




 本文介绍了机器学习中如何通过训练数据调整Loss,分析模型复杂度与Loss的关系,包括模型偏置、优化问题和过拟合。提出使用训练和验证数据集来选择合适的模型,防止数据分布不匹配带来的影响。
本文介绍了机器学习中如何通过训练数据调整Loss,分析模型复杂度与Loss的关系,包括模型偏置、优化问题和过拟合。提出使用训练和验证数据集来选择合适的模型,防止数据分布不匹配带来的影响。
一、机器学习结构
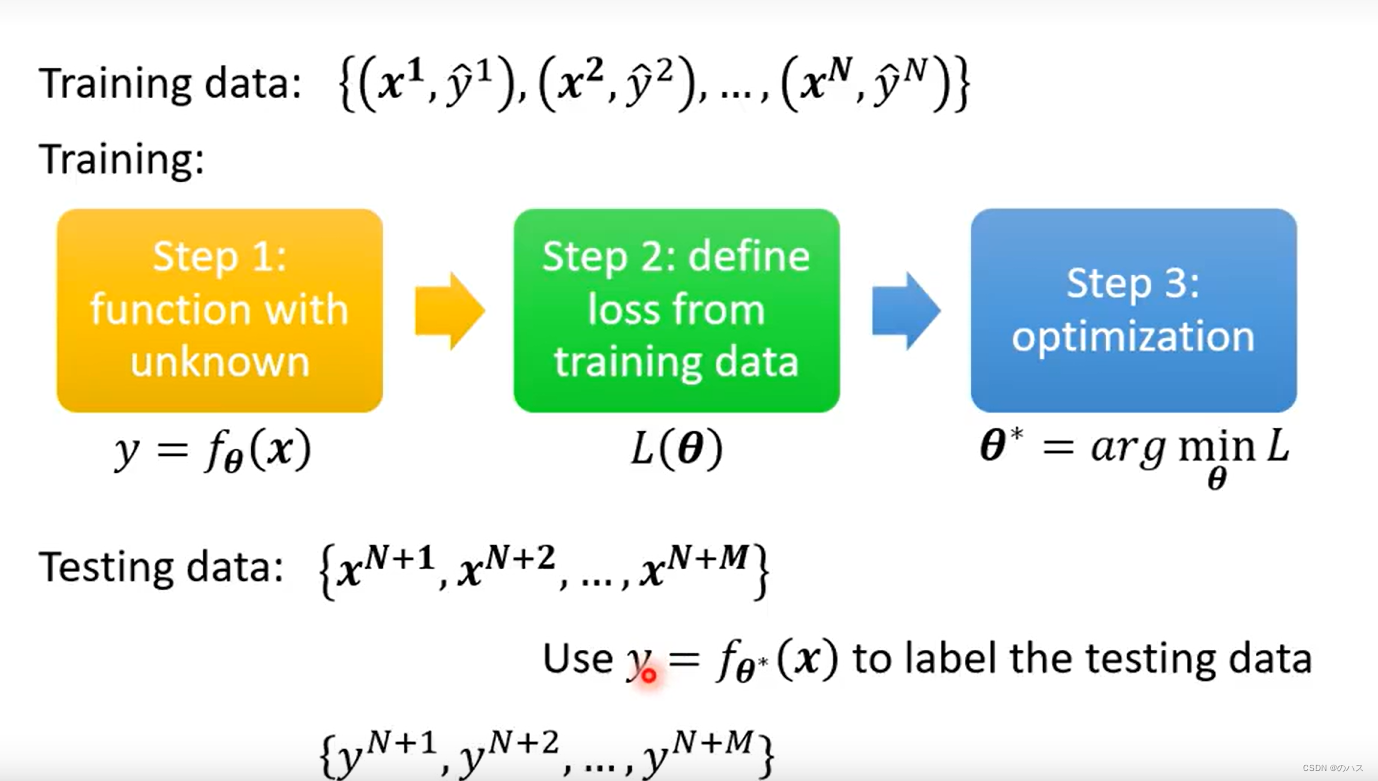
用训练数据训练自己写的函数,找到使Loss最小的参数组,用这个最小的参数组将需要预测的featrue放到函数中得到预测值y。
二、结果不满意时的分析流程以及对应问题的原因和解决方法。
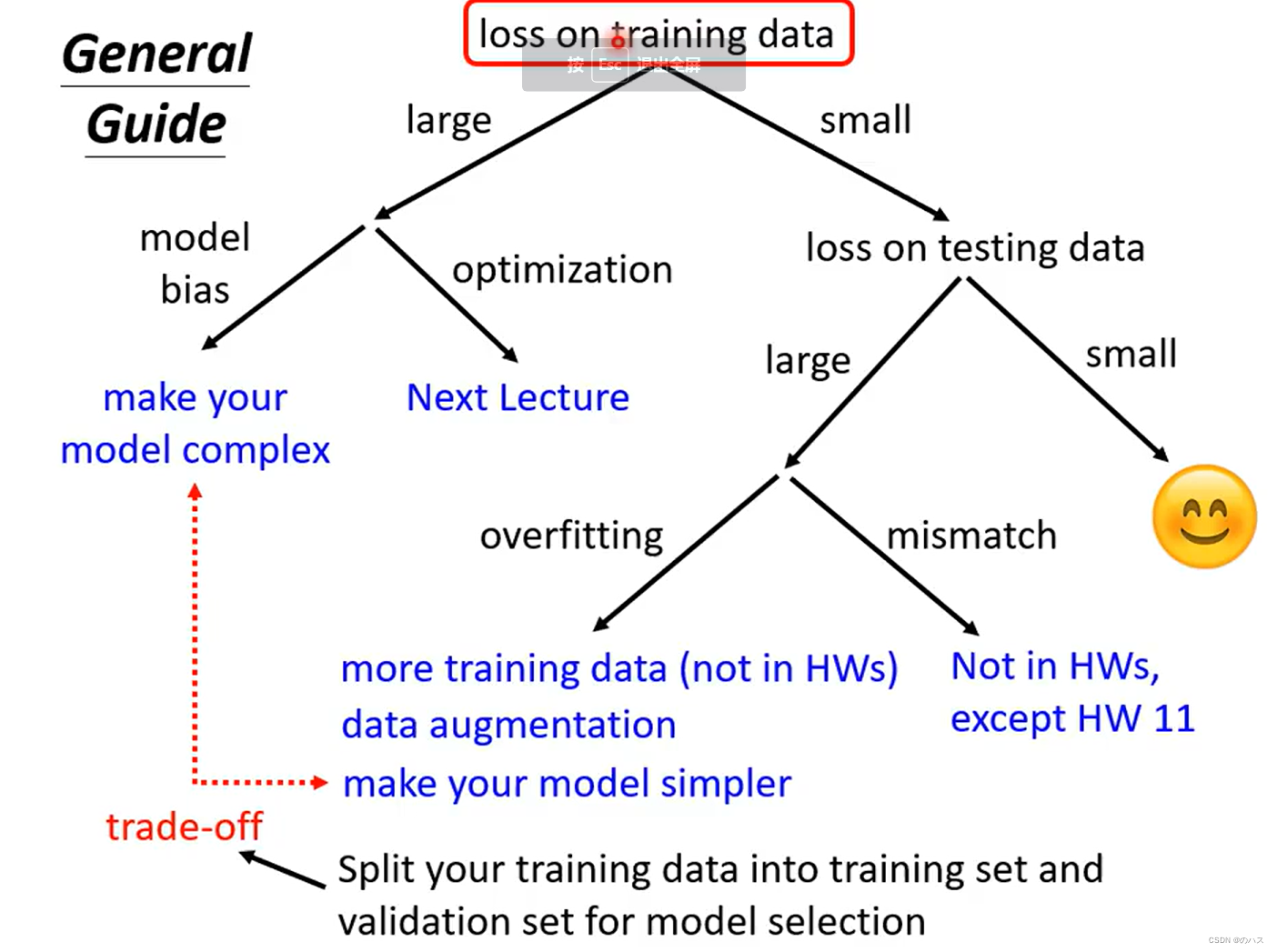
1.首先分析自己训练数据的Loss值,如果足够小,再去看测试数据的Loss,如果比较大,分为两个原因
(1).Model Bias
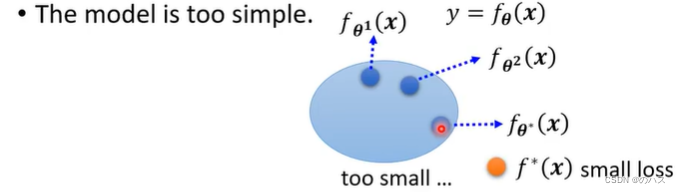
原因:模型过于简单了,在这个模型范围里面找不出可以让我们的Loss变小的函数,就算找出了这个范围里面的c塔*,也无济于事。
