



嗯,论文小白经验贴一枚
非常感谢csdn大佬们的帖子,受益颇多
自己复现过程中也出现了一些问题,希望能够帮助到你
1. cuda显存不足问题
具体症状表现为,能正常运行,进度条跑着跑着就g了
在data_util文件中,修改函数为
def expmap2rotmat(r):
"""
Converts an exponential map angle to a rotation matrix
Matlab port to python for evaluation purposes
I believe this is also called Rodrigues' formula
https://github.com/asheshjain399/RNNexp/blob/srnn/structural_rnn/CRFProblems/H3.6m/mhmublv/Motion/expmap2rotmat.m
Args
r: 1x3 exponential map
Returns
R: 3x3 rotation matrix
"""
theta = np.linalg.norm(r)
r0 = np.divide(r, theta + np.finfo(np.float32).eps)
r0x = np.array([0, -r0[2], r0[1], 0, 0, -r0[0], 0, 0, 0]).reshape(3, 3)
r0x = r0x - r0x.T
R = np.eye(3, 3) + np.sin(theta) * r0x + (1 - np.cos(theta)) * (r0x).dot(r0x);
return R
(不知道为啥,但非常有效,感谢大佬和jl姐)
2. main函数运行过程中的问题
运行一直报错,意思是其中的维度问题,其实里面是个标量,把对应位置的【0】去掉就行
能够运行的main函数如下贴出来:
关键是生成的都是标量,把后面的【0】给去了
#!/usr/bin/env python
# -*- coding: utf-8 -*-
"""overall code framework is adapped from https://github.com/weigq/3d_pose_baseline_pytorch"""
from __future__ import print_function, absolute_import, division
import os
os.environ["PYTORCH_CUDA_ALLOC_CONF"] = "max_split_size_mb:128"
import os
import time
import torch
import torch.nn as nn
import torch.optim
from torch.utils.data import DataLoader
from torch.autograd import Variable
import numpy as np
from progress.bar import Bar
import pandas as pd
from utils import loss_funcs, utils as utils
from utils.opt import Options
from utils.h36motion import H36motion
import utils.model as nnmodel
import utils.data_utils as data_utils
import torch, gc
gc.collect()
torch.cuda.empty_cache()
torch.cuda.reset_peak_memory_stats()
def main(opt):
start_epoch = 0
err_best = 10000
lr_now = opt.lr
is_cuda = torch.cuda.is_available()
# define log csv file
script_name = os.path.basename(__file__).split('.')[0]
script_name = script_name + "_in{:d}_out{:d}_dctn{:d}".format(opt.input_n, opt.output_n, opt.dct_n)
# create model
print(">>> creating model")
input_n = opt.input_n
output_n = opt.output_n
dct_n = opt.dct_n
sample_rate = opt.sample_rate
# 48 nodes for angle prediction
model = nnmodel.GCN(input_feature=dct_n, hidden_feature=opt.linear_size, p_dropout=opt.dropout,
num_stage=opt.num_stage, node_n=48)
if is_cuda:
model.cuda()
print(">>> total params: {:.2f}M".format(sum(p.numel() for p in model.parameters()) / 1000000.0))
optimizer = torch.optim.Adam(model.parameters(), lr=opt.lr)
# continue from checkpoint
if opt.is_load:
model_path_len = 'checkpoint/test/ckpt_main_gcn_muti_att_best.pth.tar'
print(">>> loading ckpt len from '{}'".format(model_path_len))
if is_cuda:
ckpt = torch.load(model_path_len)
else:
ckpt = torch.load(model_path_len, map_location='cpu')
start_epoch = ckpt['epoch']
err_best = ckpt['err']
lr_now = ckpt['lr']
model.load_state_dict(ckpt['state_dict'])
optimizer.load_state_dict(ckpt['optimizer'])
print(">>> ckpt len loaded (epoch: {} | err: {})".format(start_epoch, err_best))
# data loading
print(">>> loading data")
train_dataset = H36motion(path_to_data=opt.data_dir, actions='all', input_n=input_n, output_n=output_n,
split=0, sample_rate=sample_rate, dct_n=dct_n)
data_std = train_dataset.data_std
data_mean = train_dataset.data_mean
val_dataset = H36motion(path_to_data=opt.data_dir, actions='all', input_n=input_n, output_n=output_n,
split=2, sample_rate=sample_rate, data_mean=data_mean, data_std=data_std, dct_n=dct_n)
# load dadasets for training
train_loader = DataLoader(
dataset=train_dataset,
batch_size=opt.train_batch,
shuffle=True,
num_workers=opt.job,
pin_memory=True)
val_loader = DataLoader(
dataset=val_dataset,
batch_size=opt.test_batch,
shuffle=False,
num_workers=opt.job,
pin_memory=True)
acts = data_utils.define_actions('all')
test_data = dict()
for act in acts:
test_dataset = H36motion(path_to_data=opt.data_dir, actions=act, input_n=input_n, output_n=output_n, split=1,
sample_rate=sample_rate, data_mean=data_mean, data_std=data_std, dct_n=dct_n)
test_data[act] = DataLoader(
dataset=test_dataset,
batch_size=opt.test_batch,
shuffle=False,
num_workers=opt.job,
pin_memory=True)
print(">>> data loaded !")
