








Java 提供了两种内置的锁的实现,一种是由 JVM 实现的 synchronized 和 JDK 提供的 Lock,当你的应用是单机或者说单进程应用时,可以使用 synchronized 或 Lock 来实现锁。当应用涉及到多机、多进程共同完成时,那么这时候就需要一个全局锁来实现多个进程之间的同步。
- 使用场景
例如一个应用有手机 APP 端和 Web 端,如果在两个客户端同时进行一项操作时,那么就会导致这项操作重复进行。
2. 实现方式
2.1 数据库分布式锁
基于 MySQL 锁表
该实现方式完全依靠数据库唯一索引来实现。当想要获得锁时,就向数据库中插入一条记录,释放锁时就删除这条记录。如果记录具有唯一索引,就不会同时插入同一条记录。这种方式存在以下几个问题:
锁没有失效时间,解锁失败会导致死锁,其他线程无法再获得锁。
只能是非阻塞锁,插入失败直接就报错了,无法重试。
不可重入,同一线程在没有释放锁之前无法再获得锁。
采用乐观锁增加版本号
根据版本号来判断更新之前有没有其他线程更新过,如果被更新过,则获取锁失败。
2.2 Redis 分布式锁
基于 SETNX、EXPIRE
使用 SETNX(set if not exist)命令插入一个键值对时,如果 Key 已经存在,那么会返回 False,否则插入成功并返回 True。因此客户端在尝试获得锁时,先使用 SETNX 向 Redis 中插入一个记录,如果返回 True 表示获得锁,返回 False 表示已经有客户端占用锁。
EXPIRE 可以为一个键值对设置一个过期时间,从而避免了死锁的发生。
RedLock 算法
ReadLock 算法使用了多个 Redis 实例来实现分布式锁,这是为了保证在发生单点故障时还可用。
尝试从 N 个相互独立 Redis 实例获取锁,如果一个实例不可用,应该尽快尝试下一个。
计算获取锁消耗的时间,只有当这个时间小于锁的过期时间,并且从大多数(N/2+1)实例上获取了锁,那么就认为锁获取成功了。
如果锁获取失败,会到每个实例上释放锁。
2.3 Zookeeper 分布式锁
Zookeeper 是一个为分布式应用提供一致性服务的软件,例如配置管理、分布式协同以及命名的中心化等,这些都是分布式系统中非常底层而且是必不可少的基本功能,但是如果自己实现这些功能而且要达到高吞吐、低延迟同时还要保持一致性和可用性,实际上非常困难。
抽象模型
Zookeeper 提供了一种树形结构级的命名空间,/app1/p_1 节点表示它的父节点为 /app1。
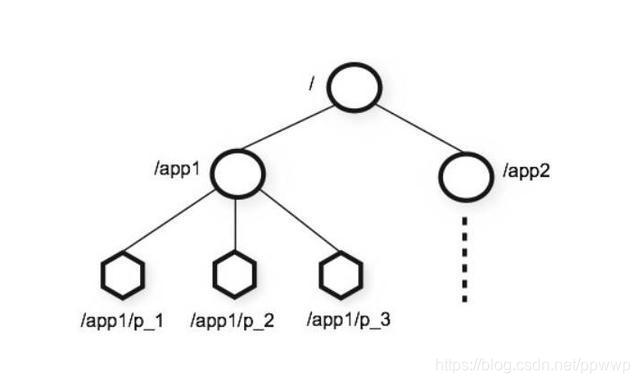
节点类型
永久节点:不会因为会话结束或者超时而消失;
临时节点:如果会话结束或者超时就会消失;
有序节点:会在节点名的后面加一个数字后缀,并且是有序的,例如生成的有序节点为 /lock/node-0000000000,它的下一个有序节点则为 /lock/node-0000000001,依次类推。
监听器
为一个节点注册监听器,在节点状态发生改变时,会给客户端发送消息。
分布式锁实现
创建一个锁目录 /lock。
在 /lock 下创建临时的且有序的子节点,第一个客户端对应的子节点为 /lock/lock-0000000000,第二个为 /lock/lock-0000000001,以此类推。
客户端获取 /lock 下的子节点列表,判断自己创建的子节点是否为当前子节点列表中序号最小的子节点,如果是则认为获得锁,否则监听自己的前一个子节点,获得子节点的变更通知后重复此步骤直至获得锁;
执行业务代码,完成后,删除对应的子节点。
会话超时
如果一个已经获得锁的会话超时了,因为创建的是临时节点,因此该会话对应的临时节点会被删除,其它会话就可以获得锁了。可以看到,Zookeeper 分布式锁不会出现数据库分布式锁的死锁问题。
羊群效应
在步骤二,一个节点未获得锁,需要监听监听自己的前一个子节点,这是因为如果监听所有的子节点,那么任意一个子节点状态改变,其它所有子节点都会收到通知,而我们只希望它的下一个子节点收到通知。
分布式 Session
