




1. 简介
布隆过滤器可以用来判断一个元素是否在一个集合中。它的优势是只需要占用很小的内存空间以及有着高效的查询效率
布隆过滤器是什么,一定要用吗?
- 黑客流量攻击:故意访问不存在的数据,导致程序不断访问DB数据库的数据
- 黑客安全阻击:当黑客访问不存在的缓存时迅速返回避免缓存及DB挂掉
思考:
- 50亿个电话号码,现有10万个电话号码,如何判断这10万个是否已经存在在50亿个之中?(可能方案:数据库,set, hyperloglog)
- 新闻客户端看新闻时,它会不断推荐新的内容,每次推荐时都要去重,那么如何实现推送去重?
- 反垃圾邮件,从数十亿个垃圾邮件列表中判断某邮箱是否垃圾邮箱(同理,垃圾短信);
- 网页爬虫对URL的去重,避免爬取相同的URL地址;
- 缓存击穿,将已存在的缓存放到布隆中,当黑客访问不存在的缓存时迅速返回避免缓存及DB挂掉。
布隆过滤器(Bloom Filter)就是专门来解决这种问题的,它起到去重的同时,在空间上还能节省90%以上,只是存在一定的误判概率。
概念:
布隆过滤器(英语:Bloom Filter)是1970年由布隆提出的。它实际上是一个很长的二进制向量和一系
列随机映射函数。布隆过滤器可以用于检索一个元素是否在一个集合中。它的优点是空间效率和查询时
间都远远超过一般的算法,缺点是有一定的误识别率和删除困难。
优点:
相比于其它的数据结构,布隆过滤器在空间和时间方面都有巨大的优势。布隆过滤器存储空间和插入/
查询时间都是常数({\displaystyle O(k)} O(k))。另外,散列函数相互之间没有关系,方便由硬件并
行实现。布隆过滤器不需要存储元素本身,在某些对保密要求非常严格的场合有优势。
查询效率高,占用空间少
缺点:
但是布隆过滤器的缺点和优点一样明显。误算率是其中之一。随着存入的元素数量增加,误算率随之增
加。但是如果元素数量太少,则使用散列表足矣
总而言之布隆过滤器是一种概率性数据结构,判断某样东西一定不存在或者可能存在,进而减少没有必要的数据库请求
2. 布隆过滤器实现原理
布隆过滤器本质是一个位数组,位数组就是数组的每个元素都只占用 1 bit 。每个元素只能是 0 或者 1。这样申请一个 10000 个元素的位数组只占用 10000 / 8 = 1250 B 的空间。布隆过滤器除了一个位数组,还有 K 个哈希函数。当一个元素加入布隆过滤器中的时候,会进行如下操作:
- 使用 K 个哈希函数对元素值进行 K 次计算,得到 K 个哈希值。
- 根据得到的哈希值,在位数组中把对应下标的值置为 1。
如下图所示,我们一个key进来,通过多个hash函数来个三列映射,比如第一个hash函数映射的内存结果是1,4,8。那么下次这个key进来的时候,如果有1,4,8符合我这个key的一个哈希结果,那么就能证明我的这个key是存在于内存中
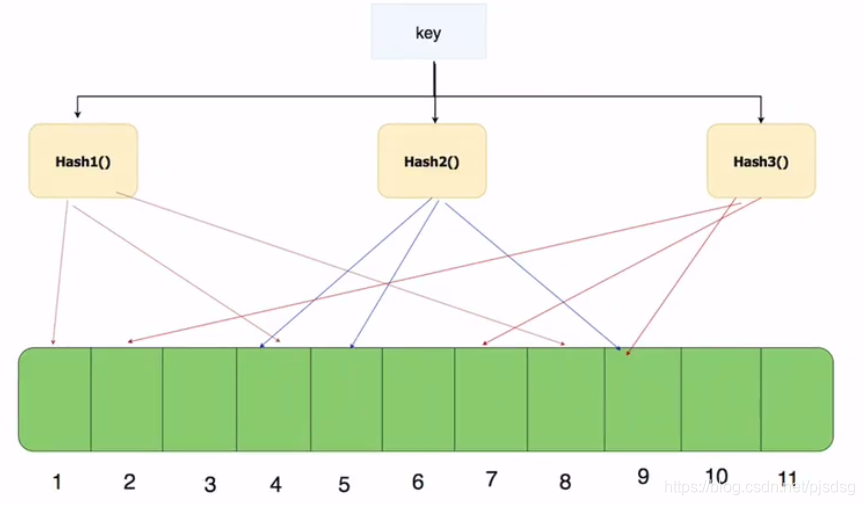
数组的容量即使再大,也是有限的。那么随着元素的增加,插入的元素就会越多,位数组中被置为1的位置因此也越多,这就会造成一种情况:当一个不在布隆过滤器中的元素,经过同样规则的哈希计算之后,得到的值在位数组中查询,有可能这些位置因为之前其它元素的操作先被置为1了
所以,有可能一个不存在布隆过滤器中的会被误判成在布隆过滤器中。这就是布隆过滤器的一个缺陷。但是,如果布隆过滤器判断某个元素不在布隆过滤器中,那么这个值就一定不在布隆过滤器中。总结就是:
- 布隆过滤器说某个元素在,可能会被误判
- 布隆过滤器说某个元素不在,那么一定不在
3. 布隆过滤器怎么实现
实现布隆过滤器有两种方式,第一种是使用谷歌的布隆过滤器,另一种是redis的布隆过滤器
3.1 Google布隆过滤器与Redis布隆过滤器对比
Google布隆过滤器的缺点:
- 基于JVM内存的一种布隆过滤器
- 重启即失效
- 本地内存无法用在分布式场景
- 不支持大数据量存储
Redis布隆过滤器:
- 可扩展性Bloom过滤器:一旦Bloom过滤器达到容量,就会在其上创建一个新的过滤器
- 不存在重启即失效或者定时任务维护的成本:基于Google实现的布隆过滤器需要启动之后初始化布隆过滤器
- 缺点:需要网络IO,性能比Google布隆过滤器低
两种过滤器的选择:优先基于数据量进行考虑
在这里我们讲解Redis的布隆过滤器。
4. Redis布隆过滤器安装和基本使用
4.1 使用Docker安装
docker pull redislabs/rebloom # 拉取镜像
docker run -d -p 6379:6379 redislabs/rebloom # 运行容器
docker exec -it 8fb741940d1b redis-cli # 连接容器中的 redis 服务
4.2 Redis布隆过滤器命令
bf.add:添加元素到布隆过滤器中,只能添加一个元素,如果想要添加多个使用bf.madd命令
bf.exists:判断某个元素是否在过滤器中,只能判断一个元素,如果想要判断多个使用bf.mexists命令
