




目录
在前一篇文章中,描述了cma heap的分配及映射到用户空间。那么内核态的驱动如何使用呢?
cma_heap_attach
基本流程
当用户态调用到VIDIOC_QBUF,即将buffer填充到摄像头控制器等设备的缓存队列中
drivers\media\common\videobuf2\videobuf2-core.c
vb2_core_qbuf-》__buf_prepare-》__prepare_dmabuf
attach_dmabuf-》cma_heap_attach
设备与buffer建立联系
其中table是dma buffer 散列化后的table
dev 为摄像头控制器对应的dev
struct dma_heap_attachment {
struct device *dev;
struct sg_table *table;
struct list_head list;
bool mapped;
bool uncached;
};设备buffer队列与buffer建立联系
此处将dbuf传递给设备vb queue中。
vb->planes[plane].dbuf = dbuf;
vb->planes[plane].mem_priv = mem_priv;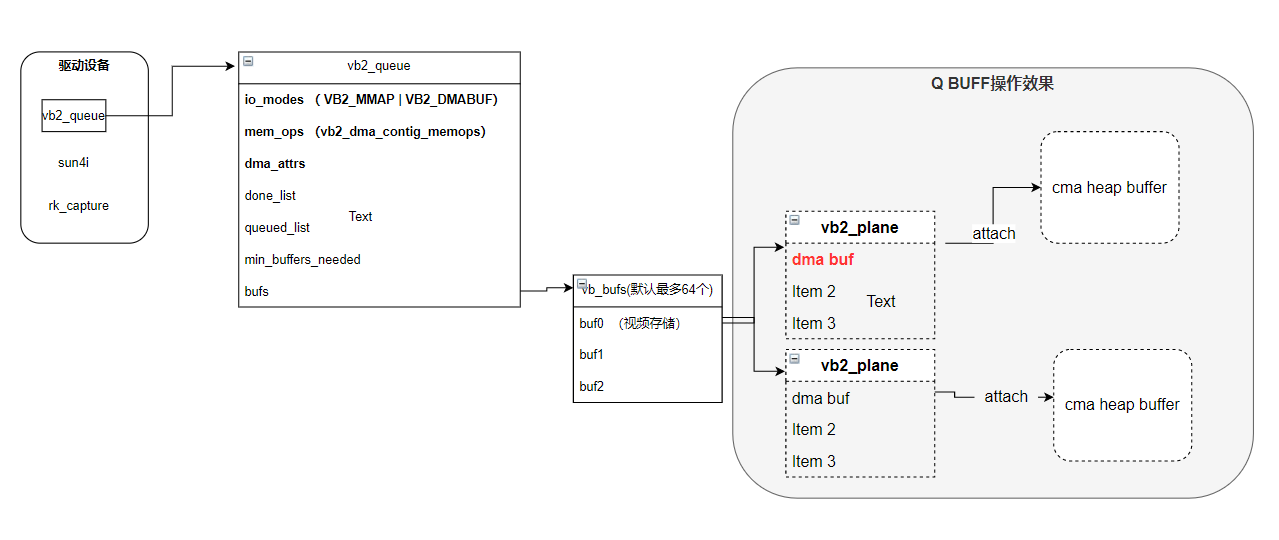
最终效果如上,此时设备已经和 cma heap buffer建立关联,但设备还不能使用,因为dma buf目前只分配了物理地址以及映射了用户态虚拟地址,而总线地址和内核态虚拟地址还没有映射。
map_dma_buf
当用户态调用到VIDIOC_QBUF,如下紫色部分为两个回调接口,其后的函数为具体实现
1)./drivers/media/common/videobuf2/videobuf2-core.c:1275: ret = call_memop(vb, map_dmabuf, vb->planes[plane].mem_priv);
__prepare_dmabuf--》map_dmabuf--》vb2_dc_map_dmabuf--》
2)\drivers\media\common\videobuf2\videobuf2-dma-contig.c
vb2_dc_map_dmabuf--》dma_buf_map_attachment
3)\kernel\drivers\dma-buf\dma-buf.c :
dma_buf_map_attachment-》map_dma_buf-》cma_heap_map_dma_buf
.4)最终调用接口,这里主要完成将物理地址映射成dma地址。
dma_addr_t dma_addr = phys_to_dma(dev, phys);
int dma_direct_map_sg(struct device *dev, struct scatterlist *sgl, int nents,
enum dma_data_direction dir, unsigned long attrs)
{
int i;