如果不做任何处理的话,用户将出现频繁登录的现象,比如集群中存在 A、B 两台服务器,用户在第一次访问网站时,Nginx 通过其负载均衡机制将用户请求转发到 A 服务器,这时 A 服务器就会给用户创建一个 Session。当用户第二次发送请求时,Nginx 将其负载均衡到 B 服务器,而这时候 B 服务器并不存在 Session,所以就会将用户踢到登录页面。这将大大降低用户体验度,导致用户的流失,这种情况是项目绝不应该出现的。
- 粘性 Session
原理
粘性 Session 是指将用户锁定到某一个服务器上,比如上面说的例子,用户第一次请求时,负载均衡器将用户的请求转发到了 A 服务器上,如果负载均衡器设置了粘性 Session 的话,那么用户以后的每次请求都会转发到 A 服务器上,相当于把用户和 A 服务器粘到了一块,这就是粘性 Session 机制。
优点
简单,不需要对 Session 做任何处理。
缺点
缺乏容错性,如果当前访问的服务器发生故障,用户被转移到第二个服务器上时,他的 Session 信息都将失效。
适用场景
发生故障对客户产生的影响较小;
服务器发生故障是低概率事件。
- 服务器 Session 复制
原理
任何一个服务器上的 Session 发生改变,该节点会把这个 Session 的所有内容序列化,然后广播给所有其它节点,不管其他服务器需不需要 Session,以此来保证 Session 同步。
优点
可容错,各个服务器间 Session 能够实时响应。
缺点
会对网络负荷造成一定压力,如果 Session 量大的话可能会造成网络堵塞,拖慢服务器性能。
实现方式
设置 Tomcat 的 server.xml 开启 tomcat 集群功能。
在应用里增加信息:通知应用当前处于集群环境中,支持分布式,即在 web.xml 中添加 选项。
- Session 共享机制
使用分布式缓存方案比如 Memcached、Redis,但是要求 Memcached 或 Redis 必须是集群。
使用 Session 共享也分两种机制,两种情况如下:
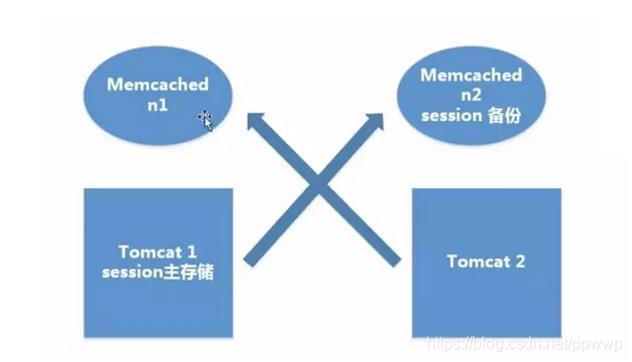
3.1 粘性 Session 共享机制
和粘性 Session 一样,一个用户的 Session 会绑定到一个 Tomcat 上。Memcached 只是起到备份作用。
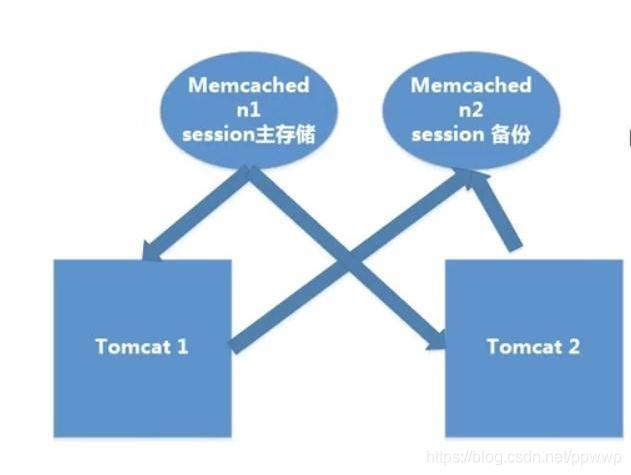
3.2 非粘性 Session 共享机制
原理
Tomcat 本身不存储 Session,而是存入 Memcached 中。Memcached 集群构建主从复制架构
优点
可容错,Session 实时响应。
实现方式
用开源的 msm 插件解决 Tomcat 之间的 Session 共享:Memcached_Session_Manager(MSM)
- Session 持久化到数据库
原理
拿出一个数据库,专门用来存储 Session 信息。保证 Session 的持久化。
优点
服务器出现问题,Session 不会丢失
缺点
如果网站的访问量很大,把 Session 存储到数据库中,会对数据库造成很大压力,还需要增加额外的开销维护数据库。
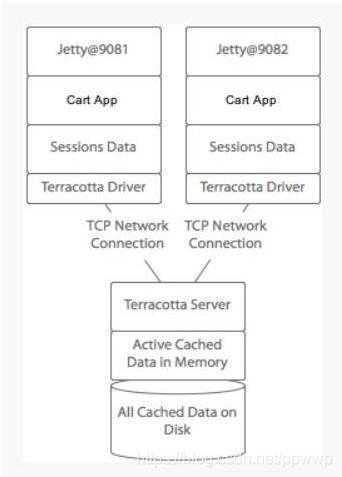
- Terracotta 实现 Session 复制
原理
Terracotta 的基本原理是对于集群间共享的数据,当在一个节点发生变化的时候,Terracotta 只把变化的部分发送给 Terracotta 服务器,然后由服务器把它转发给真正需要这个数据的节点。它是服务器 Session 复制的优化。
优点
这样对网络的压力就非常小,各个节点也不必浪费 CPU 时间和内存进行大量的序列化操作。把这种集群间数据共享的机制应用在 Session 同步上,既避免了对数据库的依赖,又能达到负载均衡和灾难恢复的效果。
分库与分表带来的分布式困境与应对之策
- 事务问题
使用分布式事务。
- 查询问题
使用汇总表。
- ID 唯一性
使用全局唯一 ID:GUID;
为每个分片指定一个 ID 范围。

















 807
807

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









