




 本文通过启动Tomcat容器,详细解析Docker的镜像、容器和仓库三大组件及其作用。从dockerbuild制作镜像,dockerpush推送到仓库,再到dockerrun启动容器,层层深入,帮助读者理解Docker的工作机制和架构。同时,介绍了Docker的C/S架构,强调了Docker守护进程的重要角色。
本文通过启动Tomcat容器,详细解析Docker的镜像、容器和仓库三大组件及其作用。从dockerbuild制作镜像,dockerpush推送到仓库,再到dockerrun启动容器,层层深入,帮助读者理解Docker的工作机制和架构。同时,介绍了Docker的C/S架构,强调了Docker守护进程的重要角色。
本文将从启动一个Tomcat容器说起,逐步剖析Docker的整体架构,并详细介绍Docker的三大组件镜像容器和仓库的作用,以及在架构中扮演的角色!
1. 从最简单的例子说起
前面章节中分享了 Docker Hello World 和 Docker通过Apache显示网页 的例子。
1.1 启动Tomcat容器
这里我们用一个tomcat的例子再回顾一下。
要启动一个tomcat容器,我们只需一条命令即可!
docker run -d -p 8080:8080 tomcat:alpine
等上一会,我们打开浏览器,输入:http://localhost:8080/,于是看了非常熟悉的画面:
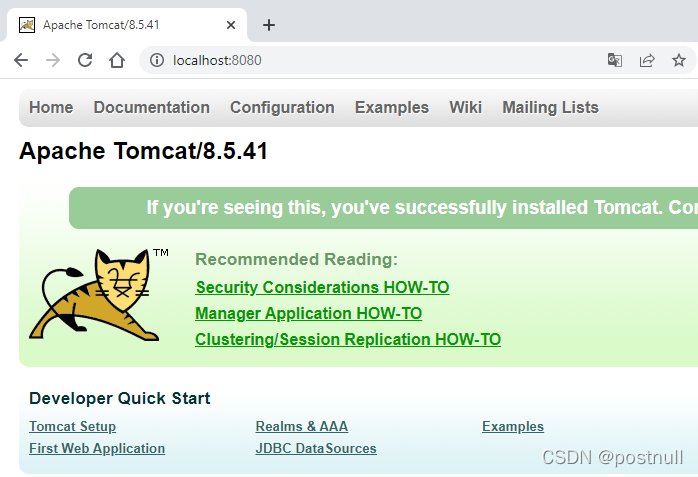 这表示我们的容器启动成功,并且可以正常访问!
这表示我们的容器启动成功,并且可以正常访问!
1.2 观察容器启动日志
一个命令,就安装好了系统并部署启动了Tomcat,实在是简单快速得惊人。那么这背后又发生了多少不为人知的事呢?
像破案一样,首先要勘察现场,那么这个命令打印出的日志,就是第一份线索。
我们先看看docker run运行后打印的日志。
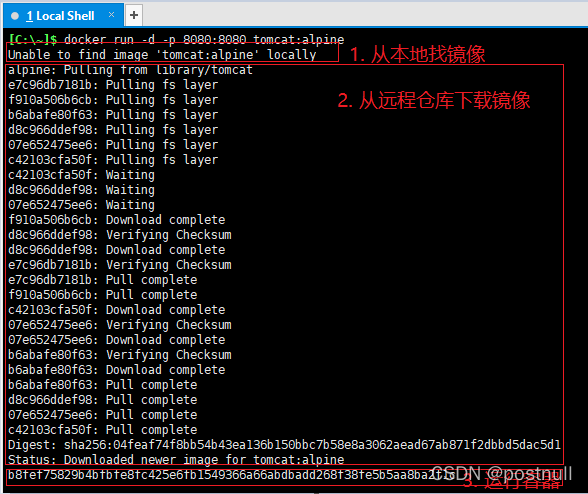 我们可以看到大概分三步走:
我们可以看到大概分三步走:
- 首先Docker尝试去本地查找tomcat
镜像,结果没找到(因为是第一次下载,本地肯定没有) - 然后Docker去
远程仓库拉取tomcat镜像,找到了,于是开始下载 - 下载完成后,根据tomcat镜像启动容器,并打印出
容器ID
我们把这个容器删除,然后再次docker run启动试试:

可以看到,只打印出了新启动的容器ID!因为之前镜像已经下载到了本地,所有跳过了拉镜像的环节。
注意要先停止旧的容器,否则会端口冲突!
