




 本文探讨了MongoDB的auto-sharding机制及其问题,提出了一种新的负载均衡策略,该策略结合查询热度和文档关联度进行数据迁移,以解决数据块“热负载”不均衡的问题。在MongoDB中,块拆分策略通常只考虑数据量,但忽略了查询频率。通过监控和计算每个文档对象的访问热度,结合关联度,可以在数据迁移时更好地平衡集群负载。
本文探讨了MongoDB的auto-sharding机制及其问题,提出了一种新的负载均衡策略,该策略结合查询热度和文档关联度进行数据迁移,以解决数据块“热负载”不均衡的问题。在MongoDB中,块拆分策略通常只考虑数据量,但忽略了查询频率。通过监控和计算每个文档对象的访问热度,结合关联度,可以在数据迁移时更好地平衡集群负载。
基于查询热度和关联度的负载均衡
MongoDB auto-sharding机制
auto-sharding机制
MongoDB Sharding 是在 Collection 即集合层面来分布存储数据的。
Sharding依据 shard key 来将一个集合的数据进行分布存储。为了将一个集合的数据进行分片,首先需要选择一个 shard key。一个 shard key 可以是存在于一个集合中每个文档的索引字段。
MongoDB 将这个 shard key 的值切分成多个数据块,然后将这些数据块均匀分布到后端的 shard 上。
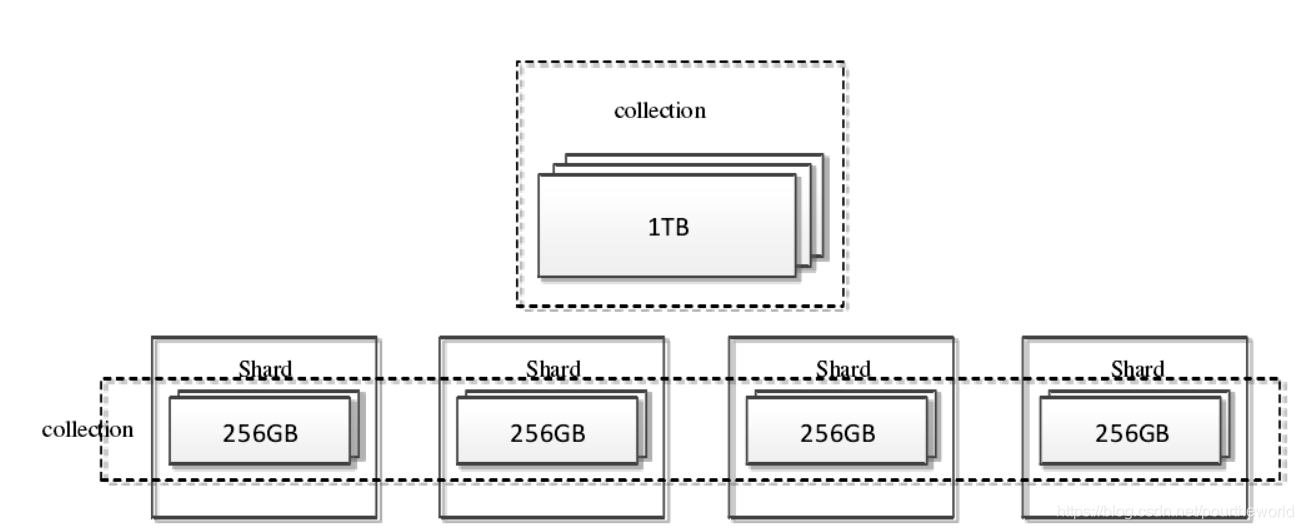 MongoDB 将文档分组为块(Chunk),每个块由给定片键特定范围内的
MongoDB 将文档分组为块(Chunk),每个块由给定片键特定范围内的文档组成,一个数据块只存在于一个数据分片上。
新分片的集合起初只有一个数据块,所有的文档都将存储在此块上。所以,随着数据的增长,块的大小随之增长,MongoDB会自动将其分为两个块。
Mongos 会记录每个数据块中插入的数据量,一旦数据量达到某个阈值(一般为 200M),就会被检查是否需要进行块拆分。当检查到此块需要进行块拆分时,Mongos 就会在 Config Server 上更新该数据块的基本信息。
当 Mongos 发现某一数据块的实际数据量(ChunkSize)已经超过最大块范围MaxChunkSize,MongoDB分片服务器需要拆分的某一数据块时,首先读取该数据块所包含数据条数(ChunkCount ),并计算平均每条数据大小( agvRecSize )即:
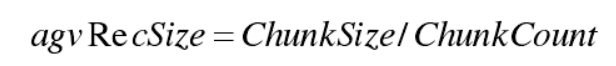
其次预估块拆分之后数据块包含数据条数( FchunkCount),即:
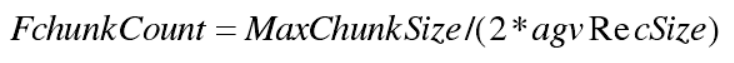
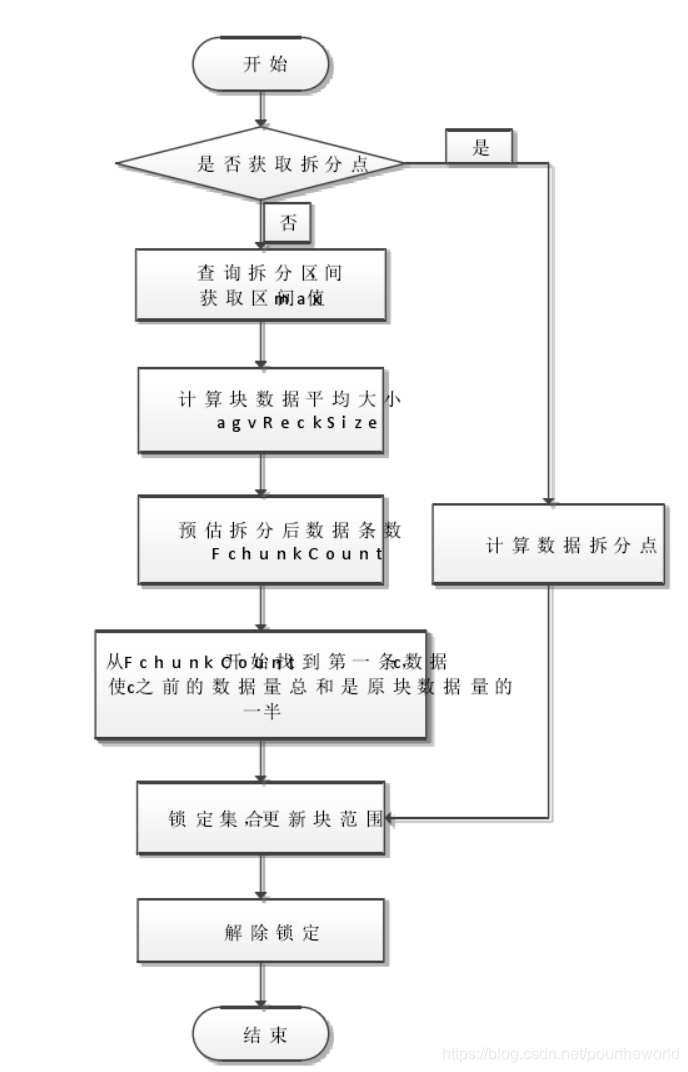
通过索引找出该数据块区间中 FchunkCount 的位置,从此位置开始,将第一条数据使此条数据之前的数量总和为该拆分数据块数据总量 ChunkSize的一半作为拆分点,以下是块拆分流程图:
