






 本文提出一种结合自由形态区域与检测区域的方法解决视觉问答(VQA)问题。通过利用ResNet152和Faster R-CNN分别提取图像特征,采用多模态乘法特征嵌入机制实现注意力机制的有效整合,以克服各自局限性。
本文提出一种结合自由形态区域与检测区域的方法解决视觉问答(VQA)问题。通过利用ResNet152和Faster R-CNN分别提取图像特征,采用多模态乘法特征嵌入机制实现注意力机制的有效整合,以克服各自局限性。
Co-Attending Free-Form Regions and Detections with Multi-Modal Multiplicative Feature Embedding for Visual Question Answering
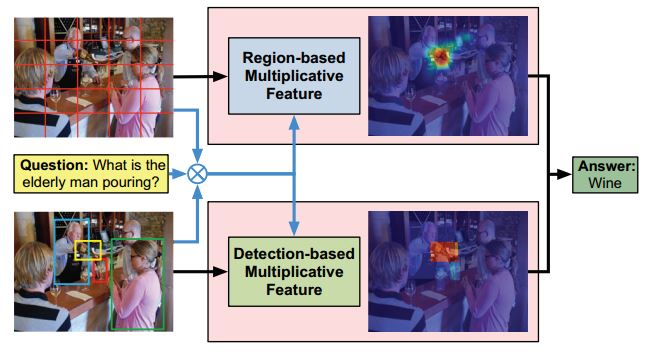