解决方法:重新设计你的模型
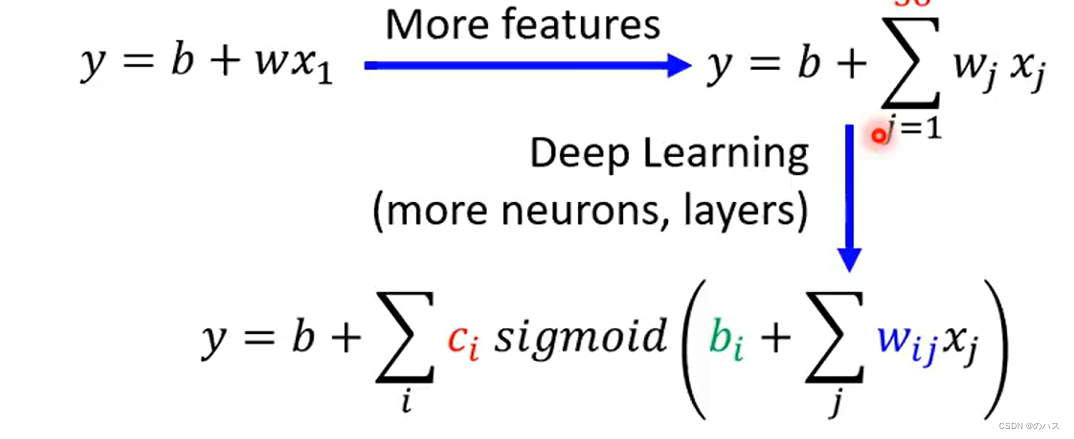
通过增加你的feature数量,或者增加神经元和层数。
(2).Optimization Issue
原因:可能你的模型中存在这样一个能让你的Loss变小的函数但是你的优化方法不能够将之找出来。
解决方法:修改你的优化方式,能够从模型中找到这个最优的函数。
(3). 如何判断是哪种原因造成了训练数据的Loss不够低
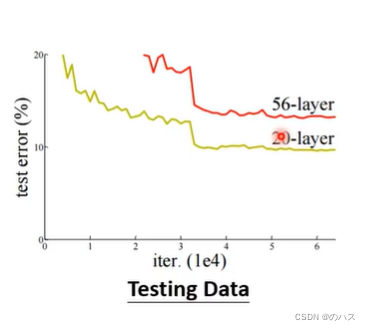
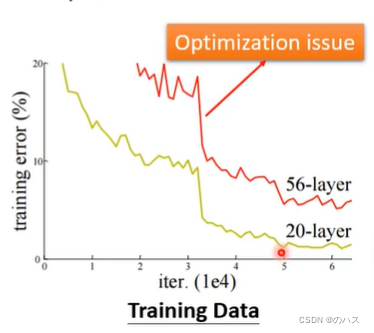
看第二张图,按理说20层能够做的事情,56层应该轻而易举就能做到,只要前二十层的参数与20层的一样就行,但是实际上他的数据还不如20层的,由前面的分析,我们可以排除Model Bias的可能,因为56层肯定是要比20层的模型更加复杂,那只能考虑是Optimization Issue了,说明Optimization做的不够好。

2. 把训练数据的Loss做的足够小时,再来分析预测数据的Loss。
