




 介绍TinyBERT模型的蒸馏方法,包括transformer层、注意力、隐藏层及预测层的蒸馏,以及特定任务上的数据增强策略。
介绍TinyBERT模型的蒸馏方法,包括transformer层、注意力、隐藏层及预测层的蒸馏,以及特定任务上的数据增强策略。
本文介绍下TinyBERT,华为在2020发布的一篇论文,主要内容是对模型进行蒸馏,蒸馏的方法值得学习

论文地址:
https://arxiv.org/abs/1909.10351
代码地址:
https://github.com/huawei-noah/Pretrained-Language-Model/tree/master/TinyBERT
目前已经有很多模型压缩的技术,如矩阵分解,量化、权重共享、剪枝、以及知识蒸馏,本文的重点在于知识蒸馏。
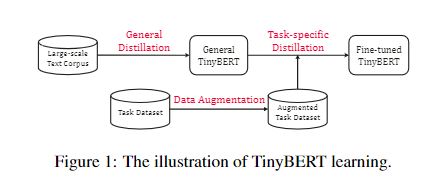
如上图所示,tinybert的蒸馏步骤可以概括为
General Distillation和Task-specific Distillation,也就是在大规模语料上对通识知识的蒸馏,这是在预训练阶段的蒸馏,和在指定任务数据上对特定任务的知识蒸馏,并且用通识知识的蒸馏模型对指定任务的蒸馏模型进行初始化,这是在微调阶段的蒸馏。同时,在特征任务上进行知识蒸馏时,会先对数据进行增强。
作者的实验结果是,4层的tinybert可以达到bertbase的96.8%的效果,但是参数量为bertbase的13.3%,推理时间为10.6%,并且比其他蒸馏的效果要好,同时,6层的tinybert和bertbase的表现近似。
1、transformer distillation
对transformer网络层数的蒸馏。假设学生模型有M层,老师模型有N层,自定义一个map函数n=g(m)n=g(m)n=g(m),实现学生层到老师层的map,表示学生模型的第m层从老师模型的第g(m)层学得信息。损失函数如下:
Lmodel=∑x∈X∑m=0M+1λmLlayer(fmS(x),fg(m)T(x))L_{model}=\sum_{x\in_{X}}\sum_{m=0}^{M+1}\lambda_mL_{layer}(f_m^S(x),f_{g(m)}^T(x))Lmodel=∑x∈X∑m=0M+1λmLlayer(fmS(x),fg(m)T(x))
LlayerL_{layer}Llayer表示的是某一个transformer layer或者是embedding layer的损失函数,fm(x)f_m(x)fm(x)表示第m层的目标函数值,λm\lambda_mλm表示第m层的重要性,为超参数。
transformer distillation包括attention distill、hidden distill、embedding distill、以及prediction distill,如下图所示:
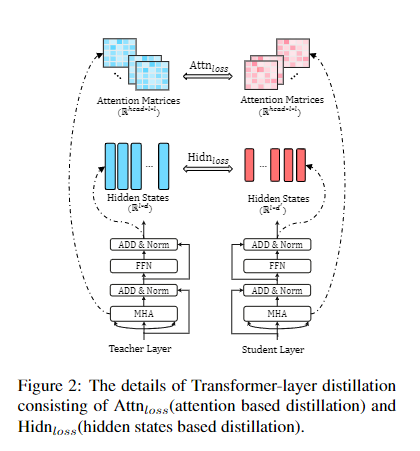
attention
其中,attention distill的目标函数为:
Lattn=1h∑i=1hMSE(AiS,AiT)L_{attn}=\frac{1}{h}\sum_{i=1}^hMSE(A_i^S,A_i^T)Lattn=h1∑i=1hMSE(AiS,AiT)
h表示注意力头的个数,AiA_iAi表示学生或老师第i个注意力头的attention matrix
同时,作者表明,之所以使用AiA_iAi,而不是softmax(Ai)softmax(A_i)softmax(Ai)作为拟合目标,是因为前者的收敛更快,效果更好。
hidden
其中,transformer输出蒸馏的损失函数为:
Lhidn=MSE(HSWh,HT)L_{hidn}=MSE(H^SW_h,H^T)Lhidn=MSE(HSWh,HT)
其中HS∈Rl×d∗H^S\in{R^{l \times d^*}}HS∈Rl×d∗,HT∈Rl×dH^T\in{R^{l \times d}}HT∈Rl×d
,d∗d^*d∗表示学生模型的向量维度。WhW_hWh是一个可学习矩阵,用来对学生模型进行线性变化,将其转化为与老师模型相同的维度。
embedding
embedding层输出蒸馏的损失函数为:
Lembd=MSE(ESWe,ET)L_{embd}=MSE(E^SW_e,E^T)Lembd=MSE(ESWe,ET)
可以看到基本与transformer输出的蒸馏形式是一样的。
prediction
损失函数为:
Lpred=CE(zTt,zSt)L_{pred}=CE(\frac{z^T}{t},\frac{z^S}{t})Lpred=CE(tzT,tzS)
z表示logits,t表示温度系数,作者实验发现,t=1时效果最好。这部分的损失函数就和distillbert设计的蒸馏损失比较像.
整体模型的损失函数如下:
Llayer={Lembdm=0Lhidn+Lattnm∈(0,M]Lpredm=M+1 L_{layer}=\begin{cases}
L_{embd} & m=0 \\
L_{hidn}+L_{attn} & m\in(0,M] \\
L_{pred} & m=M+1
\end{cases}Llayer=⎩⎪⎨⎪⎧LembdLhidn+LattnLpredm=0m∈(0,M]m=M+1
其中,m表示学生的层数
2、task-specific distillation
该部分先对数据集进行增强,然后进行蒸馏。作者对数据增强的解释为,学生模型在经过增强的数据集上进行训练,可以提高其效果,也就是说,相比于老师模型,学生模型在特定任务上的训练数据是经过增强的,以此来提升学生模型的效果,因此学生就有超过老师的可能。
数据增强
其伪代码如下:

作者结合bert和glove的词嵌入,在word-level上进行替换,以实现数据增强。作者的参数设置如下,pt=0.4p_t=0.4pt=0.4,Na=20N_a=20Na=20,K=15K=15K=15
论文并没有对task-specific distillation的蒸馏部分进行阐述,说明其与general distill的蒸馏方式应该是一样的,只是一个处于预训练阶段,一个处于微调阶段。
3、实验结果
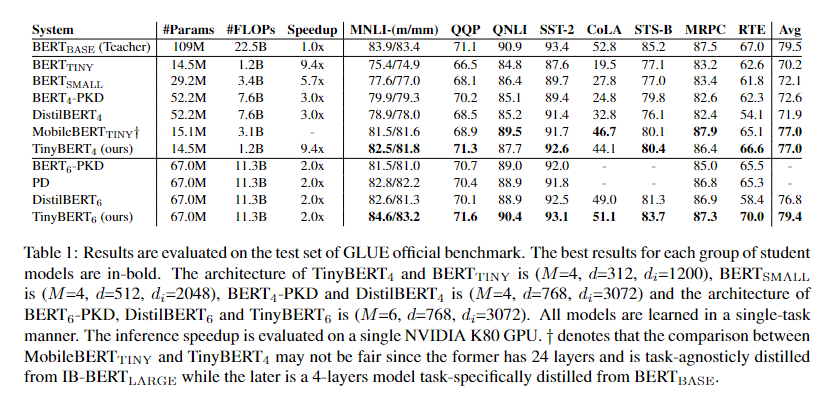
实验时,作者使用g(m)=3×mg(m)=3 \times mg(m)=3×m进行映射,也就是说4层的tinybert的每层都是从3层的bertbase中学得。
下面是作者对tinybert使用得学习策略和蒸馏方式做的消融实验:
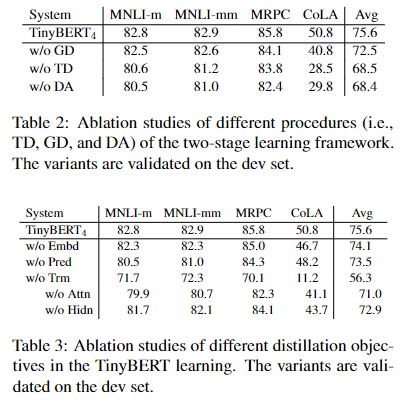
下面是作者针对学生层到老师层的映射做的消融实验:
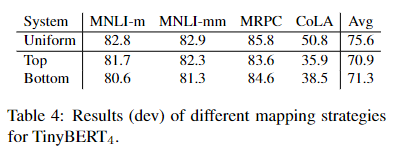
可以看到,使用均匀映射的效果是最好的,同时,作者也表明,对于一个下游任务,自适应的选择层数是一个具有挑战性的问题,也是未来的工作方向。
该论文通过蒸馏方式实现对模型的压缩,整体上的实现分为以下几步:
- 预训练阶段的蒸馏
- 数据增强
- 微调阶段的蒸馏
每个蒸馏,又会进行以下操作:
- embedding层的蒸馏
- hidden层的蒸馏
- attention的蒸馏
- 预测层的蒸馏
之所以做数据增强,是为了在对具体任务蒸馏时,扩充学生模型的训练集,提高学生模型的表现。

















 322
322

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