auto-sharding的问题
在 Auto-Sharding 机制的块拆分策略中,Mongos 服务器定时扫描分片服务器中各数据块所包含的文档数量,当数据块过大时,就会触发块拆分策略。该策略通过产生一个新的数据块并将原数据块中的文档进行平均分配的方式,使数据块之间的负载差异达到最小化。
如上文所述,块拆分策略是采取平均分配的方式,这种策略是存在一定问题的。块的拆分仅仅考虑了当前块上所包含的文档数据量的负载,并没有考虑文档数据的访问热度问题。当前策略便会产生在数据块所在的数据分片服务器上,数据块之间数据量负载是均衡的,但是各数据块之间的“热负载”是不均衡的,各数据块对集群负载的影响也是有差异的。
基于查询热度和关联度的负载均衡
MongoDB对数 据 的 操 作 都 是 以 块 为 单 位,每 次 MongoDB在进行增读改删(CRUD)操作前都是向配置服务器发送请求以获取将要操作的目标块的信息,记录下访问每个块的时间间隔,用访问时间间隔去衡量该数据块的活跃程度,访问时间间隔越小表示该块工作量越大,就是一个活跃数据块.因此,当开始对数据进行负载均衡时,在原本只考虑数据块量负载的基础上,再将平均访问时间间隔作为一个因素考虑进去,可以一定程度上解决上述所提到的问题。
在单机INM移植到MongoDB的过程中,我们用MongoDB的一个文档去存储INM的一个具体的对象。
那么我们需要将INM对数据的CRUD操作细化到文档,而不是MongoDB的块。
方案
举个例子:MongoDB一共有3个数据分片(即三台主机),每个数据分片有多个数据块chunk。
一个数据块中有1000个文档,每个文档代表了一个INM的对象。
每次根据增读改删的语句,更新块中每个文档(INM的对象)的访问热度,并最后汇总成当前块的总访问热度。
当一个数据片的数据块之间的总访问热度的差到了一定阈值,热度高的数据块会将数据迁移到热度低的数据块。
当多个数据片的数据块个数的差到了一定阈值,数据块数量高的数据片会将数据块迁移到数据量低的数据块。
定义
上面提到了每个文档(INM的对象)的访问热度,我们通过在每个数据块中维护一张 文档:热度 (INM对象:热度)的表,来统计一段时间内该块中每个对象的访问热度。
首先,我们定义每个操作对于文档对象来说其访问热度的影响因子为 query>=update>create>delete。
其原因是query和update操作代表着近期访问过该对象,之后依旧可能会频繁访问。
而create的操作往往是一次性的,一次创建完实例和模式之后,不会在短时间内再次访问。
delete的操作是将当前文档(INM对象)删除一部分属性关系或者整个删除,因此其热度影响最低。
将其简单的量化为 H=1.0 Hquery=0.6 Hcreate=0.3 Hdelete=0.1。(具体的影响因子参数需要实验验证)
query