struct scatterlist *sg;
for_each_sg(sgl, sg, nents, i) {
sg->dma_address = dma_direct_map_page(dev, sg_page(sg),
sg->offset, sg->length, dir, attrs);
if (sg->dma_address == DMA_MAPPING_ERROR)
goto out_unmap;
sg_dma_len(sg) = sg->length;
}
return nents;完成此步骤后,设备已经具有了dma 总线地址,可以将这些地址写入到控制器的寄存器中或者描述符队列中,以便设备DMA时使用了。至此,外部设备就可以开始正常工作,往soc发送数据,应用层通过mmap出的地址可以读取数据了。
cma_heap_unmap_dma_buf和cma_heap_detach 在释放内存资源的时候调用,这里就不再赘述。
总体流程
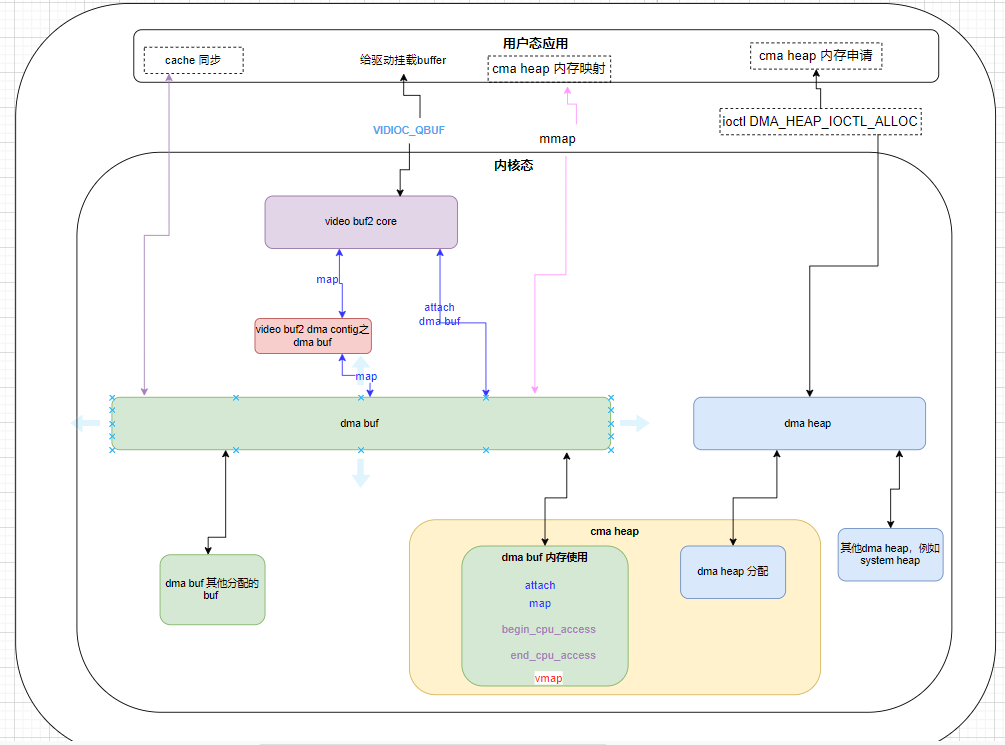
上图从右到左
1) 用户应用通过 dma heap 分配所需的内存
2) 通过dma buf 将分配的内存映射到用户空间,默认带cache
3)将内存通过dma buf接口挂接到v4l2设备上,并将内存映射成总线地址。
4) 启动设备传输流程,设备即可以使用此段内存。
5)用户程序进行cache的同步,而后读取数据
cache的同步
由于映射到用户空间默认是带cache的,当dma完毕后,用户获取数据时要进行cache的同步操作。
begin_cpu_access
作用为外设DMA完毕后,如果外设不支持dma 一致性,则需要在cpu访问内存前,进行invalide的操作。
代码如下:
struct cma_heap_buffer *buffer = dmabuf->priv;
struct dma_heap_attachment *a;
if (buffer->vmap_cnt)
invalidate_kernel_vmap_range(buffer->vaddr, buffer->len);
if (buffer->uncached)
return 0;
mutex_lock(&buffer->lock);
list_for_each_entry(a, &buffer->attachments, list) {
if (!a->mapped)
continue;
dma_sync_sgtable_for_cpu(a->dev, &a->table, direction);
}
mutex_unlock(&buffer->lock);对于5.10内核,其还有如下一段
if (list_empty(&buffer->attachments)) {
phys_addr_t phys = page_to_phys(buffer->cma_pages);
dma_sync_single_for_cpu(dma_heap_get_dev(buffer->heap->heap),
phys + offset,
len,
direction);
