




 本文探讨了Loss函数下降停滞的问题,指出恒定学习率的局限性,并介绍了RMSProp和Adam等自适应学习率算法,通过RootMeanSquare控制学习速率,以及如何通过动量和学习速率衰减来优化模型训练过程,避免爆发情况的发生。
本文探讨了Loss函数下降停滞的问题,指出恒定学习率的局限性,并介绍了RMSProp和Adam等自适应学习率算法,通过RootMeanSquare控制学习速率,以及如何通过动量和学习速率衰减来优化模型训练过程,避免爆发情况的发生。
一、问题分析
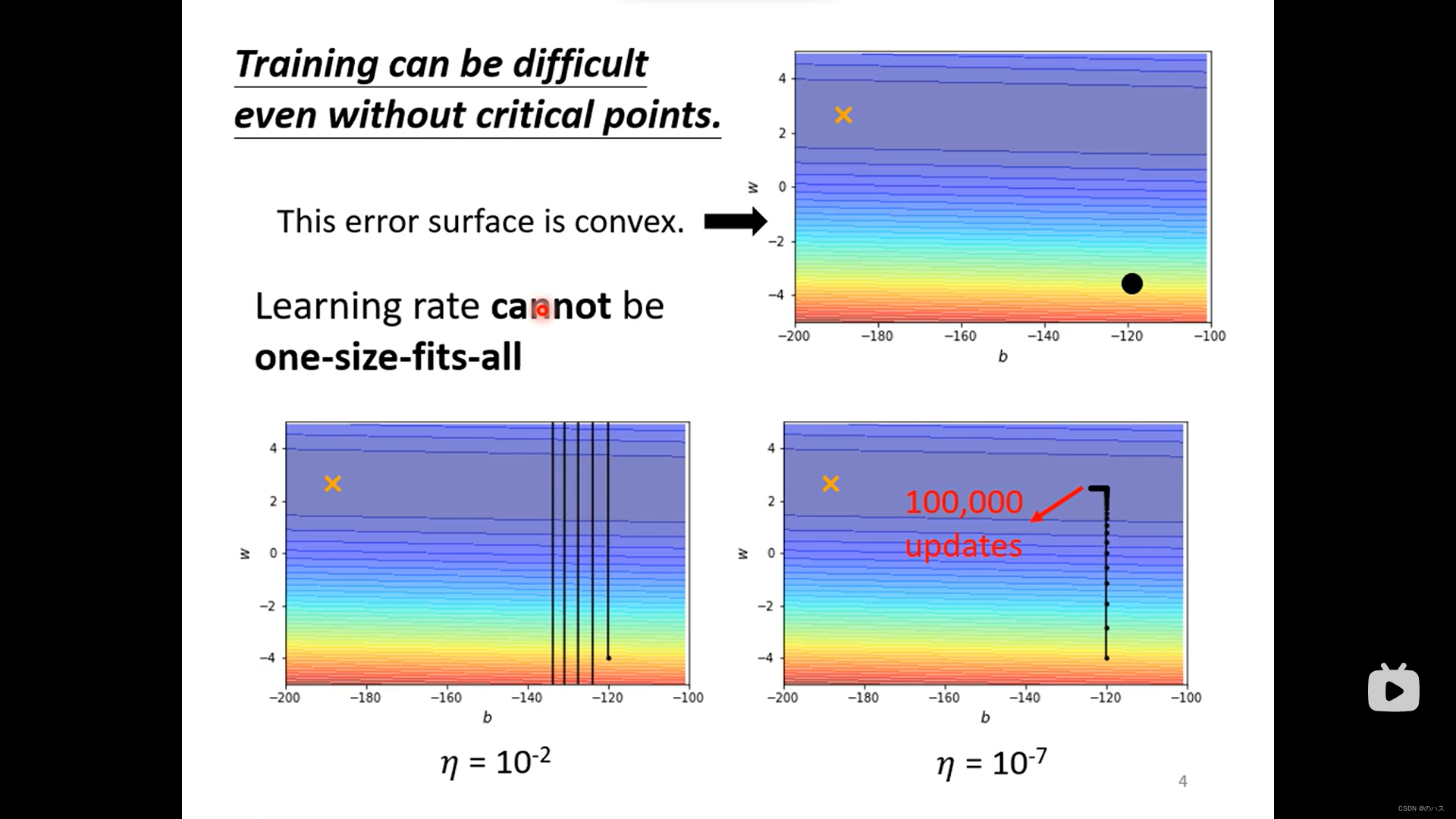
Loss降不下去,不等价于梯度很小,看下图中,Loss函数降不下去了,但是梯度仍然在波动,可能就像是左边的图中所示,在横向移动,不能向下移动。

其实要到达critical point是很困难的,如下图,先让学习速率为10的-2次方,可以看到优化路径呈现上下跨度很大的锯齿形,这是因为学习速率太大了,起始点的梯度也很大,导致刹不住车,直接冲上去了,如果我们减小学习速率,这下不会导致直接冲出去,但是由于速率太慢,经过100000次update还是没能到critical point。通过这个现象我们发现,固定的学习速率不能适合所有时刻,我们需要进行适当的调整。
二、调节方法
1.Root Mean Square
不同的参数需要不同的学习速率,所以这里我们给学习速率除以一个parameter dependent,用它来控制我们的学习速率。

