




 本文档详细介绍了数据库中索引的搭建,包括B树和散列桶索引的结构与实现。B树是一种适合磁盘存储的多叉树,通过增删过程展示了其工作原理。散列桶索引利用散列函数进行快速查找,通过散列桶管理器和散列桶的定义及函数来实现。此外,还讨论了Runtime层在数据库系统中的作用,它是连接文件系统和索引系统的桥梁,提供了插入、查找和删除等接口。最后,概述了单机数据库的启动流程和测试步骤。
本文档详细介绍了数据库中索引的搭建,包括B树和散列桶索引的结构与实现。B树是一种适合磁盘存储的多叉树,通过增删过程展示了其工作原理。散列桶索引利用散列函数进行快速查找,通过散列桶管理器和散列桶的定义及函数来实现。此外,还讨论了Runtime层在数据库系统中的作用,它是连接文件系统和索引系统的桥梁,提供了插入、查找和删除等接口。最后,概述了单机数据库的启动流程和测试步骤。
github链接(更新中)
https://github.com/pourtheworld/mydb
大纲(更新中)
(0)mydb的架构设想
本期任务
索引的搭建
索引的存在使得我们可以快速定位目标,消耗最少资源跳过不需要目标。
常用的有B树索引、bitmap位图索引、散列索引、地理索引。
B树和散列桶索引
B树
结构:
- 适合于磁盘的多叉树结构。
- 每个数据页作为一个节点。
- 每个节点有不定数量的元素。
- 每个元素包含左指针、数据键、与数据记录ID。
- 每个节点有一个右指针。
规则:
- 元素左指针指向的所有节点的数据键必须小于元素,并且大于等于前一个元素的数据键。
- 节点右指针指向的节点的所有元素的数据键必须大于该节点的最大元素。
- 节点中考前元素的数据键要小于等于靠后的。
我们通过一个增删的过程来简单描述一下B树结构:
(a) 以一个空节点开始,我们试图插入数据键为5的元素。
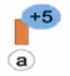
(b)成功插入后,试图插入13。
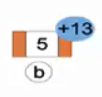
(c)由于13>5,直接插在5。
后面成功插入后,试图插入27。
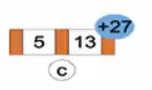
(d)同理成功插入27后,试图插入9。
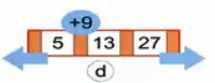
(e)我们规定一个节点最多有3个元素,当第4个元素试图插入时,重点的元素会被分裂到上一层;
可以看到13被分裂出来,我们继续试图插入9。

(f)此时9会优先插入到子节点中,然后试图插入7。
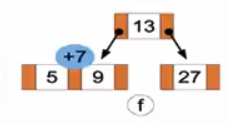
(g)成功插入7后,试图插入3。

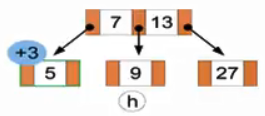
(h)老问题,节点个数来到4个,我们将中间的7分裂出来给到13的节点。继续试图插入3。
(i)成功插入3后,我们试图将9删去。
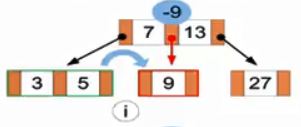
(j)由于9删除后,中间的节点为空,因此我们先将父节点的7移到9的左边,并将子节点的5置到父节点。再次试图删去9。