print(">>> train data {}".format(train_dataset.__len__()))
print(">>> validation data {}".format(val_dataset.__len__()))
for epoch in range(start_epoch, opt.epochs):
if (epoch + 1) % opt.lr_decay == 0:
lr_now = utils.lr_decay(optimizer, lr_now, opt.lr_gamma)
print('==========================')
print('>>> epoch: {} | lr: {:.5f}'.format(epoch + 1, lr_now))
ret_log = np.array([epoch + 1])
head = np.array(['epoch'])
# per epoch
lr_now, t_l, t_e, t_3d = train(train_loader, model, optimizer, input_n=input_n,
lr_now=lr_now, max_norm=opt.max_norm, is_cuda=is_cuda,
dim_used=train_dataset.dim_used, dct_n=dct_n)
ret_log = np.append(ret_log, [lr_now, t_l, t_e, t_3d])
head = np.append(head, ['lr', 't_l', 't_e', 't_3d'])
v_e, v_3d = val(val_loader, model, input_n=input_n, is_cuda=is_cuda, dim_used=train_dataset.dim_used,
dct_n=dct_n)
ret_log = np.append(ret_log, [v_e, v_3d])
head = np.append(head, ['v_e', 'v_3d'])
test_3d_temp = np.array([])
test_3d_head = np.array([])
for act in acts:
test_e, test_3d = test(test_data[act], model, input_n=input_n, output_n=output_n, is_cuda=is_cuda,
dim_used=train_dataset.dim_used, dct_n=dct_n)
ret_log = np.append(ret_log, test_e)
test_3d_temp = np.append(test_3d_temp, test_3d)
test_3d_head = np.append(test_3d_head,
[act + '3d80', act + '3d160', act + '3d320', act + '3d400'])
head = np.append(head, [act + '80', act + '160', act + '320', act + '400'])
if output_n > 10:
head = np.append(head, [act + '560', act + '1000'])
test_3d_head = np.append(test_3d_head,
[act + '3d560', act + '3d1000'])
ret_log = np.append(ret_log, test_3d_temp)
head = np.append(head, test_3d_head)
# update log file and save checkpoint
df = pd.DataFrame(np.expand_dims(ret_log, axis=0))
if epoch == start_epoch:
df.to_csv(opt.ckpt + '/' + script_name + '.csv', header=head, index=False)
else:
with open(opt.ckpt + '/' + script_name + '.csv', 'a') as f:
df.to_csv(f, header=False, index=False)
if not np.isnan(v_e):
is_best = v_e < err_best
err_best = min(v_e, err_best)
