






1. L1&L2参数正则化
基本的思想是对参数进行约束,在保证取得最小的损失函数的同时衰减不相关特征的参数。具体可以看另外一篇博文:L1 & L2 正则化的理解
2. Dropout
集成思想,同时减少每层的神经节点之间的相互依赖。
3. 数据增强
原始的思想是扩充数据集,增强泛化能力。裁剪/翻转/颜色亮度变化。
4. 迁移学习
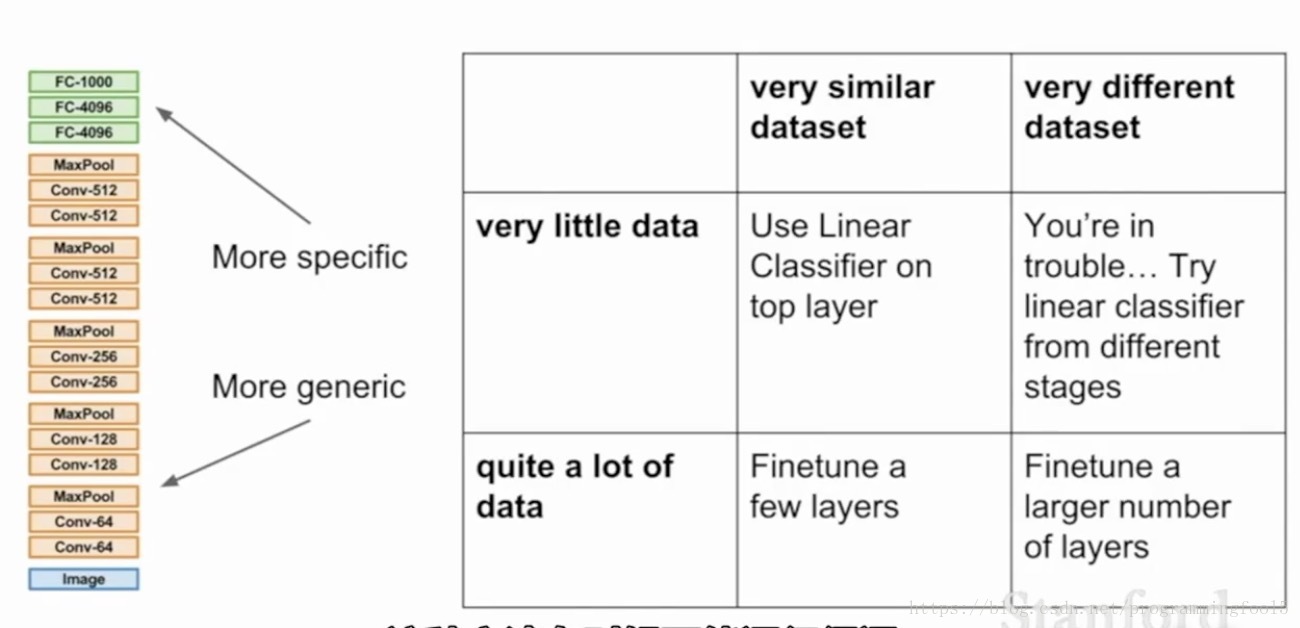
当你的数据集比较小,训练的网络过拟合,泛化能力比较差,你也可以不用大的数据集再去训练,可以采用迁移学习,即fine-tuning一个既成的网络。对于小型的数据集训练,只需要freeze前面的网络参数,然后单独学习最后的全连接层。如果你有更多的数据,那么可以逐渐训练更多的最后几层的网络。注意一个通用的策略:在学习的时候需要将学习率调的很低很低,大约只有原始训练的十分之一,因为原始的网络结构已经是收敛的了,只希望做一些微小的调整。

















 1352
1352

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