(k)成功删去9后,我们试图删去7。

(l)发现删去7中间节点为空,我们试图将5移下将3置上,但发现这样3所在节点会为空。因此我们将3、5、7置为一个子节点中。再试图删去7。
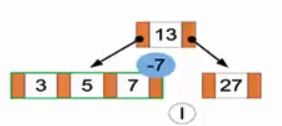
(m)成功删去7,我们试图删去5。
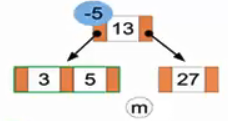
(n)成功删去5,试图删去3,发现3节点为空,因此将3、13、27置为一个子节点。再次尝试删去3。
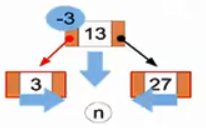
(o)继续尝试删除3,至此结束。
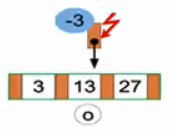
本数据库的散列桶索引
散列方式:
散列函数 f(数据记录的_id)=散列值。
散列值%散列桶个数=当前记录的散列桶编号 。
散列桶保存一个map<散列值,数据记录的RID>。
(注意_id与RID的区别,前者用于散列,后者用于文件定位。)
用户查找一个记录的流程:
- 输入query {_id:1}。
- agentEDU提取出BSONObj交给runtime的find接口。
- runtime交给索引manager的处理函数,通过_id经过散列函数得到散列值;
散列值%散列桶个数得到散列桶号,进入该桶。 - 在该桶的map中寻找到散列值对应的RID。
- 回到find接口,runtime再交给文件manager的查找函数,通过RID找到对应页的对应记录返回。
索引实现
我们定义ixmBucketManager类作为散列桶的管理器,保存了vector<ixmBucket*>。
以及ixmBucket类作为散列桶,每个散列桶保存了map<散列值,散列元素>。
我们定义一个结构体ixmEleHash作为散列元素,散列元素包含了数据记录以及记录ID。
散列桶管理器以及散列桶定义
#define IXM_KEY_FIELDNAME "_id"
#define IXM_HASH_MAP_SIZE 1000
//索引元素 包含记录数据+记录id
struct ixmEleHash
{
const char *data;
dmsRecordID recordID;
};
//首先有一个桶管理器,保存了1000个桶
//每个桶包含一个map。可以通过map的first 索引值,得到map的second 索引记录。
//索引值通过记录数据+记录长度通过索引函数得到。
class ixmBucketManager
{
private:
class ixmBucket
{
private:
std::multimap<unsigned int,ixmEleHash> _bucketMap;
ossSLatch _mutex;
public:
//给定索引值,寻找当前桶map中对应的索引记录。与给定索引记录比较是否存在。
int isIDExist(unsigned int hashNum,ixmEleHash &eleHash);
int createIndex ( unsigned int hashNum, ixmEleHash &eleHash ) ;
int findIndex ( unsigned int hashNum, ixmEleHash &eleHash ) ;
int removeIndex ( unsigned int hashNum, ixmEleHash &eleHash ) ;
};
//通过给定的record得到索引值。通过索引值%桶数得到对应桶。在对应桶的map中建立索引。
int _processData(BSONObj &record,dmsRecordID &recordID,
unsigned int &hashNum,ixmEleHash &eleHash,unsigned int &random);
private:
std::vector<ixmBucket*> _bucket;
public:
ixmBucketManager ()
{
}
~ixmBucketManager ()
{
ixmBucket *pIxmBucket = NULL ;
for ( int i = 0; i < IXM_HASH_MAP_SIZE; ++i )
{
pIxmBucket = _bucket[i] ;
if ( pIxmBucket )
delete pIxmBucket ;
}
}
int initialize () ;
int isIDExist ( BSONObj &record ) ;
int createIndex ( BSONObj &record, dmsRecordID &recordID ) ;
int findIndex ( BSONObj &record, dmsRecordID &recordID ) ;
int removeIndex ( BSONObj &record, dmsRecordID &recordID ) ;
};
散列函数
#undef get16bits
#if (defined(__GNUC__) && defined(__i386__)) || defined(__WATCOMC__) \
|| defined(_MSC_VER) || defined (__BORLANDC__) || defined (__TURBOC__)
#define get16bits(d) (*((const unsigned short *) (d)))
#endif
#if !defined (get16bits)
#define get16bits(d) ((((unsigned int)(((const unsigned char *)(d))[1])) << 8)\
+(unsigned int)(((const unsigned char *)(d))[0]) )
#endif
unsigned int ossHash ( const char *data, int len )
{
unsigned int hash = len, tmp ;
int rem ;
if ( len <= 0 || data == NULL ) return 0 ;
rem = len&3 ;