else:
is_best = False
file_name = ['ckpt_' + script_name + '_best.pth.tar', 'ckpt_' + script_name + '_last.pth.tar']
utils.save_ckpt({'epoch': epoch + 1,
'lr': lr_now,
'err': test_e[0],
'state_dict': model.state_dict(),
'optimizer': optimizer.state_dict()},
ckpt_path=opt.ckpt,
is_best=is_best,
file_name=file_name)
def train(train_loader, model, optimizer, input_n=20, dct_n=20, lr_now=None, max_norm=True, is_cuda=False, dim_used=[]):
t_l = utils.AccumLoss()
t_e = utils.AccumLoss()
t_3d = utils.AccumLoss()
model.train()
st = time.time()
bar = Bar('>>>', fill='>', max=len(train_loader))
for i, (inputs, targets, all_seq) in enumerate(train_loader):
# skip the last batch if only have one sample for batch_norm layers
batch_size = inputs.shape[0]
if batch_size == 1:
continue
bt = time.time()
if is_cuda:
inputs = Variable(inputs.cuda()).float()
# targets = Variable(targets.cuda(async=True)).float()
all_seq = Variable(all_seq.cuda(non_blocking=True)).float()
outputs = model(inputs)
n = outputs.shape[0]
outputs = outputs.view(n, -1)
# targets = targets.view(n, -1)
loss = loss_funcs.sen_loss(outputs, all_seq, dim_used, dct_n)
# calculate loss and backward
optimizer.zero_grad()
loss.backward()
if max_norm:
nn.utils.clip_grad_norm_(model.parameters(), max_norm=1)
optimizer.step()
n, _, _ = all_seq.data.shape
# 3d error
m_err = loss_funcs.mpjpe_error(outputs, all_seq, input_n, dim_used, dct_n)
# angle space error
e_err = loss_funcs.euler_error(outputs, all_seq, input_n, dim_used, dct_n)
# update the training loss
t_l.update(loss.cpu().data.numpy() * n, n)
t_e.update(e_err.cpu().data.numpy() * n, n)
t_3d.update(m_err.cpu().data.numpy() * n, n)
bar.suffix = '{}/{}|batch time {:.4f}s|total time{:.2f}s'.format(i + 1, len(train_loader), time.time() - bt,
time.time() - st)
bar.next()
bar.finish()
return lr_now, t_l.avg, t_e.avg, t_3d.avg
def test(train_loader, model, input_n=20, output_n=50, dct_n=20, is_cuda=False, dim_used=[]):
N = 0
# t_l = 0
if output_n >= 25:
