ 队列的字符数据少于 门限值,则唤醒休眠的发送进程。
#define WAKEUP_CHARS 256 /* hard coded for now */
驱动缓存
用户发送的数据,最终落到驱动缓存buffer中。
判空
#define uart_circ_empty(circ) ((circ)->head == (circ)->tail)剩余字符数目
/* Return count in buffer. */
#define CIRC_CNT(head,tail,size) (((head) - (tail)) & ((size)-1))
#define uart_circ_chars_pending(circ) \
(CIRC_CNT((circ)->head, (circ)->tail, UART_XMIT_SIZE))到尾部的字符数目
/* Return count up to the end of the buffer. Carefully avoid
accessing head and tail more than once, so they can change
underneath us without returning inconsistent results. */
#define CIRC_CNT_TO_END(head,tail,size) \
({int end = (size) - (tail); \
int n = ((head) + end) & ((size)-1); \
n < end ? n : end;})剩余空间
/* Return space available, 0..size-1. We always leave one free char
as a completely full buffer has head == tail, which is the same as
empty. */
#define CIRC_SPACE(head,tail,size) CIRC_CNT((tail),((head)+1),(size))
#define uart_circ_chars_free(circ) \
(CIRC_SPACE((circ)->head, (circ)->tail, UART_XMIT_SIZE))到尾部的剩余空间
/* Return space available up to the end of the buffer. */
#define CIRC_SPACE_TO_END(head,tail,size) \
({int end = (size) - 1 - (head); \
int n = (end + (tail)) & ((size)-1); \
n <= end ? n : end+1;})tty写入时采用
初始化
在通用串口驱动层startup时,分配发送需要的驱动内存。
/*
* Initialise and allocate the transmit and temporary
* buffer.
*/
page = get_zeroed_page(GFP_KERNEL); //这里分配了页大小的缓存
if (!page)
return -ENOMEM;
uart_port_lock(state, flags);
if (!state->xmit.buf) {
state->xmit.buf = (unsigned char *) page;
uart_circ_clear(&state->xmit); //将头尾都指向0索引
uart_port_unlock(uport, flags);
} else {
uart_port_unlock(uport, flags);
/*
* Do not free() the page under the port lock, see
* uart_shutdown().
*/
free_page(page);
}数据在buffer中流程
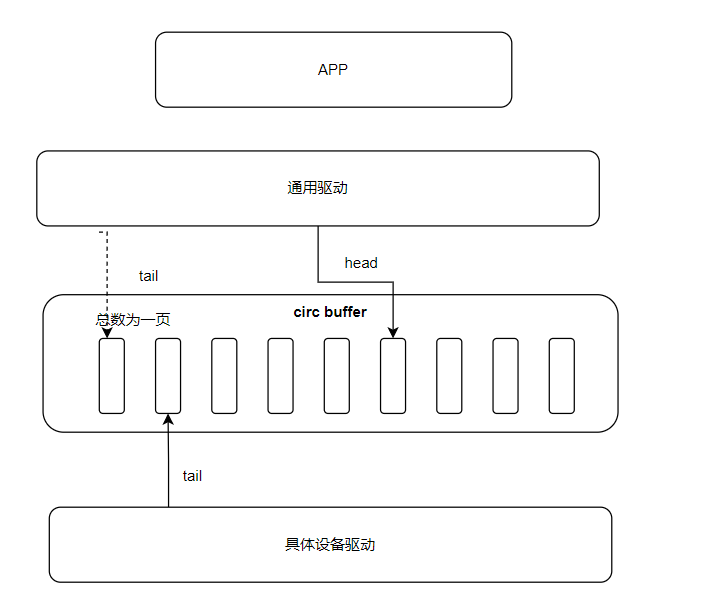
1) 串口通用驱动层 ,将上层的数据拷贝head开始的剩余空间中,并移动head。属于用户进程的上下文中。
2) 某些设备驱动,在用户进程的上下文接口中,会通过tail读取刚才写入的数据。然后写入到FIFO中。例如FIFO 为32字节,则从circ buffer中读取32个字节写入到FIFO中。
3) 而对于circ buffer中其余的数据,例如此次用户进程写入1280个字节,前期32个字节写入到FIFO中,后续的字节则在驱动中断上下文中读取。
tail指针的并发访问
首先对于tail指针的访问,即存在两个上下文,即用户发送及中断,对其访问。
前期的通用层在发送时也获取此锁。即uart_port的锁。
并没有单独对circ buffer进行单独的并发访问控制。
struct uart_port *port,
spin_lock_irqsave(&port->lock, flags);head与tail的并发
同样采用了uart_port的锁。
head写入过程
while (port) {
c = CIRC_SPACE_TO_END(circ->head, circ->tail, UART_XMIT_SIZE);
if (count < c)