len >>= 2 ;
for (; len > 0 ; --len )
{
hash += get16bits (data) ;
tmp = (get16bits (data+2) << 11) ^ hash;
hash = (hash<<16)^tmp ;
data += 2*sizeof(unsigned short) ;
hash += hash>>11 ;
}
switch ( rem )
{
case 3:
hash += get16bits (data) ;
hash ^= hash<<16 ;
hash ^= ((char)data[sizeof (unsigned short)])<<18 ;
hash += hash>>11 ;
break ;
case 2:
hash += get16bits(data) ;
hash ^= hash <<11 ;
hash += hash >>17 ;
break ;
case 1:
hash += (char)*data ;
hash ^= hash<<10 ;
hash += hash>>1 ;
}
hash ^= hash<<3 ;
hash += hash>>5 ;
hash ^= hash<<4 ;
hash += hash>>17 ;
hash ^= hash<<25 ;
hash += hash>>6 ;
return hash ;
}
#undef get16bits
散列桶函数
首先散列桶的函数都需要通过散列桶Manager经过数据处理函数后再调用。
散列桶函数包括了ID是否存在、插入、查找、删去等函数。
散列桶管理器的数据记录处理函数:通过record,得到散列值、对应桶、散列元素。
//处理数据记录函数
//先检验记录是否有_id字段打头
//根据散列值获得桶号random
//把散列元素的data和id附上值
int ixmBucketManager::_processData ( BSONObj &record,
dmsRecordID &recordID,
unsigned int &hashNum,
ixmEleHash &eleHash,
unsigned int &random )
{
int rc = EDB_OK ;
//得到字段为i_id的BSON元素部分
BSONElement element = record.getField ( IXM_KEY_FIELDNAME ) ;
//如果没有_id字段,或者_id的类型不是int或者string 则出错
if ( element.eoo() ||
( element.type() != NumberInt && element.type() != String ) )
{
rc = EDB_INVALIDARG ;
PD_LOG ( PDERROR, "record must be with _id" ) ;
goto error ;
}
// 根据_id的值和长度,经过散列函数获得散列值
hashNum = ossHash ( element.value(), element.valuesize() ) ;
// 根据散列值通过取模得到桶号
random = hashNum % IXM_HASH_MAP_SIZE ;
//将散列元素赋值
eleHash.data = element.rawdata () ;
eleHash.recordID = recordID ;
done :
return rc ;
error :
goto done ;
}
散列桶的判断ID是否存在函数: 通过哈希值去对应桶里查找有无相同的散列元素。
//具体的记录检查函数:
//首先已经经过Manager的记录处理函数,得到了对应的散列值和散列元素
//去对应的桶里寻找相同散列值的迭代器范围
//在这个范围内判断是否与散列元素相同:先判断数据类型->数据长度->数据本身
//我们对该桶使用共享锁
int ixmBucketManager::ixmBucket::isIDExist ( unsigned int hashNum,
ixmEleHash &eleHash )
{
int rc = EDB_OK ;
BSONElement destEle ;
BSONElement sourEle ;
ixmEleHash existEle ;
std::pair<std::multimap<unsigned int, ixmEleHash>::iterator,
std::multimap<unsigned int, ixmEleHash>::iterator> ret ;
_mutex.get_shared () ;
ret = _bucketMap.equal_range ( hashNum ) ; //相同散列值的迭代器范围
sourEle = BSONElement ( eleHash.data ) ;
for ( std::multimap<unsigned int, ixmEleHash>::iterator it = ret.first ;
it != ret.second; ++it )
{
existEle = it->second ;
destEle = BSONElement ( existEle.data ) ;
if ( sourEle.type() == destEle.type() ) //先判断值的类型是否相同
{
if ( sourEle.valuesize() == destEle.valuesize() ) //再判断长度
{
if ( !memcmp ( sourEle.value(), destEle.value(), //最后判断内容
destEle.valuesize() ) )
{
rc = EDB_IXM_ID_EXIST ;
PD_LOG ( PDERROR, "record _id does exist" ) ;
goto error ;
}
}
}
}
done :
_mutex.release_shared () ;
return rc ;
error :
goto done ;
}
插入、删除、查找的逻辑与上一个函数类似,不再赘述。
Runtime
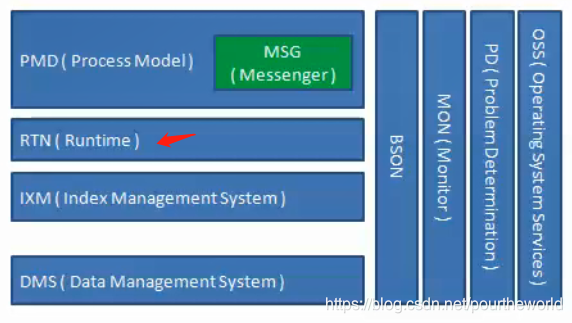