eval_frame = [1, 3, 7, 9, 13, 24]
elif output_n == 10:
eval_frame = [1, 3, 7, 9]
t_e = np.zeros(len(eval_frame))
t_3d = np.zeros(len(eval_frame))
model.eval()
st = time.time()
bar = Bar('>>>', fill='>', max=len(train_loader))
for i, (inputs, targets, all_seq) in enumerate(train_loader):
bt = time.time()
if is_cuda:
inputs = Variable(inputs.cuda()).float()
# targets = Variable(targets.cuda(async=True)).float()
all_seq = Variable(all_seq.cuda(non_blocking=True)).float()
outputs = model(inputs)
n = outputs.shape[0]
# outputs = outputs.view(n, -1)
# targets = targets.view(n, -1)
# loss = loss_funcs.sen_loss(outputs, all_seq, dim_used)
n, seq_len, dim_full_len = all_seq.data.shape
dim_used_len = len(dim_used)
# inverse dct transformation
_, idct_m = data_utils.get_dct_matrix(seq_len)
idct_m = Variable(torch.from_numpy(idct_m)).float().cuda()
outputs_t = outputs.view(-1, dct_n).transpose(0, 1)
outputs_exp = torch.matmul(idct_m[:, :dct_n], outputs_t).transpose(0, 1).contiguous().view(-1, dim_used_len,
seq_len).transpose(1,
2)
pred_expmap = all_seq.clone()
dim_used = np.array(dim_used)
pred_expmap[:, :, dim_used] = outputs_exp
pred_expmap = pred_expmap[:, input_n:, :].contiguous().view(-1, dim_full_len)
targ_expmap = all_seq[:, input_n:, :].clone().contiguous().view(-1, dim_full_len)
pred_expmap[:, 0:6] = 0
targ_expmap[:, 0:6] = 0
pred_expmap = pred_expmap.view(-1, 3)
targ_expmap = targ_expmap.view(-1, 3)
# get euler angles from expmap
pred_eul = data_utils.rotmat2euler_torch(data_utils.expmap2rotmat_torch(pred_expmap))
pred_eul = pred_eul.view(-1, dim_full_len).view(-1, output_n, dim_full_len)
targ_eul = data_utils.rotmat2euler_torch(data_utils.expmap2rotmat_torch(targ_expmap))
targ_eul = targ_eul.view(-1, dim_full_len).view(-1, output_n, dim_full_len)
# get 3d coordinates
targ_p3d = data_utils.expmap2xyz_torch(targ_expmap.view(-1, dim_full_len)).view(n, output_n, -1, 3)
pred_p3d = data_utils.expmap2xyz_torch(pred_expmap.view(-1, dim_full_len)).view(n, output_n, -1, 3)