c = count;
if (c <= 0)
break;
memcpy(circ->buf + circ->head, buf, c);
circ->head = (circ->head + c) & (UART_XMIT_SIZE - 1);
buf += c;
count -= c;
ret += c;
}此缓存是连续的数组,并非链表,这里写入的时候用了些技巧,即每次都获取head到tail之间的空余空间,然后拷贝进去。
实际计算几种情况
#define CIRC_SPACE_TO_END(head,tail,size) \
({int end = (size) - 1 - (head); \
int n = (end + (tail)) & ((size)-1); \
n <= end ? n : end+1;})
1) head=tail=0,size=4096 即初始态
-
end = 4096 - 1 - 0 = 4095 -
n = (4095 + 0) & 4095=4095
CIRC_SPACE_TO_END(0, 0, 4096) = 4095
2) head=4095,tail=0,size=4096即用户进程已写满后再次想写入
-
end = 4096 - 1 - 4095 = 0 -
n = (0 + 0) & 4095 = 0 -
CIRC_SPACE_TO_END(4095, 0, 4096) = 0
3) head=4095,tail=100,size=4096即用户进程已写满后再次想写入,并且驱动已经发送部分数据
CIRC_SPACE_TO_END(4095, 100, 4096) = 1
-
head 指针在缓冲区的最后一个位置(4095)
-
从 head 到缓冲区末尾的连续可用空间只有 1 个字节
4)基于3的情况,c=1 head=4095
circ->head = (circ->head + c) & (UART_XMIT_SIZE - 1);
circ->head = 0
这是循环缓冲区设计的经典模式,要求缓冲区大小必须是 2 的幂。
5)head=0,tail=200,size=4096即用户进程已写满后再次想写入,并且驱动已经发送部分数据,head已经回绕了
CIRC_SPACE_TO_END(0, 200, 4096) = 199
即当出现3的情况时,通常需要两次拷贝,将用户数据拷贝到circ buffer中。
串口读取tail过程
xmit->tail = (xmit->tail + 1) & (UART_XMIT_SIZE - 1);
这里和写入的计算完全一样,但是每次只是一个字节。
进程唤醒
const struct tty_port_client_operations tty_port_default_client_ops = {
.receive_buf = tty_port_default_receive_buf,
.write_wakeup = tty_port_default_wakeup,
};void tty_wakeup(struct tty_struct *tty)
{
struct tty_ldisc *ld;
if (test_bit(TTY_DO_WRITE_WAKEUP, &tty->flags)) {
ld = tty_ldisc_ref(tty);
if (ld) {
if (ld->ops->write_wakeup)
ld->ops->write_wakeup(tty);
tty_ldisc_deref(ld);
}
}
wake_up_interruptible_poll(&tty->write_wait, EPOLLOUT);
}此处wake_up 与ldisc写入过程中的等待队列完美对应了。唤醒在等待队列中等待特定事件的可中断睡眠进程,并传递事件掩码信息。
ldisc层唤醒
static void n_tty_write_wakeup(struct tty_struct *tty)
{
clear_bit(TTY_DO_WRITE_WAKEUP, &tty->flags);
kill_fasync(&tty->fasync, SIGIO, POLL_OUT);
}向注册了异步 I/O 通知的进程发送输出就绪信号。
-
向通过
fcntl(F_SETFL)设置了FASYNC标志的进程发送通知 -
这些进程希望在外设状态变化时异步接收信号
-
POLL_OUT事件表示设备已准备好接收输出数据 -
通知应用程序现在可以安全地进行写入操作而不会阻塞
总结
缓存大小
| tty层缓存 | 驱动层缓存 | 唤醒门限 |
| 拆分时 2K 不拆分时 64K | PAGE_SIZE 诸如4K等 | 256字节 |
并发访问、调度及休眠唤醒
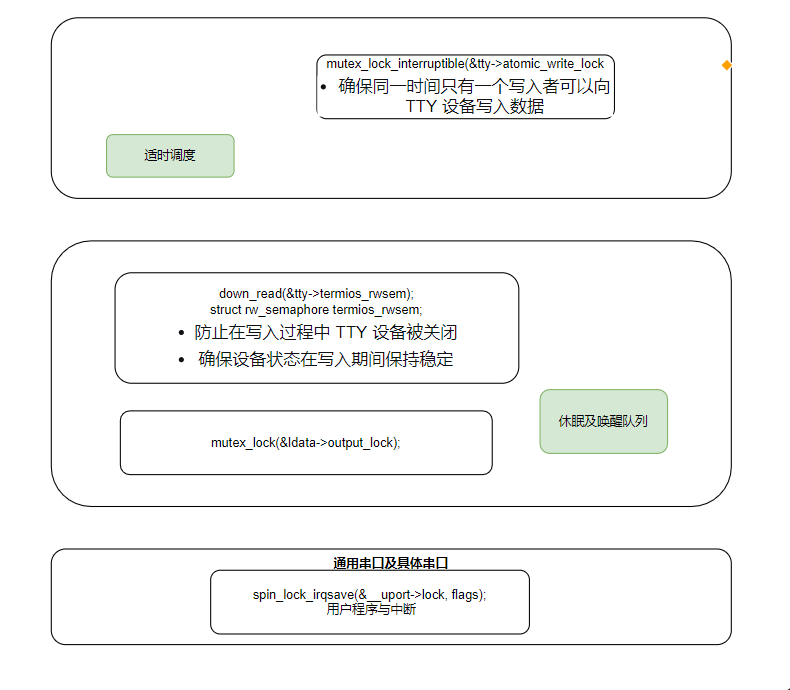
循环发送数据时适时让出CPU,底层驱动缓存忙时的进程休眠,及驱动缓存到达门限时的唤醒,这些是各种驱动通用。
驱动并非简单的操作硬件,其还要考虑与上层进程的接口,及系统中其他进程的关系。


















 3330
3330

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