}总体分为三个部分
invalidate_kernel_vmap_range
对于此段内存,如果映射到内核虚拟地址,则调用此接口。
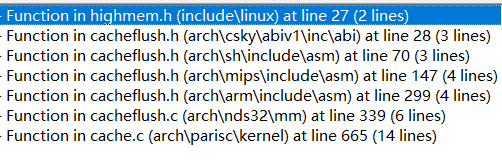
此函数的实现,除了上图的少数几个CPU 架构,其余实现都是空的。在我们应用中,内存也不会映射到内核,此段忽略。
dma_sync_sgtable_for_cpu
最终对于sg table中的每个sg调用接口
void arch_sync_dma_for_cpu(phys_addr_t paddr, size_t size,
enum dma_data_direction dir)
{
__dma_unmap_area(phys_to_virt(paddr), size, dir);
}dma_sync_single_for_cpu
void arch_sync_dma_for_cpu(phys_addr_t paddr, size_t size,
enum dma_data_direction dir)
{
__dma_unmap_area(phys_to_virt(paddr), size, dir);
}end_cpu_access
总体流程和 begin cpu access 类似,即内核虚拟地址的flush,这部分接口涉及到的cpu架构和begin 一致。 以及attach 的sg的flush。
void arch_sync_dma_for_device(phys_addr_t paddr, size_t size,
enum dma_data_direction dir)
{
__dma_map_area(phys_to_virt(paddr), size, dir);
}cache.S
cache.S arch\arm64\mm
cache的最终同步接口。这里使用内核虚拟地址。
/*
* __dma_map_area(start, size, dir)
* - start - kernel virtual start address
* - size - size of region
* - dir - DMA direction
*/
SYM_FUNC_START_PI(__dma_map_area)
cmp w2, #DMA_FROM_DEVICE
b.eq __dma_inv_area
b __dma_clean_area
SYM_FUNC_END_PI(__dma_map_area)
/*
* __dma_unmap_area(start, size, dir)
* - start - kernel virtual start address
* - size - size of region
* - dir - DMA direction
*/
SYM_FUNC_START_PI(__dma_unmap_area)
cmp w2, #DMA_TO_DEVICE
b.ne __dma_inv_area
ret
SYM_FUNC_END_PI(__dma_unmap_area)
armasm
