




1. 核心目的:为何需要交叉验证?
K折交叉验证(K-Fold CV其核心目的在于提供一种更可靠、更稳健的模型性能评估方法。它通过系统性地交换训练集和验证集,来降低评估结果的偶然性,并最大化地利用所有数据。
一个常见的误解是,K折交叉验证会直接产出一个最终模型。实际上,它的主要目的是评估模型的泛化能力和进行超参数选择。在交叉验证过程中产生的k个模型通常会被丢弃。
正确的做法是:
- 使用K折交叉验证来找到最优的模型架构和超参数组合。
- 一旦确定了最佳配置,就使用这组配置,在全部的训练数据集上重新训练一个全新的模型。
- 这个最终训练出的模型,才是我们用来进行预测和部署的模型。
这种方法确保了最终模型是利用了所有可用信息训练出来的,从而具有最优的性能。
2. K折交叉验证的方法详解
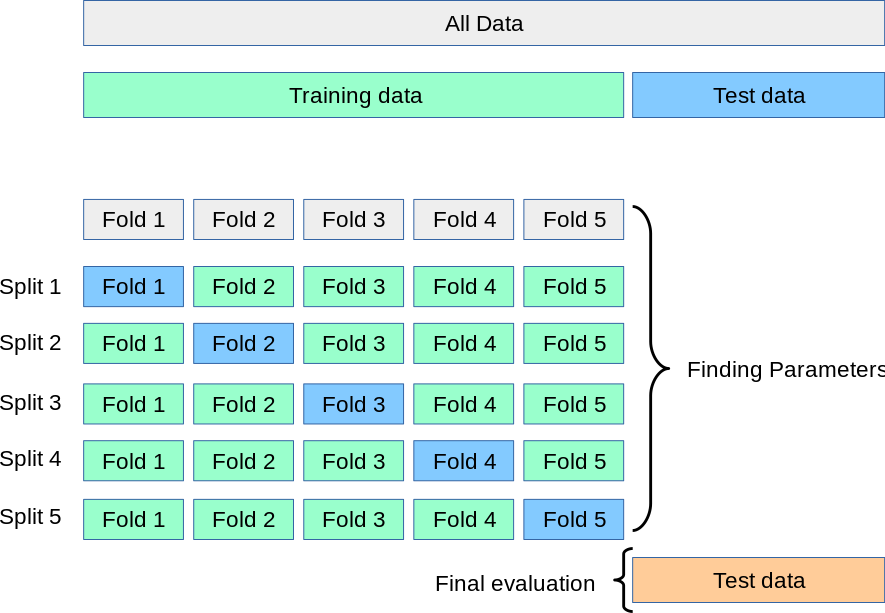
K折交叉验证遵循一个清晰、系统的流程。假设我们选择 k=10(这是一个常用的值):
-
数据划分(Split):
- 首先,将整个训练数据集随机打乱。
- 然后,将打乱后的数据集平均分割成 k 个互不相交的子集(称为“折”,fold)。每个子集都包含大约
N/k个样本(N是总样本数)。
-
循环训练与验证(Iterate):
- 接下来,进行 k 次循环。在每一次循环中:
- 选择一个不同的折作为验证集(Validation Set)。
- 将其余的 k-1 个折合并起来,作为训练集(Training Set)。
- 使用这个训练集来训练模型,然后在选定的验证集上评估模型性能(例如,计算准确率、F1分数、MSE等)。
- 接下来,进行 k 次循环。在每一次循环中:
-
性能汇总(Aggregate):
- 完成 k 次循环后,我们会得到 k 个性能评估指标(例如,10个验证准确率)。
- 通常,我们会计算这 k 个指标的平均值和标准差。
- 平均值:作为模型最终性能的一个更稳健的估计。
- 标准差:反映了模型性能在不同数据子集上的波动情况。标准差越小,说明模型性能越稳定。
(图片来源:scikit-learn文档)
这个过程确保了数据集中的每一个样本都有且仅有一次机会被用作验证,从而使得评估结果更加公平和可靠。
3. 分层K折交叉验证(Stratified K-Fold CV)
3.1 为何需要分层?
在标准的K折交叉验证中,数据是随机划分的。这在大多数情况下工作良好,但当遇到**类别不均衡(Class Imbalance)**的数据集时,可能会出现问题。
例如,在一个二分类问题中,90%的样本属于类别A,只有10%属于类别B。在随机划分时,某个折中可能碰巧一个类别B的样本都没有。如果这个折被用作验证集,那么模型在这个折上的表现评估将毫无意义,因为它根本没有见到稀有类别的样本。
3.2 分层的细节
分层K折交叉验证(Stratified K-Fold CV专门为了解决这个问题而设计。它的核心思想是:在划分数据时,确保每个折中的类别比例与原始数据集中完全一致。
- 划分方法:它不是将整个数据集作为一个整体来随机划分,而是分别对每个类别的数据进行独立的随机划分。例如,它会从类别A的样本中取出1/k,从类别B的样本中也取出1/k,然后将它们组合成第一个折。这个过程重复k次,从而保证了每个折都含有与原始数据集相同比例的A类和B类样本。
3.3 何时使用?
强烈建议在所有分类任务中,尤其是当类别分布不均衡时,优先使用分层K折交叉验证。 它可以提供更稳定、更具代表性的性能评估,避免因随机划分带来的偏差。对于回归任务,则通常使用标准的K折交叉验证。


















 969
969

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