docker stop b8fef7(容器ID不需要输完整,只需要前几位,保证是唯一的就行!和Git的commitId类似)
2. 剖析Docker架构
通过前面启动Tomcat容器的过程,我们可以看到Docker三大组件的身影:
- 镜像(image)
- 容器(container)
- 仓库(repository)
让我们来看看Docker的架构图
 请结合下面的章节仔细观察这个架构图,这是我们理解Docker运行机制的关键!
请结合下面的章节仔细观察这个架构图,这是我们理解Docker运行机制的关键!
2.1 Docker镜像
我们可以从0开始说。
很久很久以前,没有什么仓库,也没有什么镜像,什么也没有,只有一个安装了docker应用的主机。
制作镜像(docker build)
有人在host上通过docker build命令制作了第一个镜像
本文中为了简化,我们暂且不去用关心Dockerfile具体的内容,也不用关心它的具体构建过程。后面的文章会深入分析!
docker build -t tomcat:alpine .
于是,在这个host上就有了一个名词为tomcat,标签为alpine的镜像。
这就是上面架构图中的红色线条部分!
我们用docker images命令可以查看刚刚构建的镜像:
$ docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
tomcat alpine 8b8b1eb786b5 2 years ago 106MB
2.2 Docker仓库
为什么要有仓库
这个镜像现在还在主机上,只能自己使用,要想分享给别人也用怎么办?拿个U盘过来拷或者QQ文件传输?当然也可以!不过太麻烦。
最好是找个地方存起来,让有需要的人直接去那里下载就行了。
存储镜像的地方,就叫Docker镜像仓库!
作为程序员,我们见过太多太多的仓库
- git仓库:存储我们代码的地方
- maven仓库:存储我们jar包的地方
Docker官方默认的仓库,就是DockerHub!
听名字就知道,和GitHub异曲同工,只不过一个存的是代码,一个存的是镜像!
推送镜像(docker push)
要把前面本地构建好的镜像,推送到仓库去,使用命令:
docker push tomcat:alpine
当然,前提是要先登录仓库
这就是架构图中的绿色线条部分!
拉取镜像(docker pull)
上面路人甲已经把镜像推送到仓库去了,接下来路人乙也想拿来主义直接用,于是需要拉取镜像:
docker pull tomcat:alpine
这样,就把镜像从仓库拉取到了路人乙的主机上去了。
这就是架构图中的蓝色线条部分!
也不一定要显式地通过pull命令拉,前面的例子也说过docker run时本地没有时也会去隐式的拉取!
拉完后,路人乙也可以在本地看到下载好的镜像了:
$ docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
tomcat alpine 8b8b1eb786b5 2 years ago 106MB
2.3 Docker容器
前两小节中,镜像也构建了,存储镜像的仓库也有了。那么接下来,该来看看镜像的作用了。
启动容器(docker run)
别人制作的镜像,我们拿来直接用,用镜像创建容器
docker run -d -p 8080:8080 tomcat:alpine
容器和镜像的关系
说到镜像和容器的关系,我想起了两个例子来打比方!不一定完全准确,希望可以帮助大家理解!
a. Docker类比面向对象(OOP)
在OOP中,类是创建对象的模板,对象是类的实例!
同样的在Docker中,镜像是创建容器的模板,容器是创建对象的实例!