add x1, x1, x0 // x1 = 结束地址(start + size) dcache_line_size x2, x3 // x2 = 缓存行大小(如 64 字节) sub x3, x2, #1 // x3 = 缓存行掩码(如 0x3F)
armasm
tst x1, x3 // 检查结束地址是否对齐缓存行 bic x1, x1, x3 // 对齐结束地址(向下舍入) b.eq 1f // 如果已对齐,跳过 dc civac, x1 // 清理并失效未对齐的结束行 1:
armasm
tst x0, x3 // 检查起始地址是否对齐缓存行 bic x0, x0, x3 // 对齐起始地址(向下舍入) b.eq 2f // 如果已对齐,跳过 dc civac, x0 // 清理并失效未对齐的起始行 b 3f 2: dc ivac, x0 // 仅失效已对齐的缓存行 3:
armasm
add x0, x0, x2 // 移动到下一缓存行 cmp x0, x1 // 是否到达结束地址? b.lo 2b // 未到达则循环 dsb sy // 等待所有操作完成 ret // 返回
同步关系图
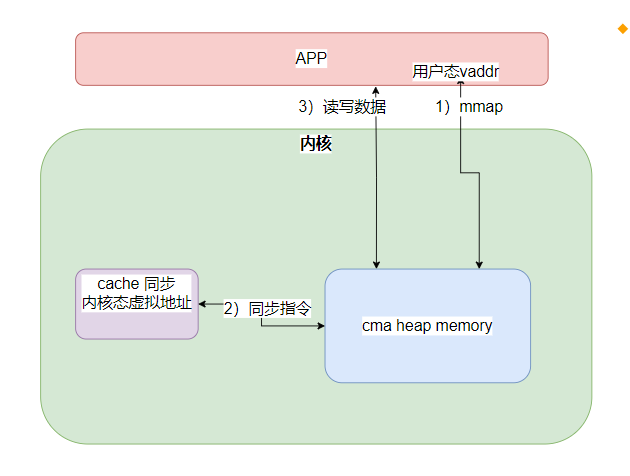
最终看起来为上图:
1) cma heap 分配内存。
2)mmap映射到用户态虚拟地址
3)通过内核态虚拟地址进行cache同步
4) 通过用户态虚拟地址进行访问。
phys_to_virt(paddr)和 vmap映射出的地址有什么差异?为何还需要invalidate_kernel_vmap_range操作?是因为架构的需求?
一段物理内存,如果需要同步cache,获取其对应的内核地址,在内核空间进行同步。
总结
老一辈的内核书籍介绍DMA时,区分一致性接口dma_coherent接口和流式映射dma_map_single接口,都是由驱动主导内存的分配。
而dma heap相关接口,提供用户态程序分配内存的接口,进而将这些内存通过dma buf机制attach到对应的设备。同时提供了cache同步接口。 内存的管理完全交给了用户态应用程序。
分配内存的本质,分配一块物理内存;而后根据需要映射成用户态虚拟地址、内核态虚拟地址、总线地址。当然并不需要全部映射。通常的应用中,并不需要映射成内核态虚拟地址。
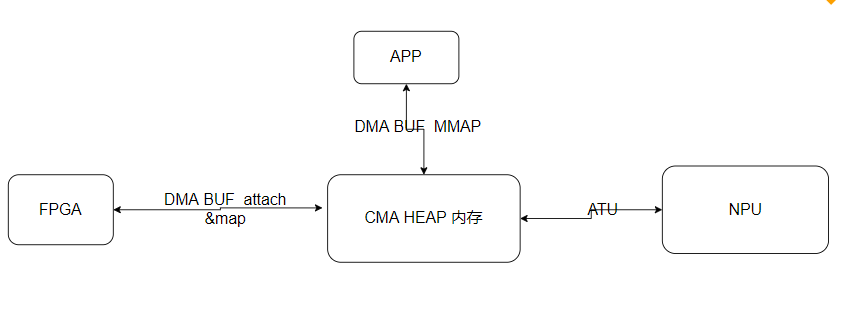
假设NPU 能访问整个内存空间,则通过NPU的映射机制将这段内存映射到NPU的地址空间,NPU程序可以直接读写此段内存,则也完全不需要拷贝了。
所以问题的核心在于
1) soc /fpga/npu/gpu等访问的物理内存地址范围。
2)物理地址映射到某个SOC NPU GPU的方式。 例如简单些:
参考资料
以下资料介绍了调用示例,并对比mmap和dma heap时的延时。



















 1699
1699

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