# update loss and testing errors
for k in np.arange(0, len(eval_frame)):
j = eval_frame[k]
t_e[k] += torch.mean(torch.norm(pred_eul[:, j, :] - targ_eul[:, j, :], 2, 1)).cpu().data.numpy()* n
t_3d[k] += torch.mean(torch.norm(
targ_p3d[:, j, :, :].contiguous().view(-1, 3) - pred_p3d[:, j, :, :].contiguous().view(-1, 3), 2,
1)).cpu().data.numpy() * n
# t_l += loss.cpu().data.numpy()[0] * n
N += n
bar.suffix = '{}/{}|batch time {:.4f}s|total time{:.2f}s'.format(i + 1, len(train_loader), time.time() - bt,
time.time() - st)
bar.next()
bar.finish()
return t_e / N, t_3d / N
def val(train_loader, model, input_n=20, dct_n=20, is_cuda=False, dim_used=[]):
# t_l = utils.AccumLoss()
t_e = utils.AccumLoss()
t_3d = utils.AccumLoss()
model.eval()
st = time.time()
bar = Bar('>>>', fill='>', max=len(train_loader))
for i, (inputs, targets, all_seq) in enumerate(train_loader):
bt = time.time()
if is_cuda:
inputs = Variable(inputs.cuda()).float()
# targets = Variable(targets.cuda(async=True)).float()
all_seq = Variable(all_seq.cuda(non_blocking=True)).float()
outputs = model(inputs)
n = outputs.shape[0]
outputs = outputs.view(n, -1)
# targets = targets.view(n, -1)
# loss = loss_funcs.sen_loss(outputs, all_seq, dim_used)
n, _, _ = all_seq.data.shape
m_err = loss_funcs.mpjpe_error(outputs, all_seq, input_n, dim_used, dct_n)
e_err = loss_funcs.euler_error(outputs, all_seq, input_n, dim_used, dct_n)
# t_l.update(loss.cpu().data.numpy()[0] * n, n)
t_e.update(e_err.cpu().data.numpy() * n, n)
t_3d.update(m_err.cpu().data.numpy() * n, n)
bar.suffix = '{}/{}|batch time {:.4f}s|total time{:.2f}s'.format(i + 1, len(train_loader), time.time() - bt,
time.time() - st)
bar.next()
bar.finish()
return t_e.avg, t_3d.avg
if __name__ == "__main__":
option = Options().parse()
main(option)
3. 训练过程中Numpy版本太新问题
复现过程中,我用了最新的Numpy,导致过程返回,说的大意是形状问题
修改为如下即可(主要是后面这个dtype要加上,就好了)
subs = np.array([[1, 6, 7, 8, 9], [5], [11]], dtype=object)
4. 保存问题
由于服务器上运行,plot库运行无法返回结果,我们最好存储为gif,更好的展示
