







 本文详细介绍了HDFS中Secondary Namenode的角色和功能,包括元数据持久化的重要性、过程以及在系统安全中的作用。通过比喻和步骤解析,阐述了Secondary Namenode如何协助Namenode进行edits日志与fsimage的合并,确保在Namenode宕机时能恢复集群状态。
本文详细介绍了HDFS中Secondary Namenode的角色和功能,包括元数据持久化的重要性、过程以及在系统安全中的作用。通过比喻和步骤解析,阐述了Secondary Namenode如何协助Namenode进行edits日志与fsimage的合并,确保在Namenode宕机时能恢复集群状态。
各司其职
上来就举个栗子:
namenode 我们这里说是总裁 简称NN
datanode 员工 简称DN
secondary namenode 副总 简称SNN
为什要有这个副总呢?老板手里活太多了,需要一个人帮助,那么他能把这些机密的文件给秘书么,显然不能,所以副总就现身了。
NN掌握一批元数据 (元数据就是描述数据的数据,比如数据库的字段是描述数据的)
有了数据呢,就要保证元数据的安全--------将内存中的数据存放到磁盘中------这就是实现持久化
内存
这里简单说下内存
硬盘 内存大,便宜,但是慢
内存 内存小,贵,但是快
安全问题
这样来说:
当我们你的集群因为断电等特殊原因产生问我的时候,问题解决,重新开机,会去磁盘上读取元数据,恢复到断电前的状态
NN不能进行持久化的原因
1.能做的情况:需求小,占用内存小,不影响计算效率
2.不能做的情况 : NN本身工作已经很多,可能持久化的过程中宕机。
备注:SNN永远无法取代NN的位置,他只是NN的一个热备
来个简单易懂图文解释
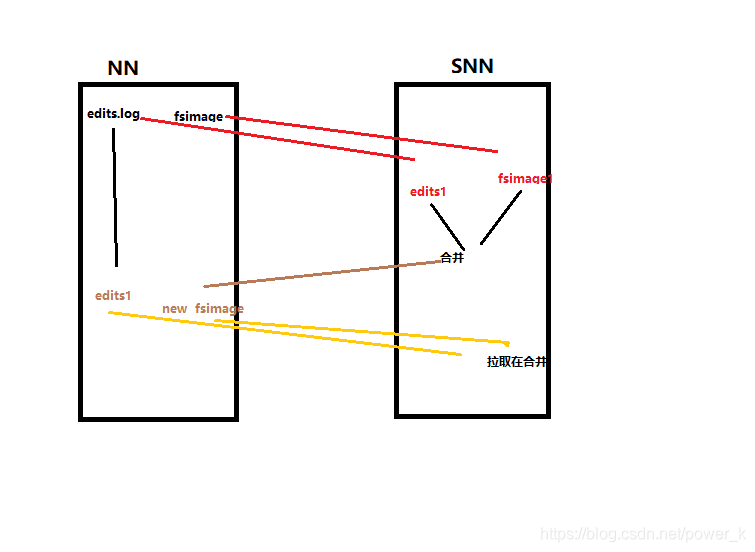
先解释一些
edits 存放系统在运行过程中国产生的操作信息。
fsimage 包含了整个HDFS文件系统的所有目录和文件的信息。对于文件来说包括了数据块描述信息、修改时间、访问时间等;对于目录来说包括修改时间、访问权限控制信息(目录所属用户,所在组)等。
主要是记录edits操作产生的日志信息。如果edits什么也没有做,它也会不断的产生信息。
第一步:将hdfs更新记录写入一个新的文件——edits.new。
第二步:将fsimage和editlog通过http协议发送至secondary namenode。