现在做VQA的,很多方法都是基于question在图像中寻找显著性区域,来获得相应answer。
attention主要分为两支free-form region based 和 detection-based 。
两支单独做,各有弊端,比如free-form的图像的切分往往会把object分成很多细粒度块,而如cat的身体与狗的身体块,可
能很相似,这样会误导模型产生错误的答案,而dection based mechanism往往事先检测出实体区域,对于许多涉及前景的
问题很有利,但比如“How is the weather today?”这样的问题确比较难,因为或许不存在sky这样的bounding box。
因此本文将两种方式结合起来,彼此互补。
方法思想
网络结构
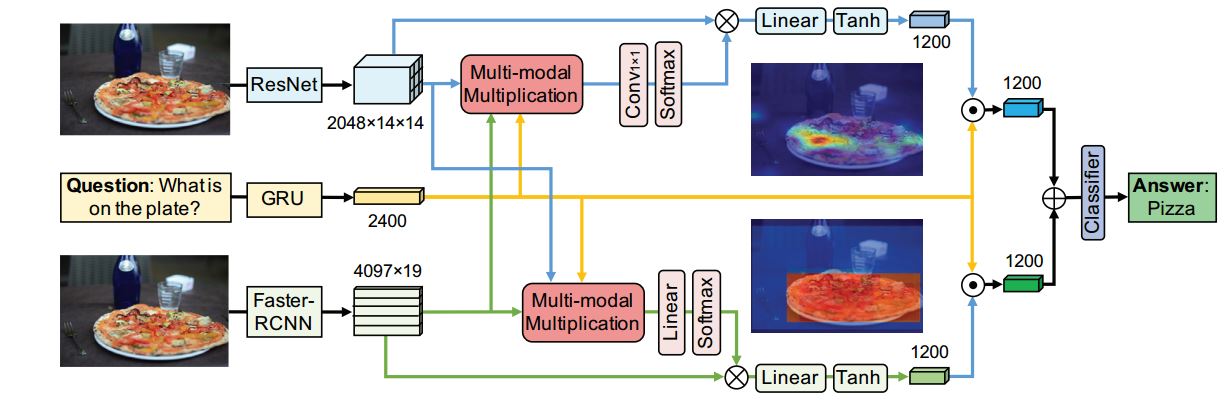
free based是利用Resnet152提取14142048特征,可视为划分196个图像区域。