创建个新文件newdemo来运行,运行出来是分离的gif
#!/usr/bin/env python
# -*- coding: utf-8 -*-
from __future__ import print_function, absolute_import, division
import imageio
from tqdm import tqdm
import os
import time
import torch
import torch.nn as nn
import torch.optim
from torch.utils.data import DataLoader
from torch.autograd import Variable
from torch.nn import functional
import numpy as np
from progress.bar import Bar
import pandas as pd
from matplotlib import pyplot as plt
from utils import loss_funcs, utils as utils
from utils.opt import Options
from utils.h36motion import H36motion
import utils.model as nnmodel
import utils.data_utils as data_utils
import utils.viz as viz
def main(opt):
is_cuda = torch.cuda.is_available()
# create model
print(">>> creating model")
input_n = opt.input_n
output_n = opt.output_n
sample_rate = opt.sample_rate
model = nnmodel.GCN(input_feature=(input_n + output_n), hidden_feature=opt.linear_size, p_dropout=opt.dropout,
num_stage=opt.num_stage, node_n=48)
if is_cuda:
model.cuda()
model_path_len = '/root/LearnTrajDep/checkpoint/test/ckpt_main_in10_out10_dctn20_best.pth.tar'
print(">>> loading ckpt len from '{}'".format(model_path_len))
if is_cuda:
ckpt = torch.load(model_path_len)
else:
ckpt = torch.load(model_path_len, map_location='cpu')
err_best = ckpt['err']
start_epoch = ckpt['epoch']
model.load_state_dict(ckpt['state_dict'])
print(">>> ckpt len loaded (epoch: {} | err: {})".format(start_epoch, err_best))
# data loading
print(">>> loading data")
acts = data_utils.define_actions('all')
test_data = dict()
for act in acts:
test_dataset = H36motion(path_to_data=opt.data_dir, actions=act, input_n=input_n, output_n=output_n, split=1,
sample_rate=sample_rate)
test_data[act] = DataLoader(
dataset=test_dataset,
batch_size=opt.test_batch,
shuffle=False,
num_workers=opt.job,
pin_memory=True)
dim_used = test_dataset.dim_used
print(">>> data loaded !")
model.eval()
with torch.no_grad(): # 确保我们在评估模式下不计算梯度
for act in acts:
frames = [] # 初始化用于保存当前动作GIF帧的列表