这里我们用Root Mean Square 来控制速率,取之前求得的所有梯度的平方和求平均值再开放得到这个Root Mean Square。

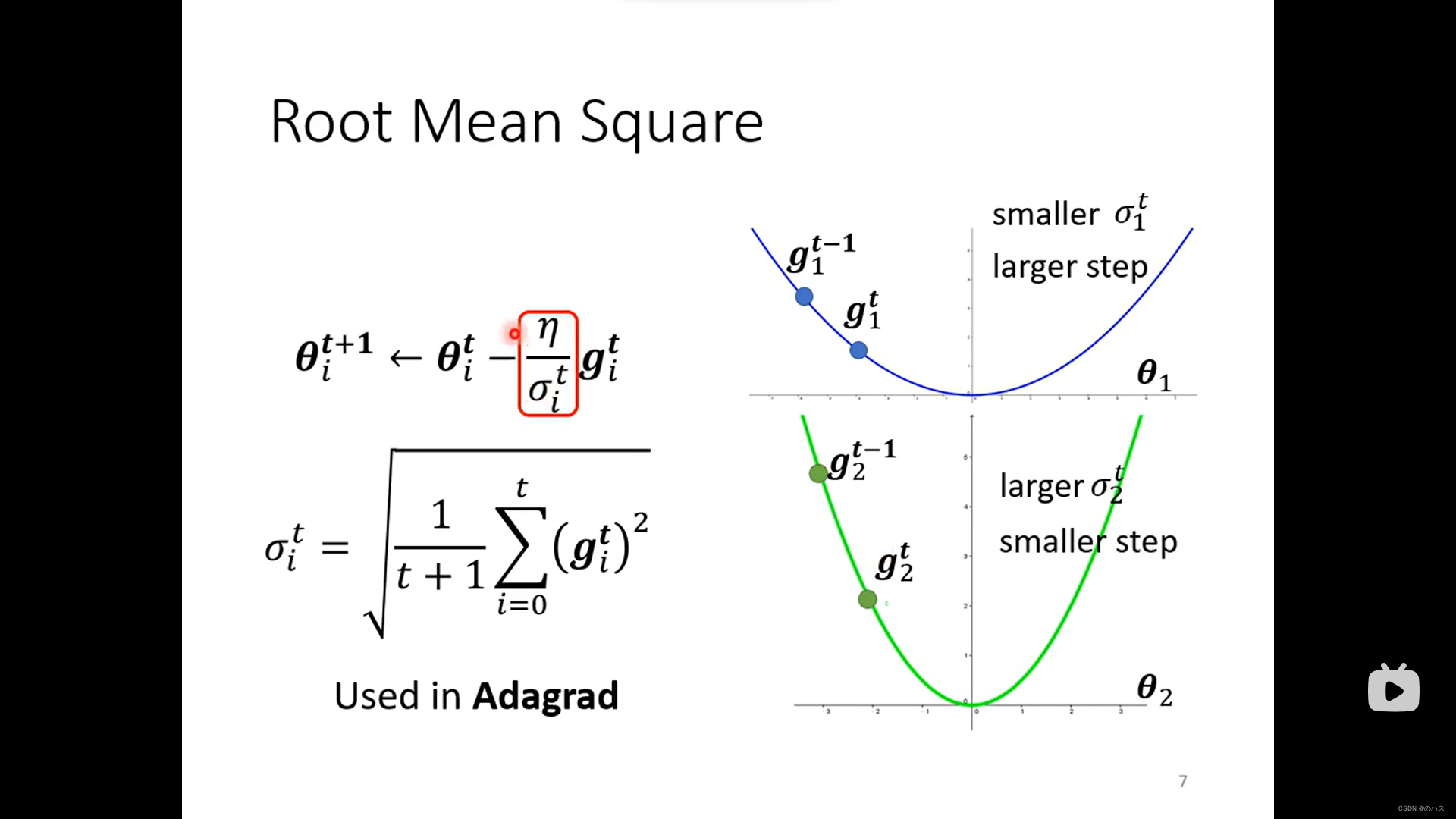
从表达式中我们可以看出,当梯度大时,Root Mean Square大,梯度的系数就小,移动的速率得到控制,不至于过快。
当梯度小时,Root Mean Square小,梯度的系数就大,移动的速率得到控制,不至于过慢。
2.RMSProp

这里我们的表达式不变,但是我们的parameter dependent的计算方法就需要改变一下了,我们用一个阿尔法取乘以前一个pd 的平方 加上(1- 阿尔法)乘以当前位置梯度的平方,在开方,这里的阿尔法又是一个hyperparameter,需要自己定义,根据你觉得哪个参数的影响会更大来决定这两个参数的占比。

从表达式可以看出,这样最近的梯度对于pd 的影响较大,而相隔较远的梯度对于pd的影响更小,所以说在梯度增大的时候能够快速减小系数,梯度小的时候能够增大系数,使优化跨度不至于太慢。
3. Adam


如果没有适应性的学习速率,我们继续采用第一种方式进行调整,那么在后面会出现爆发的情况,在竖直移动的那一段梯度是比较大的,但水平移动后梯度很小,累计次数足够后,pd就会变得很小,梯度很小但是参数一下变得很大,出现爆发的情况,这种情况我们又怎么解决呢?
4. 学习速率规划
随着离终点越来越近,学习速率逐渐减小,这样就不会出现这种爆发的情况,而较小的梯度也会减小pd,使梯度的系数增大,让移动速度不至于太慢。

三、总结。
 现在我们的优化方式是通过动量(考虑前面所有梯度的矢量和)来决定方向,Root Mean Square来表示大小,然后再配上学习速率衰减。
现在我们的优化方式是通过动量(考虑前面所有梯度的矢量和)来决定方向,Root Mean Square来表示大小,然后再配上学习速率衰减。

















 1万+
1万+




 到【灌水乐园】发言
到【灌水乐园】发言