detection based是利用fasterrcnn提取19个bounding box特征19*4097(其中4096是图像特征,1是
bounding box的检测得分。)
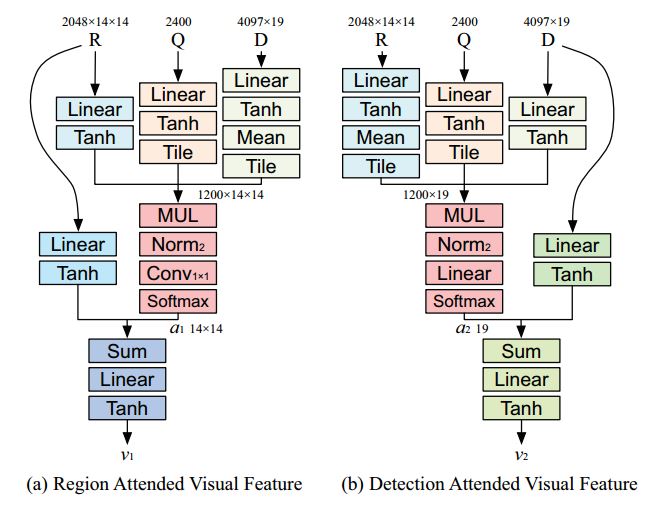
attention细节
数据集
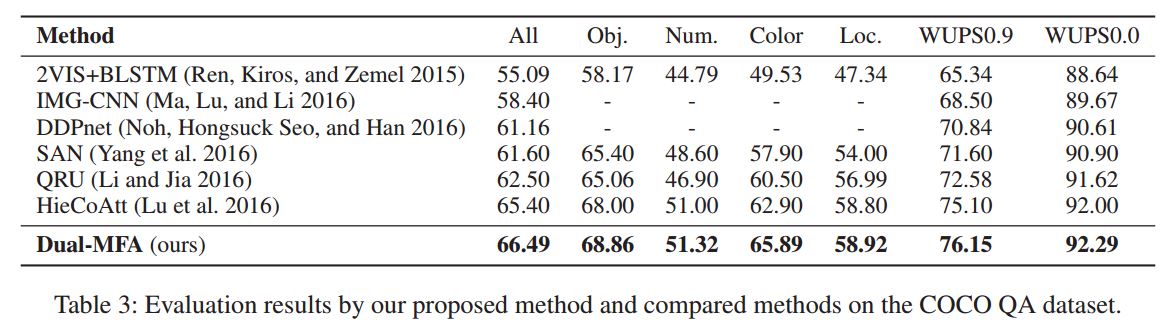
VQA, COCO-QA
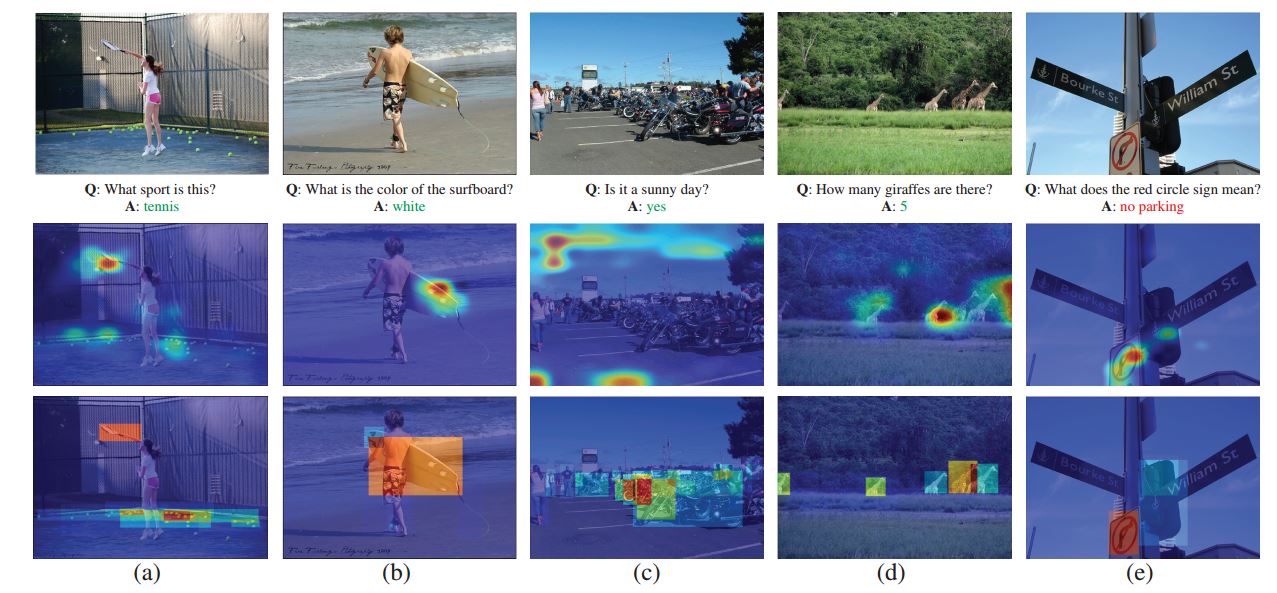
结果
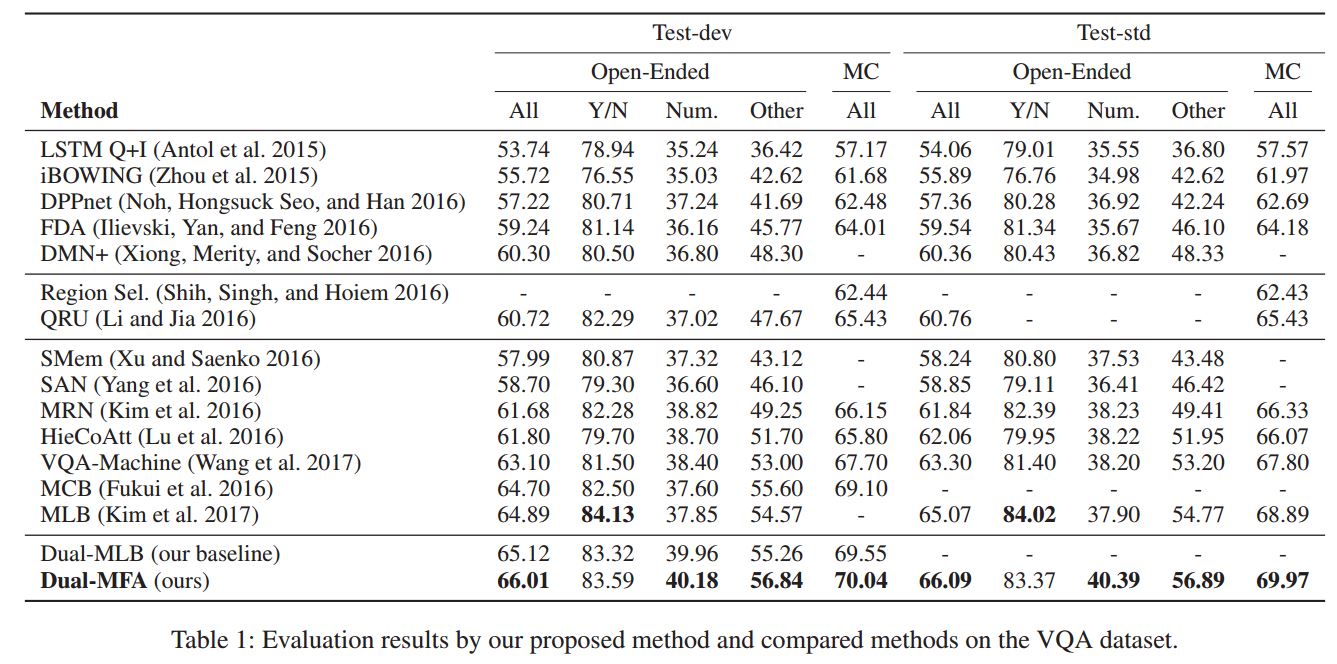
github源码:dual-mfa-vqa


















 433
433

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