fig = plt.figure()
ax = fig.add_subplot(111, projection='3d')
for i, (inputs, targets, all_seq) in enumerate(test_data[act]):
inputs = Variable(inputs).float()
all_seq = Variable(all_seq).float()
if is_cuda:
inputs = inputs.cuda()
all_seq = all_seq.cuda()
outputs = model(inputs)
n, seq_len, dim_full_len = all_seq.data.shape
dim_used_len = len(dim_used)
_, idct_m = data_utils.get_dct_matrix(seq_len)
idct_m = Variable(torch.from_numpy(idct_m)).float().cuda()
outputs_t = outputs.view(-1, seq_len).transpose(0, 1)
outputs_exp = torch.matmul(idct_m, outputs_t).transpose(0, 1).contiguous().view(-1, dim_used_len,
seq_len).transpose(1, 2)
pred_expmap = all_seq.clone()
dim_used = np.array(dim_used)
pred_expmap[:, :, dim_used] = outputs_exp
targ_expmap = all_seq
pred_expmap = pred_expmap.cpu().data.numpy()
targ_expmap = targ_expmap.cpu().data.numpy()
for k in range(8):
plt.cla()
figure_title = "action:{}, seq:{},".format(act, (k + 1))
viz.plot_predictions(targ_expmap[k, :, :], pred_expmap[k, :, :], fig, ax, figure_title)
# 将当前图形转换为图像并添加到frames列表中
fig.canvas.draw() # 绘制图形
frame = np.frombuffer(fig.canvas.tostring_rgb(), dtype=np.uint8)
frame = frame.reshape(fig.canvas.get_width_height()[::-1] + (3,))
frames.append(frame)
plt.pause(0.01) # 减少暂停时间以加快处理速度
# 保存当前动作的所有帧为GIF文件
gif_filename = f'output_{act}.gif'
print(f"Saving GIF to {gif_filename}")
imageio.mimsave(gif_filename, frames, format='GIF', duration=0.5) # duration设置每帧之间的时间间隔
plt.close(fig) # 关闭当前动作的图窗以释放资源
if __name__ == "__main__":
option = Options().parse()
main(option)
运行结果大概是这样的(应该出来15个动作,下面举出四个例子)


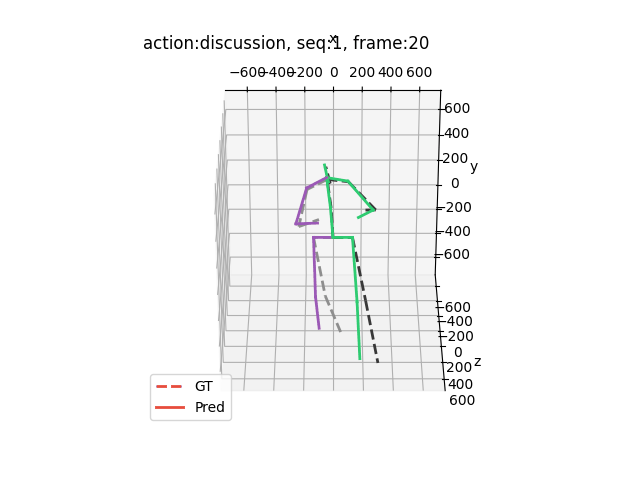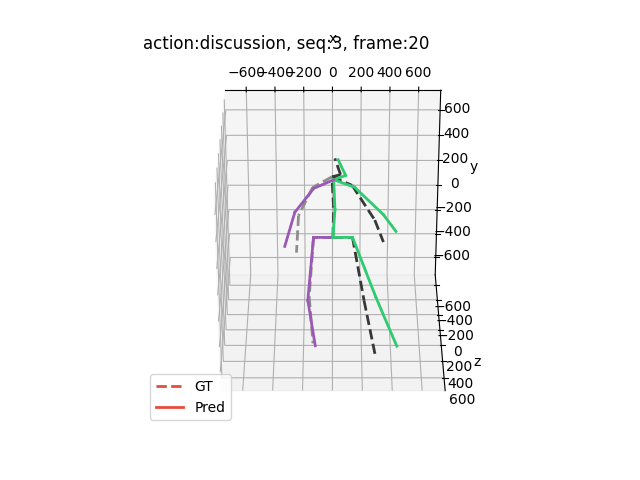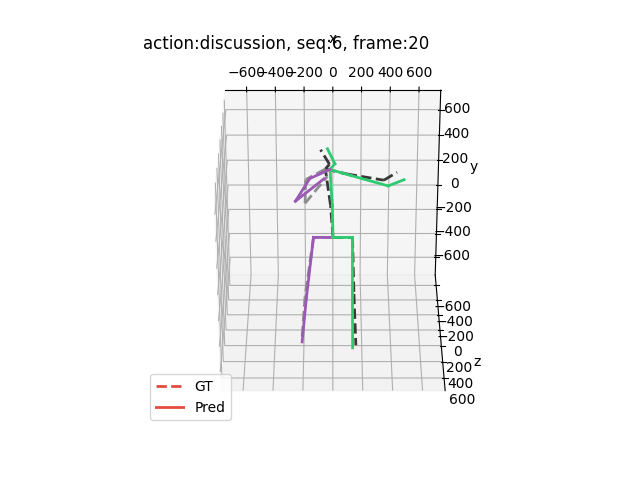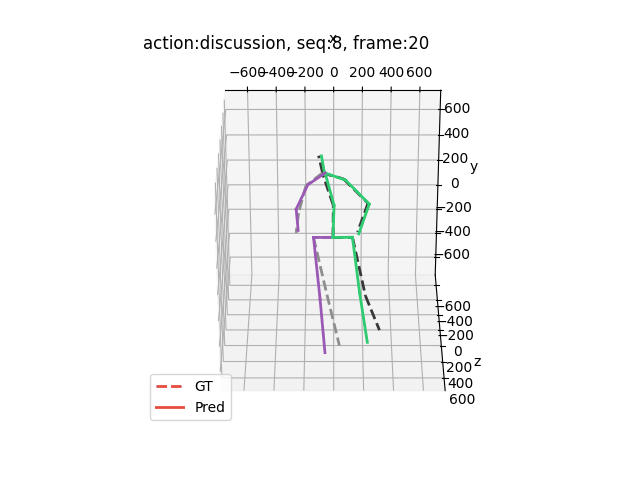
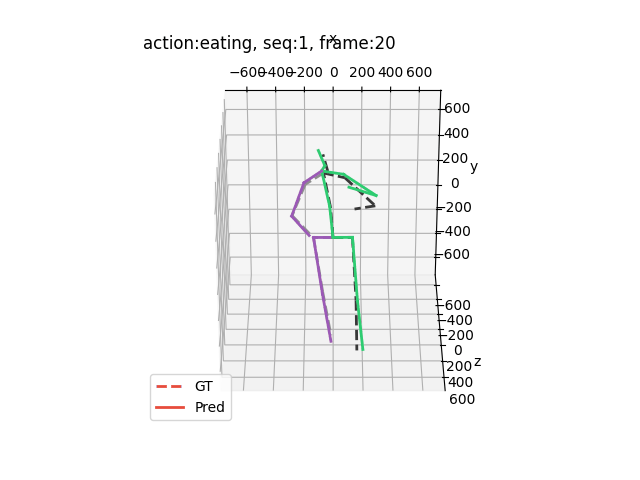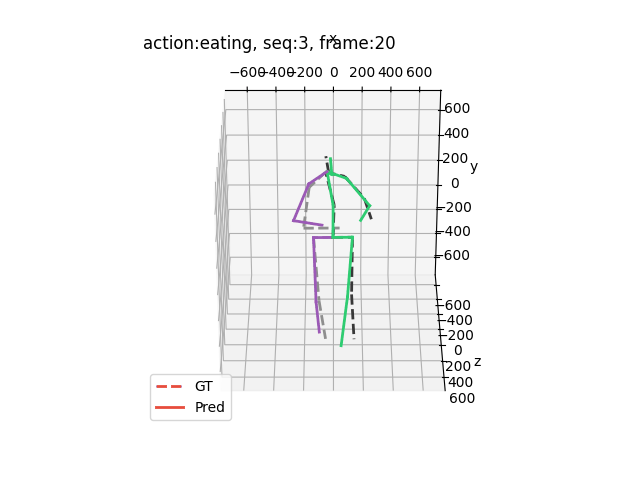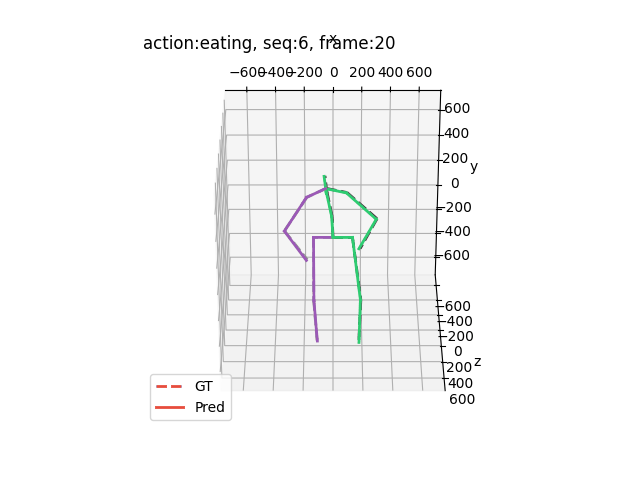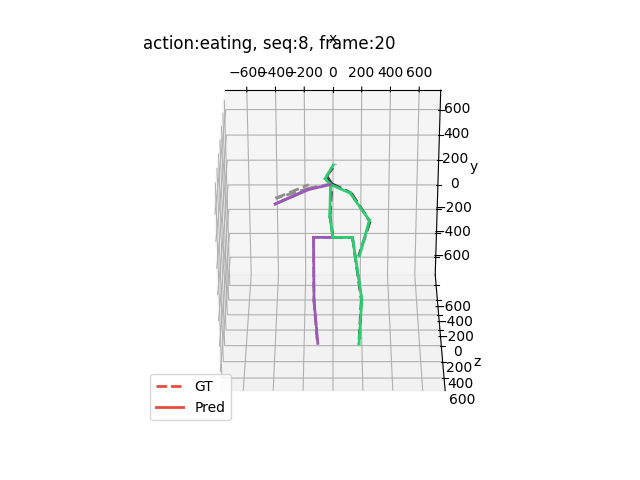
希望能够帮助到你哦!




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