Runtime层的作用
之前我们已经实现了由DMS数据管理系统(文件)、索引管理系统组成的存储层部分;
也实现了传输层的Messenger(消息模型)和线程池的EDU(事件调度单元)。
我们在这个数据库系统中将事件调度单元分为listener以及agent,它们都有对应的处理函数,其中agentEDU负责与客户端进行通信。那么agentEDU的处理函数中需要对消息进行处理,我们可以引进runtime来调用文件系统和索引系统。
Runtime层的接口
可以看到runtime类的本身包含了文件和索引,作为上层调用底层的一个过渡。
class rtn
{
private:
dmsFile *_dmsFile;
ixmBucketManager *_ixmBucketMgr;
public:
rtn();
~rtn();
int rtnInitialize();
int rtnInsert(bson::BSONObj &record);
int rtnFind(bson::BSONObj &inRecord,bson::BSONObj &outRecord);
int rtnRemove(bson::BSONObj &record);
};
以rtnInsert为例看一下调用方法: 先查看索引中有无这个记录,没有再插入到文件中。
//实际上就是调用文件的insert
int rtn::rtnInsert(BSONObj &record)
{
int rc=EDB_OK;
dmsRecordID recordID;
BSONObj outRecord;
//检查索引是否已经存在该记录了。
rc=_ixmBucketMgr->isIDExist(record);
PD_RC_CHECK ( rc, PDERROR, "Failed to call isIDExist, rc = %d", rc ) ;
rc=_dmsFile->insert(record,outRecord,recordID);
if ( rc )
{
PD_LOG ( PDERROR, "Failed to call dms insert, rc = %d", rc ) ;
goto error ;
}
//插入完以后更新索引
rc=_ixmBucketMgr->createIndex(outRecord,recordID);
PD_RC_CHECK ( rc, PDERROR, "Failed to call ixmCreateIndex, rc = %d", rc ) ;
done :
return rc ;
error :
goto done ;
}
查找、删除的接口类似,不再赘述。
AgentEDU对runtime的调用
我们以Agent处理请求函数中的插入请求部分为例:
- 首先对应Insert的拆包函数,获得待插入数据记录。
- 检查记录第一个字段是否为_id。
- 交给rtnInsert进行具体插入。
try
{ //处理消息
if(OP_INSERT==opCode)
{
int recordNum=0; //插入记录数量
PD_LOG(PDDEBUG,"Insert request received");
//insert消息是由消息头+recordNum+BSONoBJ组成的
//通过这一步解封我们获得的pInsertorBuffer已经指向了BSONObj的首字母
rc=msgExtractInsert(pReceiveBuffer,recordNum,&pInsertorBuffer);
if(rc)
{
PD_LOG(PDERROR,"Failed to read insert packet");
probe=20;
rc=EDB_INVALIDARG;
goto error;
}
try//先检查对象本身有无错误,再检查第一个字段是不是id,最后交给rtnMgr来插入
{ //从buffer中读取BSON对象
BSONObj insertor(pInsertorBuffer);
PD_LOG ( PDEVENT,
"Insert: insertor: %s",
insertor.toString().c_str() ) ;
BSONObjIterator it(insertor); //BSON对象的一个迭代器
BSONElement ele=*it; //获取BSON对象的第一个元素
const char *tmp=ele.fieldName(); //获取第一个元素的字段名
rc=strcmp(tmp,gKeyFieldName); //比较是不是"id"
if ( rc )
{
PD_LOG ( PDERROR,
"First element in inserted record is not _id" ) ;
probe = 25 ;
rc = EDB_NO_ID ;
goto error ;
}
rc=rtnMgr->rtnInsert(insertor);
}
catch(const std::exception& e)
{
PD_LOG(PDERROR,"Failed to create insertor for insert: %s",e.what());
probe=30;
rc=EDB_INVALIDARG;
goto error;
}
}
单机数据库的测试
启动流程
-
pmdMain.cpp/main->pmdMain.cpp/pmdMasterThreadMain主线程启动:
两个主要流程:pmdMasterThreadMain.cpp/pmdResolveArguments(加载配置文件):rc=options.init(argc,argv); if(rc) { if(EDB_PMD_HELP_ONLY!=rc) PD_LOG(PDERROR,"Failed to init options,rc=%d",rc); goto error; } //将options里的内容传入内核 rc=pmdGetKRCB()->init(&options);过程中会初始化内核,让我们跳转进pmd.cpp/init:
int EDB_KRCB::init(pmdOptions *options) { setDBStatus(EDB_DB_NORMAL); setDataFilePath(options->getDBPath()); setLogFilePath(options->getLogPath()); //从配置文件中得到Log文件的地址,并copy给pd的日志文件地址 strncpy(_pdDiagLogPath,getLogFilePath(),sizeof(_pdDiagLogPath)); setSvcName(options->getServiceName()); setMaxPool(options->getMaxPool()); return _rtnMgr.rtnInitialize(); }过程中会将runtime初始化,让我们再跳转进rtn.cpp/rtnInitialize:
int rtn::rtnInitialize() { int rc=EDB_OK; _ixmBucketMgr=new(std::nothrow) ixmBucketManager(); if ( !_ixmBucketMgr ) { rc = EDB_OOM ; PD_LOG ( PDERROR, "Failed to new ixm bucketManager" ) ; goto error ; } _dmsFile=new(std::nothrow) dmsFile(_ixmBucketMgr); if ( !_dmsFile ) { rc = EDB_OOM ; PD_LOG ( PDERROR, "Failed to new dms file" ) ; goto error ; } rc=_ixmBucketMgr->initialize(); if ( rc ) { PD_LOG ( PDERROR, "Failed to call bucketMgr initialize, rc = %d", rc ) ; goto error ; } rc=_dmsFile->initialize(pmdGetKRCB()->getDataFilePath()); if ( rc ) { PD_LOG ( PDERROR, "Failed to call dms initialize, rc = %d", rc ) ; goto error ; } done : return rc ; error : goto done ; }在这一步,我们初始化了文件和索引系统,让我们回到最初pmdMasterThreadMain.cpp的另一个流程, pmdMasterThreadMain.cpp/eduMgr->startEDU(TcpListenerEDU)。
-
pmdEDUMgr.cpp/startEDU监听线程启动。当有客户端连接,由于是数据库刚启动,空闲队列中没有空闲agentEDU,因此我们转入pmdEDUMgr.cpp/_createNewEDU。
//如果为空,或者该EDU类型不是agent(idle队列里只能是agent) if(true==_idleQueue.empty()||!isPoolable(type)) { _mutex.release(); rc=_createNewEDU(type,arg,eduid); if(EDB_OK==rc) goto done; goto error; } -
pmdEDUMgr.cpp/_createNewEDU中,我们创建新的thread传入agent处理函数并且detach它。转入
pmdEDU.cpp/pmdEDUEntryPoint。try {//创建thread,将CB和其它参数传进去 boost::thread agentThread(pmdEDUEntryPoint,type,cb,arg); agentThread.detach(); } -
pmdEDU.cpp/pmdEDUEntryPoint中,检查事件类型,如果为恢复,那么根据EDU类型赋予处理函数,转入pmdEDU.cpp/getEntryFuncByType。
pmdEntryPoint entryFunc=getEntryFuncByType(type); -
pmdEDU.cpp/getEntryFuncByType,得到pmdAgentEntryPoint,进入pmdAgent.cpp/ pmdAgentEntryPoint。
pmdEntryPoint rt=NULL; //静态,第一次加载这个函数时生成entry入口函数对应数组 static const _eduEntryInfo entry[]={ ON_EDUTYPE_TO_ENTRY1(EDU_TYPE_AGENT,false,pmdAgentEntryPoint,"Agent"), ON_EDUTYPE_TO_ENTRY1(EDU_TYPE_TCPLISTENER,true,pmdTcpListenerEntryPoint,"TCPListener"), ON_EDUTYPE_TO_ENTRY1(EDU_TYPE_MAXIMUM,false,NULL,"Unknown") }; static const unsigned int number=sizeof(entry)/sizeof(_eduEntryInfo); unsigned int index=0; for(;index<number;++index) { //entry数组中寻找对应于type的入口函数 if(entry[index].type==type) { //获取到了该入口 rt=entry[index].entryFunc; goto done; } } done: return rt; -
pmdAgent.cpp/ pmdAgentEntryPoint,等待客户端发来消息,进入pmdAgent.cpp/ pmdProcessAgentRequest进行消息处理。
//正式对数据包进行处理 rc = pmdProcessAgentRequest ( pReceiveBuffer, packetLength, &pResultBuffer, &resultBufferSize, &disconnect, cb ) ; -
pmdAgent.cpp/ pmdProcessAgentRequest,根据消息类型调用对应的runtime底层接口函数。详细请看runtime例子部分。
实际演示
- 打开服务器(左),客户端(右),客户端连接。