细想一下,Docker和OOP还真有点像失散多年的兄弟!
| OOP | Docker |
|---|---|
| 类 | 镜像 |
| 对象 | 容器 |
| 设置字段的值 | 安装的包 |
| 执行方法 | Dockerfile中声明的CMD |
| 用类作为模板创建对象 | 用镜像作为模板创建容器 |
| 一个类可以创建多个对象 | 一个镜像可以创建多个容器 |
| 继承类(extends) | 基于镜像(FROM) |
b. Docker容器类比虚拟机
必须首先强调一点的是,docker容器不是虚拟机。
以后的文章会单独研究这一点。
不过为了理解镜像和容器的关系,我们可以简单类比,只看类似的部分:
- 把Docker镜像类比成VirtualBox的虚拟机镜像文件
- 把Docker容器类比成VirtualBox的虚拟机
| VirtualBox | Docker |
|---|---|
| VM镜像文件 | Docker镜像 |
| VirtualBox加载镜像文件 | Docker加载镜像 |
| 用VM镜像文件创建虚拟机 | 用Docker镜像创建容器 |
| 虚拟机可以启动、退出、删除 | 容器可以启动、退出、删除 |
| 在虚拟机中部署应用 | 在容器中部署应用 |
| 可以端口映射 | -p 端口映射 |
| 和主机共享文件夹 | -v 数据卷 |
3. 再次Docker架构图
前面主要围绕架构图分析了Docker的三大组件:
- Docker镜像
- Docker仓库
- Docker容器
相比大家已经对总体有很更清晰的认识。
下面让我们再次聚焦Docker的架构图,看看遗漏的部分。
客户端和服务端
Docker使用的是C/S架构模式,也就是说分为Client客户端和Server服务端。
- 上面架构图的
左边部分就是客户端,通常执行在它上面执行docker的各种命令 - 上面架构图的
中间部分就是服务端,特别注意它有一个守护进程(Docker daemon),来接收来自客户端的请求 - 上面架构图的Client通过调用API发送请求给守护进程
- 上面架构图的中守护进程会接收来自Client的请求,对镜像、仓库、容器等进行各种操作!
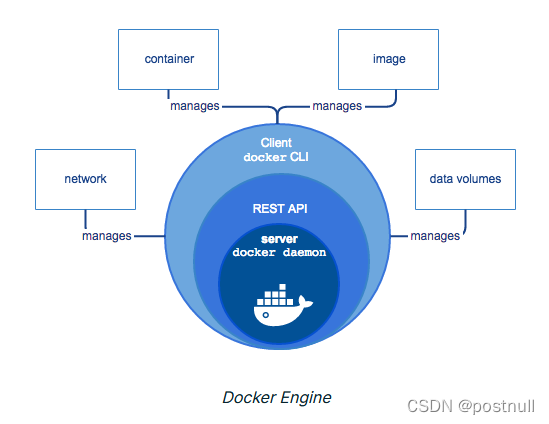
可以看到守护进程就是Docker的CPU 中央处理器!
查看守护进程
下面的dockerd就是Docker daemon守护进程!
# ps -ef | grep dockerd
root 6092 1 18 06:06 ? 00:44:36 /usr/bin/dockerd --graph=/var/lib/docker
查看客户端和服务端
大部分时候,我们的服务端也安装了客户端,当然也可以只安装Client。
查看客户端和服务端的版本
# docker version
Client:
Version: 18.09.9
API version: 1.39
Go version: go1.11.13
Git commit: 039a7df9ba
Built: Wed Sep 4 16:51:21 2019
OS/Arch: linux/amd64
Experimental: false
Server: Docker Engine - Community
Engine:
Version: 18.09.9
API version: 1.39 (minimum version 1.12)
Go version: go1.11.13
Git commit: 039a7df
Built: Wed Sep 4 16:22:32 2019
OS/Arch: linux/amd64
Experimental: false
如果服务端的守护进程停止了,我们执行客户端命令会报错!
同时,下面的报错,也再次证实了docker客户端使用的HTTP API与服务端交互!
docker images
error during connect: This error may indicate that the docker daemon is not running.: Get "http://%2F%2F.%2Fpipe%2Fdocker_engine/v1.24/images/json": open //./pipe/docker_engine: The system cannot find the file specified


















 1960
1960

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