举个例子,以下语句查询武汉大学这个实例的模式信息,那么在文档:热度 (INM对象:热度)的表中,我们将武汉大学这个实例的热度加上查询的热度影响因子:
query $x 武汉大学 construct $x[];
文档document( INM object) 热度(H)
武汉大学 +0.6(Hquery)
再举个例子,我们查询所有模式为大学的文档对象,那么需要匹配所有模式为大学的文档对象,将所有查到的大学文档对象均加上热度。
query 大学 $x construct $x;
文档document( INM object) 热度(H)
武汉大学 +0.6(Hquery)
清华大学 +0.6(Hquery)
北京大学 +0.6(Hquery)
... ...
另一种情况是我们查询一个对象以及其某个关系对应的对象,如以下例子中,我们查询所有大学以及大学对应的校长。
这里衍生出一个问题:校长的各个对象在查询时是否需要加上查询热度?
我们的处理是,在一对关系中,如果目标类查询所需信息可以通过源类的对象的文档找到,我们只给源对象加上查询热度。
还是以下的例子,我们通过武汉大学这个对象,在文档中查找到对应的校长,无需再跳转到其校长对应的文档中查询,因此我们依旧将武汉大学这个文档对象的热度加上查询的热度影响因子。
query 大学 x / / 校 长 : x//校长: x//校长:y construct 大学: x / 校 长 : x/校长: x/校长:y;
文档document( INM object) 热度(H)
武汉大学 +0.6(Hquery)
武汉大学校长XXX +0.0(Hquery)
以上所述是否需要跨文档查询,具体查询到哪些文档的操作,我们会在MongoDB的负载均衡模块上加入一个分析器,定期分析每个查询对热度的影响,并行地修改当前块每个文档对象的热度情况。
insert等其他操作
前文提到,insert、create的操作往往是一次性的,一次创建完实例和模式之后,不会在短时间内再次访问。
比如以下语句,我们需要插入一个基础医学院的文档对象,它和武汉大学这个文档对象有依托单位的关系。由于关系有对应的逆关系,我们需要同时在武汉大学这个文档对象中更新这个逆关系。因此相当于这次insert的操作影响了两个文档对象,需要同时在表中加上insert查询热度因子。

文档document( INM object) 热度(H)
基础医学院(武汉大学) +0.3(Hcreate)
武汉大学 +0.3(Hcreate)
数据迁移时机
前文提到,我们给每一个数据块chunk对维护了一张文档:热度 (INM对象:热度)的表,定期实时地记录了每一个块的热度分布情况(每个文档对象的热度)。将所有文档对象的热度相加,就可以得到一个数据片内每个块的热度。
我们在每一个数据片内,维护一张数据块热度表:
数据块( chunk) 热度(H)
chunk1 +100
chunk2 +90
chunk3 +50
chunk4 +60
chunk5 +70
... ...