- 客户端输入insert {_id:1,hello:“world”},服务器响应插入成功。
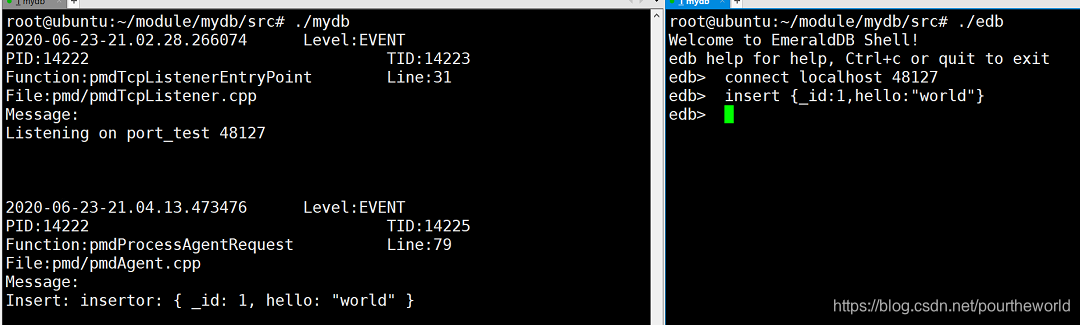
- 客户端输入insert {_id:2,hello:“c++”},服务器响应插入成功。

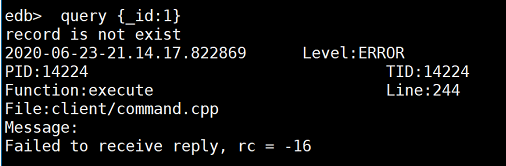
- 客户端输入query {_id:1},服务器返回给客户端整个记录信息。

- 客户端输入delete {_id:1},服务器响应删除命令。

- 客户端此时再查找这条记录,会显示不存在。

















 2375
2375

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









