




 ESIM是专为自然语言推断而生的加强版LSTM,可用于文本推理和匹配。其优势在于精细的序列式推断结构,兼顾局部与全局推断。模型包含Input Encoding、Local Inference Modeling、Inference Composition、Prediction四部分,训练速度快,效果较好。
ESIM是专为自然语言推断而生的加强版LSTM,可用于文本推理和匹配。其优势在于精细的序列式推断结构,兼顾局部与全局推断。模型包含Input Encoding、Local Inference Modeling、Inference Composition、Prediction四部分,训练速度快,效果较好。
ESIM,简称 “Enhanced LSTM for Natural Language Inference“,一种专为自然语言推断而生的加强版 LSTM。ESIM模型主要是用来做文本推理的,给定一个前提premise pp 推导出假设hypothesis hh,其损失函数的目标是判断pp与hh是否有关联,即是否可以由pp推导出hh,因此,该模型也可以做文本匹配,只是损失函数的目标是两个序列是否是同义句。接下来我们就从模型的结构开始讲解其原理。
Unlike the previous top models that use very complicated network
architectures, we first demonstrate that carefully designing sequential inference
models based on chain LSTMs can outperform all previous models.
Based on this, we further show that by explicitly considering recursive
architectures in both local inference modeling and inference composition,
we achieve additional improvement.
ESIM 能比其他短文本分类算法牛逼主要在于两点:
- 精细的设计序列式的推断结构。
- 考虑局部推断和全局推断。
作者主要是用句子间的注意力机制(intra-sentence attention),来实现局部的推断,进一步实现全局的推断。
ESIM的论文中,作者提出了两种结构,如下图所示,左边是自然语言理解模型ESIM,右边是基于语法树结构的HIM,本文主要讲解ESIM的结构。ESIM一共包含四部分,Input Encoding、Local Inference Modeling、 Inference Composition、Prediction。
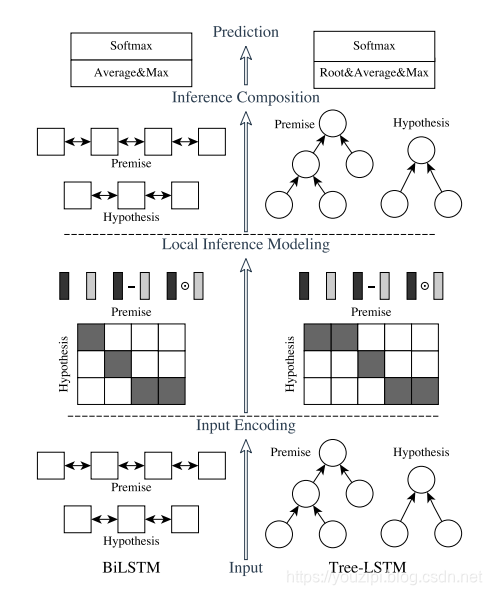
input encoding
输入一般可以采用预训练好的词向量或者添加embedding层,在我的代码中采用的是embedding层。接下来就是一个双向的LSTM,起作用主要在于对输入值做encoding,也可以理解为在做特征提取,最后把其隐藏状态的值保留下来,分别记为ai¯与bj¯b,其中i与j分别表示的是不同的时刻。就是输入两句话分别接 embeding + BiLSTM。这里为什么不用最近流行的 BiGRU,作者解释是实验效果不好。这里作者也额外提了一句,如果可以做句子的语法分析的话,那么也可以 使用 TreeLSTM(右边的him模型)。
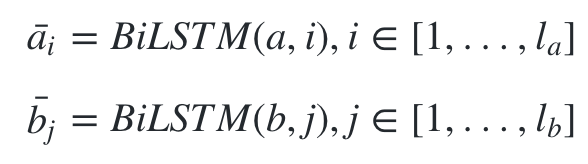
使用 BiLSTM 可以学习如何表示一句话中的 word 和它上下文的关系,可以理解成这是 在 word embedding 之后,在当前的语境下重新编码,得到新的 embeding 向量。
Local Inference Modeling
这一层的任务主要是把上一轮拿到的特征值做差异性计算。这里作者采用了attention机制,其中attention weight的计算方法如下:
![]()
然后根据attention weight计算出a与b的权重加权后的值,计算方法如下:
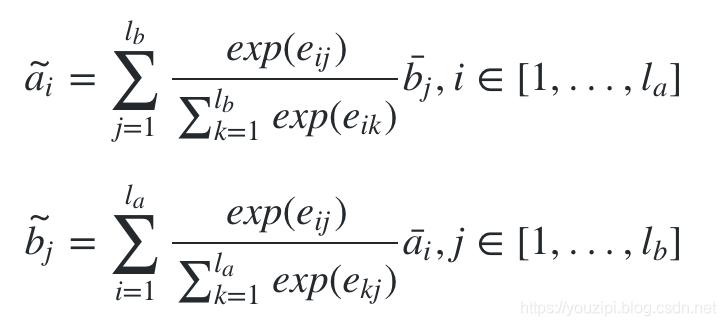
注意,这里计算ai~的时候,其计算方法是与bj¯做加权,而不是ai¯本身,bj~同理。
得到encoding值与加权encoding值之后,下一步是分别对这两个值做差异性计算,作者认为这样的操作有助于模型效果的提升,论文有有两种计算方法,分别是对位相减与对位相乘,最后把encoding两个状态的值与相减、相乘的值拼接起来。
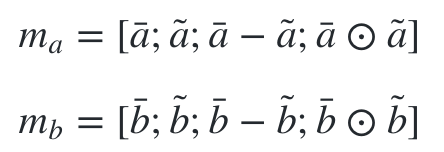
实现:
def _soft_attention_alignment(self, x1, x2):
"Align text representation with neural soft attention"
# x1: [b, s1, d]
# x2: [b, s2, d]
# att: [b, s1, s2]
att = tf.einsum("abd,acd->abc", x1, x2)
w_att_1 = tf.nn.softmax(att, dim=1)
w_att_2 = tf.nn.softmax(att, dim=2)
x2_att = tf.einsum("abd,abc->acd", x1, w_att_1)
x1_att = tf.einsum("abd,acb->acd", x2, w_att_2)
return x1_att, x2_att#### align
ali_seq_left, ali_seq_right = self._soft_attention_alignment(enc_seq_left, enc_seq_right)
#### compose
com_seq_left = tf.concat([enc_seq_left, ali_seq_left, enc_seq_left * ali_seq_left, enc_seq_left - ali_seq_left,], axis=-1)
com_seq_right = tf.concat([enc_seq_right,ali_seq_right, enc_seq_right * ali_seq_right, enc_seq_right - ali_seq_right,], axis=-1)或者
with tf.name_scope('Local_inference_Modeling'):
# 计算a_bar与b_bar每个词语之间的相似度
with tf.name_scope('word_similarity'):
attention_weights = tf.matmul(a_bar, tf.transpose(b_bar, [0, 2, 1]))
attentionsoft_a = tf.nn.softmax(attention_weights)
attentionsoft_b = tf.nn.softmax(tf.transpose(attention_weights))
attentionsoft_b = tf.transpose(attentionsoft_b)
a_hat = tf.matmul(attentionsoft_a, b_bar)
b_hat = tf.matmul(attentionsoft_b, a_bar)
# 计算m_a, m_b
with tf.name_scope("compute_m_a/m_b"):
a_diff = tf.subtract(a_bar, a_hat)
a_mul = tf.multiply(a_bar, a_hat)
b_diff = tf.subtract(b_bar, b_hat)
b_mul = tf.multiply(b_bar, b_hat)
# m_a = [a_bar, a_hat, a_bar - a_hat, a_bar 'dot' a_hat] (14)
# m_b = [b_bar, b_hat, b_bar - b_hat, b_bar 'dot' b_hat] (15)
self.m_a = tf.concat([a_bar, a_hat, a_diff, a_mul], axis=2)
self.m_b = tf.concat([b_bar, b_hat, b_diff, b_mul], axis=2)Inference Composition
在这一层中,把之前的值再一次送到了BiLSTM中,这里的BiLSTM的作用和之前的并不一样,这里主要是用于捕获局部推理信息ma和mb及其上下文,以便进行推理组合。
最后把BiLSTM得到的值进行池化操作,分别是最大池化与平均池化,并把池化之后的值再一次的拼接起来。
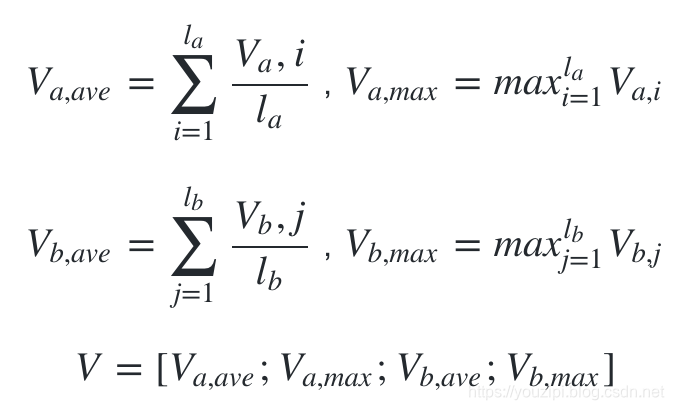
Prediction
最后把VV送入到全连接层,激活函数采用的是tanhtanh,得到的结果送到softmax层。
小结
ESIM与BiMPM在相似度匹配任务中都是使用较多的模型,但是ESIM训练速度快,效果也并没有逊色太多,如果加入了语法树,其最终效果也能进一步的提升。
from: -柚子皮-
ref: 原论文 [Enhanced LSTM for Natural Language Inference]
[文本匹配模型之ESIM]*

















 5858
5858




 到【灌水乐园】发言
到【灌水乐园】发言