127.0.0.1:6379> bf.add urls www.taobao.com
(integer) 1
127.0.0.1:6379> bf.exists urls www.taobao.com
(integer) 1
127.0.0.1:6379> bf.madd urls www.baidu.com www.tianmao.com
1) (integer) 1
2) (integer) 1
127.0.0.1:6379> bf.mexists urls www.baidu.com www.tianmao.com
1) (integer) 1
2) (integer) 1
在 redis 中有两个值决定布隆过滤器的准确率:
- error_rate:允许布隆过滤器的错误率,这个值越低过滤器的位数组的大小越大,占用空间也就越大。
- initial_size:布隆过滤器可以储存的元素个数,当实际存储的元素个数超过这个值之后,过滤器的准确率会下降。
redis 中有一个命令可以来设置这两个值:
bf.reserve test 0.01 100
- 第一个值是过滤器的名字。
- 第二个值为 error_rate 的值。
- 第三个值为 initial_size 的值。
注意必须在add之前使用bf.reserve指令显式创建,如果对应的 key 已经存在,bf.reserve会报错。同时设置的错误率越低,需要的空间越大。如果不使用 bf.reserve,默认的error_rate是 0.01,默认的initial_size是 100。
5. Springboot结合Redis布隆拦截器
5.1 配置maven标题
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>3.0.0</version>
</dependency>
<dependency>
<groupId>com.redislabs</groupId>
<artifactId>jrebloom</artifactId>
<version>1.2.0</version>
</dependency>
5.2 添加配置
封装工具类
@Component
@Slf4j
public class RedisBloomUtil {
@Autowired
private Client bloomFilter;
/**
*
* @param key
* @param initCapacity 布隆过滤器可以储存的元素个数,当实际存储的元素个数超过这个值之后,过滤器的准确率会下降。
* @param errorRate 允许布隆过滤器的错误率,这个值越低过滤器的位数组的大小越大,占用空间也就越大
* @return
*/
public boolean bfCreate(String key, long initCapacity, double errorRate) {
try {
bloomFilter.createFilter(key, initCapacity, errorRate);
return true;
}catch(Exception e){
e.printStackTrace();
return false;
}
}
/**
* 添加元素到布隆过滤器中
* @param key
* @param value
* @return
*/
public boolean bfAdd(String key, String value) {
try {
return bloomFilter.add(key, value);
}catch(Exception e){
e.printStackTrace();
return false;
}
}
/**
* 判断某个元素是否在过滤器中
* @param key
* @param value
* @return
*/
public boolean bfExists(String key, String value) {
try {
return bloomFilter.exists(key, value);
}catch(Exception e){
e.printStackTrace();
return false;
}
}
/**
* 删除过滤器
* @param key
* @return
*/
public boolean delete(String key) {
try {
bloomFilter.delete(key);
return true;
}catch(Exception e){
e.printStackTrace();
return false;
}
}
}
在之前的博客中jedis使用的2.9.0版本,但是使用布隆过滤器时使用的是3.0.0版本,3.0.0版本和2.9.0版本的内部方法有些不一样,比如分布式锁的实现方式,需要注意。

















 2690
2690

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