第三步:将fsimage与editlog合并,生成一个新的文件——fsimage.ckpt。这步之所以要在secondary namenode中进行,是因为比较耗时,如果在namenode中进行或导致整个系统卡顿。
第四步:将生成的fsimage.ckpt通过http协议发送至namenode。
第五步:重命名fsimage.ckpt为fsimage,edits.new为edits。
不断重复这样的一个1,、2、3、4、5步骤。
所以如果namenode宕机,其实secondary namenode还保存这一份不久前的fsimage,能挽回一些损失。
持久化触发条件
*超过3600s或者edits的大小超过64m*
那么另一种情况出现了,假如我们把edits和fsimage提交到的SNN的时候,NN的etids一致存储,满了怎么办?
没关系,哥哥再给你一张图
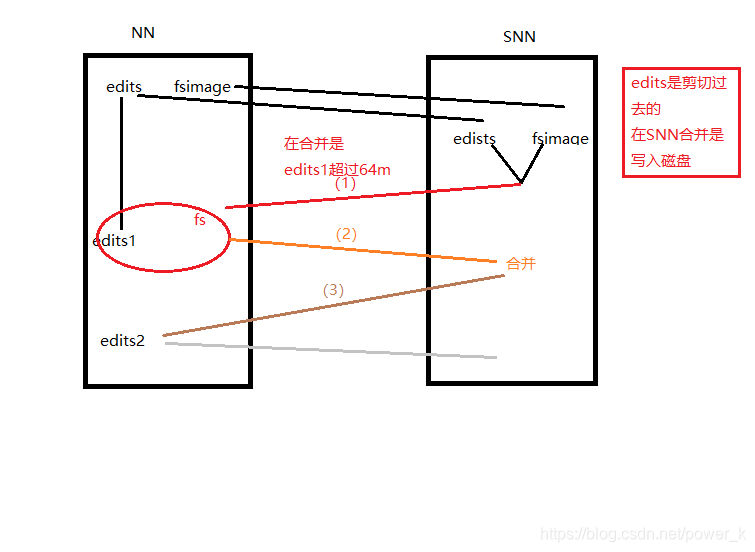
解决方案
1.个别现象
在另外启动一个edits,里面同时存在两个edits
2.常态
需要对集群调整,调整edits的大小
总结:持久化就是将NN的元数据写入到磁盘中进行存储,当NN挂了之后重启的时候回去磁盘读取相应的元数据,恢复集群的状态-----(内存断电丢失)
断电情况
持久化之前-----再次启动,读取系统日志
持久化之后-----读取磁盘中的数据,恢复状态
重复断电
NN和DN的通信机制----心跳机制(每隔3s,DN回向NN发送一次心跳,1分钟没有就DN认为挂掉)
安全模式
1.恢复系统状态
2.检查DN的信息
3.有问题的DN进行修复
1)在传输的过程中断电 —数据丢失
如果数据特别重要,那只能提前及进行预判,进行相应的调整
2)传输完成之后断电
当我的集群重新恢复之后,NN是不是会去读取元数据,对状态进行相应的恢复
3)在DN恢复之后,如果新的任务,根据情况,确定是否将新的文件上传
针对3)的这种情况我们看图说明一下
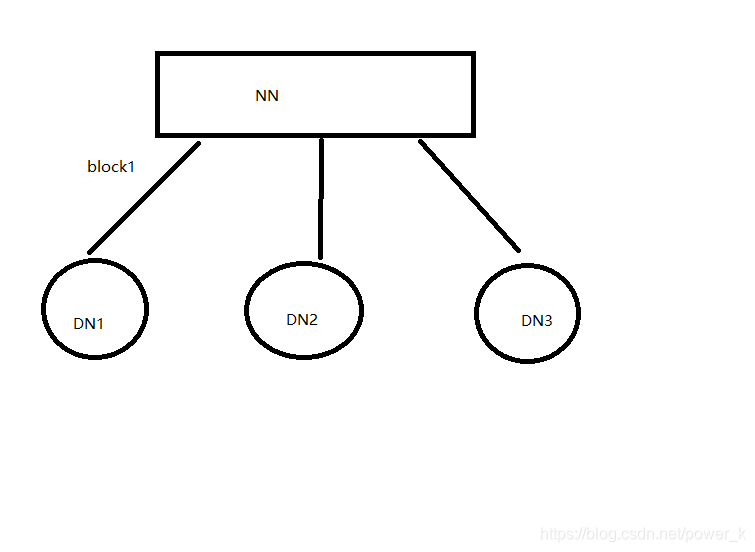
a.当上传block1的时DN3废了,当前任务不会再上传
b.当DN3恢复之后,相当于一个新的节点。
c.发布新的任务的时候才会写到恢复的DN3上
d.当计算DN3上的挂掉之前的数据时,会去1,2上找。
欢迎大家评论与指导

















 352
352

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