我们定期地检测一个数据片内的数据块热度,其中热度最高的块热度为Chunk_Max,热度最低的块热度为Chunk_Min。
当Chunk_Max-Chunk_Min>=Chunk_Threshold时,热度最高的块会选择一些文档对象迁移到热度最低的块,直到其热度差小于Chunk_Threshold为止。
其中Chunk_Threshold具体的值需要实验的验证,我们首先搞清楚发生迁移时,热度最高的块需要将哪些文档对象迁移。
我们从文档对象热度的高低以及建模时的关联度两个方面结合起来考虑这个问题。
从文档对象热度的高低选择需要迁移的文档
假定我们需要从chunk1(热度100)迁移文档对象到chunk2(热度50)。
以下是chunk1的热度表:
文档document( INM object) 热度(H)
document1 +40
document2 +30
document3 +20
document4 +10
document5 +5
document6 +3
... ...
我们的方案是通过排序将块内热度最低的文档迁移依次迁移到目标数据块中,直到两个数据块之间的差小于Chunk_Threshold。
这样的考虑的原因是热度高的文档对象可能正在被频繁地访问,如果移动热度高的文档会导致用户在访问时丢失数据会造成较大的延迟。而热度低的文档则不被经常访问,因此我们选择移动热度低的文档对象。
根据建模时的关联度选择需要迁移的文档
由于我们在MongoDB上搭建了INM,因此多了一步建模的工作,这也导致了在创建文档对象的时候,各个文档对象之间存在关系。
如同下图,大学与其部门之间存在从属关系,那么我们在创建文档对象的时候也会有这层关系。
在考虑负载均衡的时候,我们需要优先考虑两个文档之间是否存在关系,如果存在关系,那么在下次查询访问的时候,我们要尽量保持这两个文档对象在同一个数据块之中。
因此在一个数据块迁移文档对象到另一个数据块时,在我们用到迁移文档热度最低的迁移方案之前,首先需要考虑一个块内待迁移文档对象和原文档对象之间是否有关系约束,如果存在,那么即使待迁移文档热度再低,我们也优先考虑迁移别的文档。
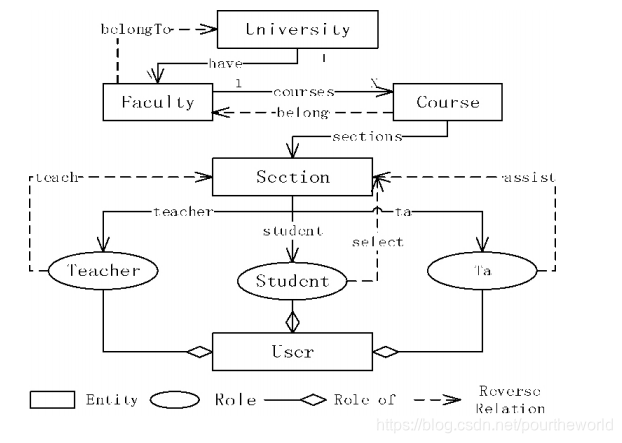
举个例子,我们根据上图建模,并创建文档对象。其中武汉大学与基础医学院有一层从属关系。根据前文选择移动热度低的文档对象的方案,我们理应迁移基础医学院这个文档对象。但是由于有一层与武汉大学文档对象的从属关系,如果将其移动,会导致下次查询时,需要跨块查询文档,这是不可接受的。因此我们跳过迁移基础医学院,转而迁移热度稍高的document6对象文档。
文档document( INM object) 热度(H)
基础医学院(武汉大学) +1
武汉大学 +40
document3 +30
document4 +20
document5 +10
document6 +5
... ...
上述提到的文档对象之间的关联度判断,我们也交给分析器去处理。分析器通过建模时几个模式之间的关系,在下次创建文档对象时会维护一张对象之间的关联度表:
源document 目标document
基础医学院(武汉大学) 武汉大学
导师 研究生
老板 员工
... ...
将文档对象关联度和文档对象热度结合
此外由于考虑到一个模式往往会与其他模式存在关系,那么文档对象往往会与其他文档有所关联,很少会有一个文档对象单独存在的情况。因此我们在原有的文档(对象):热度表之上,将文档对象根据关联度归类,将综合热度低的对象文档迁移到目标块。
在以下例子中,分为三对文档,其中医学院与武汉大学、导师1与研究生1、老板1与员工1分别都有关联,因此它们要么一起迁移,要么一起不迁移。之后我们根据关联文档对象的总热度,判断哪些文档需要迁移。
可以看到老板1+员工1的总热度最低,因此我们将这两个文档对象一起移动到目标块中。
文档document( INM object) 热度(H)
基础医学院(武汉大学) +1
武汉大学 +40
导师1 +30
研究生1 +20
老板1 +10
员工1 +5
... ...

















 171万+
171万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









