




 本文介绍了Scrapy框架的基础用法,通过一个简单的爬虫项目爬取http://quotes.toscrape.com网站的名人名言。阐述了Scrapy的项目创建、爬取流程、数据提取、翻页爬取及结果保存。详细解释了如何使用Scrapy的items、middlewares、pipelines以及shell进行调试,最后展示了如何将数据保存为json、csv等格式,以及利用MongoDB存储数据。
本文介绍了Scrapy框架的基础用法,通过一个简单的爬虫项目爬取http://quotes.toscrape.com网站的名人名言。阐述了Scrapy的项目创建、爬取流程、数据提取、翻页爬取及结果保存。详细解释了如何使用Scrapy的items、middlewares、pipelines以及shell进行调试,最后展示了如何将数据保存为json、csv等格式,以及利用MongoDB存储数据。
Scrapy是一个非常强大的异步爬虫框架,它已经给我们写好了许许多多的组件,使用Scrapy我们只用关心爬虫的逻辑就好了。本文通过一个简单的项目了解一下Scrapy的爬取流程,对Scrapy的基本用法也有一个大体的了解。
一、目标站点分析
Scrapy提供了一个官方抓取网站:http://quotes.toscrape.com,主要列出了一些名人名言,相应的作者和标签信息。

下拉到底点击“Next” 会进行翻页,URL变为“http://quotes.toscrape.com/page/2/”,这是一个最简单的GET请求实例,通过改变链接的名称就可以进行翻页了,网页结构也非常简单,没有任何的反爬虫措施,所以就选用这一个站点作为Scrapy的入门实例。
二、流程框架
1.抓取第一页
请求第一页的URL并得到源代码,进行下一步的分析。
2.获取内容和下一页链接
分析源代码,提取首页内容,获取下一页链接等待进一步提取。
3.翻页爬取
请求下一页信息,分析内容并请求下一页链接。
4.保存爬取结果
将爬取结果保存为特定格式,如文本、数据库。
三、Scrapy实战
1.首先cd到项目目录下,输入“scrapy startproject quotetutorial”,即项目名为quotetutorial。

2.按照提示,首先“cd quotetutorial”,接着用genspider创建一个spider:“scrapy genspider quotes quotes.toscrape.com”,其中“quotes”为spider名称,“quotes quotes.toscrape.com”是要爬取的URL。

现在我们就完成了spider的创建,实际上就是为我们创建了一个“quotes.py”文件,文件内容如下:
# -*- coding: utf-8 -*-
import scrapy
class QuotesSpider(scrapy.Spider):
name = "quotes"
allowed_domains = ["quotes.toscrape.com"]
start_urls = ['http://quotes.toscrape.com/']
def parse(self, response):
pass
除此之外,我们可以看到还有以下文件:
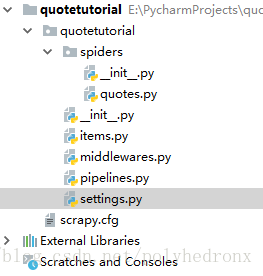
其中,“scrapy.cfg”为配置文件 ;“items.py”是用来保存数据的数据结构;“middlewares.py”是在爬取过程中定义的一些中间件,可以用来处理Request,Response以及Exceptions等操作,也可以用来修改Request, Response等相关的配置;“pipelines.py”即项目管道,可以用来输出一些items;另外,最重要的就是“settings.py”,里面定义了许多配置信息。最主要的运行代码是在“quotes.py”里面。
首先在命令行运行一下“scrapy crawl quotes”,回车之后控制台输出了一些调试信息。可以看出,它和普通的爬虫不太一样,Scrapy提供了很多额外的输出。
E:\PycharmProjects\quotetutorial>scrapy crawl quotes
2018-09-06 20:24:23 [scrapy.utils.log] INFO: Scrapy 1.3.3 started (bot: quotetutorial)
2018-09-06 20:24:23 [scrapy.utils.log] INFO: Overridden settings: {'BOT_NAME': 'quotetutorial', 'NEWSPIDER_MODULE': 'quotetutorial.spiders', 'ROBOTSTXT_OBEY': True,
'SPIDER_MODULES': ['quotetutorial.spiders']}
2018-09-06 20:24:24 [scrapy.middleware] INFO: Enabled extensions:
['scrapy.extensions.corestats.CoreStats',
'scrapy.extensions.telnet.TelnetConsole',
'scrapy.extensions.logstats.LogStats']
2018-09-06 20:24:25 [scrapy.middleware] INFO: Enabled downloader middlewares:
['scrapy.downloadermiddlewares.robotstxt.RobotsTxtMiddleware',
'scrapy.downloadermiddlewares.httpauth.HttpAuthMiddleware',
'scrapy.downloadermiddlewares.downloadtimeout.DownloadTimeoutMiddleware',
'scrapy.downloadermiddlewares.defaultheaders.DefaultHeadersMiddleware',
'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware',
'scrapy.downloadermiddlewares.retry.RetryMiddleware',
'scrapy.downloadermiddlewares.redirect.MetaRefreshMiddleware',
'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware',
'scrapy.downloadermiddlewares.redirect.RedirectMiddleware',
'scrapy.downloadermiddlewares.cookies.CookiesMiddleware',
'scrapy.downloadermiddlewares.stats.DownloaderStats']
2018-09-06 20:24:25 [scrapy.middleware] INFO: Enabled spider middlewares:
['scrapy.spidermiddlewares.httperror.HttpErrorMiddleware',
'scrapy.spidermiddlewares.offsite.OffsiteMiddleware',
'scrapy.spidermiddlewares.referer.RefererMiddleware',
'scrapy.spidermiddlewares.urllength.UrlLengthMiddleware',
'scrapy.spidermiddlewares.depth.DepthMiddleware']
2018-09-06 20:24:26 [scrapy.middleware] INFO: Enabled item pipelines:
[]
2018-09-06 20:24:26 [scrapy.core.engine] INFO: Spider opened
2018-09-06 20:24:26 [scrapy.extensions.logstats] INFO: Crawled 0 pages (at 0 pages/min), scraped 0 items (at 0 items/m 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 285
285

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