这时候如果预测数据的Loss也比较小,符合预期,那么这个模型就是成功的。但如果这时候的预测数据Loss比较大,我们就需要考虑是不是overfitting的问题了
(1).Overfitting

看上例就能够理解,但这个例子确实是比较极端。
再来看看下面这个例子:
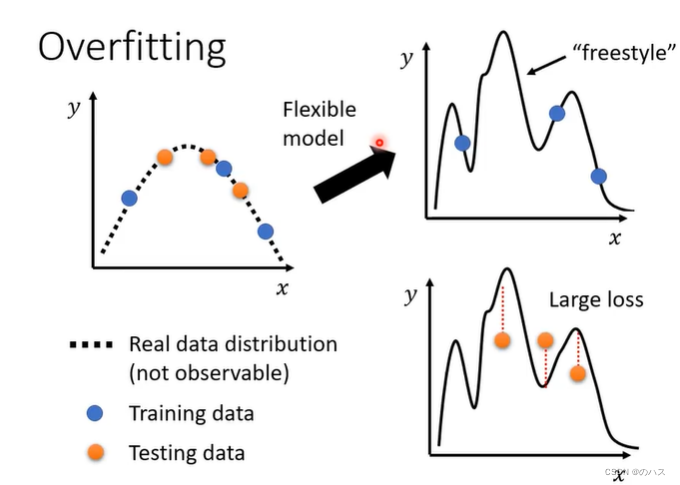
如果说这个模型比较简单,那么可能测试数据的Loss也会比较小,但是如果你的模型比较的复杂灵活,那么实际预测数据的走势就会比较不确定,对比真实的数据时的误差就会很大。
解决方法: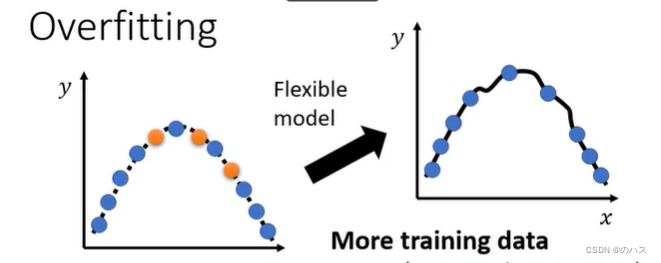
1.可以通过给更多的训练数据这样模型就会和实际更加接近。(注意训练数据一定要是合适的,不能用网上随意检索来的数据)
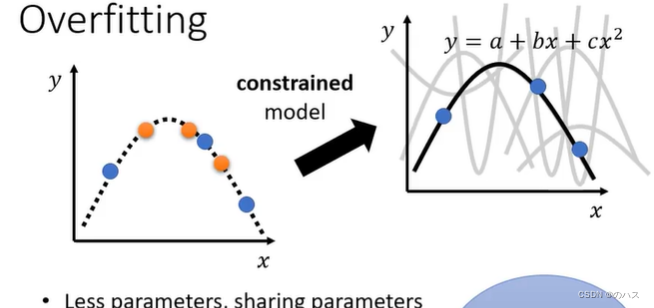
2.给你的模型一些限制,按图中例子来说,就是把模型限制成二次函数。这样就更可能与预期相符。
通过给更少的参数,或者把某些参数的值取一样。
还有就是给更少的features。
Early Stopping ,Regularization , Drop out 等方法后续还会继续学习。
注意:如果给太多的限制,问题又会回到Model Bias,所以限制一定要适当。
(2). mismatch
意思就是你的训练数据和你的测试数据分布不一样,这就会导致你的数据增加反而Loss会上升。
三、如何选择合适的Model
下图是显示随模型变复杂两个Loss大小变化情况的函数:
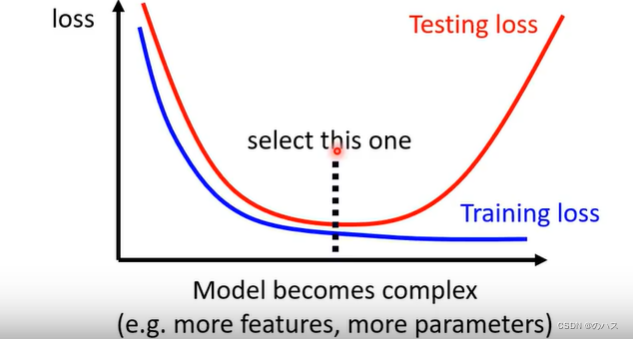
我们可以分析得出:模型越复杂,训练数据的Loss就会更低,预测数据的Loss在超过一定复杂度时就会出现Overfitting。那怎么在出现Over fitting前找到一个合适的Model呢?
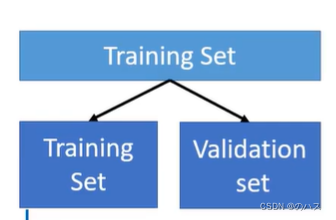
把你的训练数据分为训练和验证两部分,用训练的部分来训练模型,然后用验证数据来测试,这样得到的模型会比较合适。
那怎么分训练部分和验证部分呢。
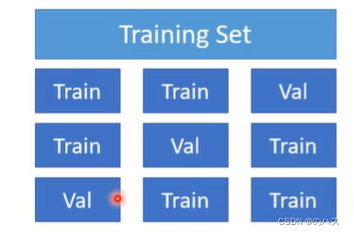
将数据等分成n份,然后每次选一部分为验证数据,然后带入模型比较结果。上图中就为分三份的情况。

















 1954
1954

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









