




http://blog.youkuaiyun.com/pipisorry/article/details/24143801
正则表达式简介
正则表达式是用于处理字符串的强大工具,拥有自己独特的语法以及一个独立的处理引擎,效率上可能不如str自带的方法,但功能十分强大。在提供了正则表达式的语言里,正则表达式的语法都是一样的,区别只在于不同的编程语言实现支持的语法数量不同;但不用担心,不被支持的语法通常是不常用的部分。
正则表达式匹配流程
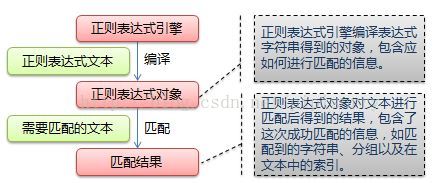
python正则表达式中使用原始字符串
Raw string notation (r"text") keeps regular expressions sane. Without it,every backslash ('\') in a regular expression would have to be prefixed withanother one to escape it.
Python中转义字符-反斜杠的困扰
与大多数编程语言相同,正则表达式里使用"\"作为转义字符,这就可能造成反斜杠困扰。假如你需要匹配文本中的字符"\",那么使用编程语言表示的正则表达式里将需要4个反斜杠"\\\\":前两个和后两个分别用于在编程语言里转义成反斜杠,转换成两个反斜杠后再在正则表达式里转义成一个反斜杠。
Python里的原生字符串很好地解决了这个问题,这个例子中的正则表达式可以使用r"\\"表示。同样,匹配一个数字的"\\d"可以写成r"\d"。有了原生字符串,你再也不用担心是不是漏写了反斜杠,写出来的表达式也更直观。
Note:建议正则表达式使用时都使用原生字符串r''。
关于字符编码
py2中pattern中的字符串要和string的编码一致,不然会找不到,这个经常出现。
正则表达式匹配模式
正则表达式提供了一些可用的匹配模式,比如忽略大小写、多行匹配等。
这与Pattern类的工厂方法re.compile(pattern[, flags])联系紧密。
(?aiLmsux)
(One or more letters from the set 'a', 'i', 'L', 'm', 's', 'u', 'x'.) The group matches the empty string; the letters set the corresponding flags: re.A (ASCII-only matching), re.I (ignore case), re.L (locale dependent), re.M (multi-line), re.S (dot matches all), re.U (Unicode matching), and re.X (verbose), for the entire regular expression. (The flags are described in Module Contents.) This is useful if you wish to include the flags as part of the regular expression, instead of passing a flag argument to the re.compile() function. Flags should be used first in the expression string.
A ASCII 使\w\W\b\B\d\D匹配ASCII字符
I IGNORECASE 忽略大小写
L LOCALE 使\w\W\b\B匹配本地字符集
M MULTILINE 多行模式,"^" 匹配每行开头,"$"匹配每行结尾
S DOTALL "." 匹配所有字符,包括"\n"
X VERBOSE 详细模式,忽略空白可以加入注释
U UNICODE 使\w\W\b\B\d\D匹配unicode字符集
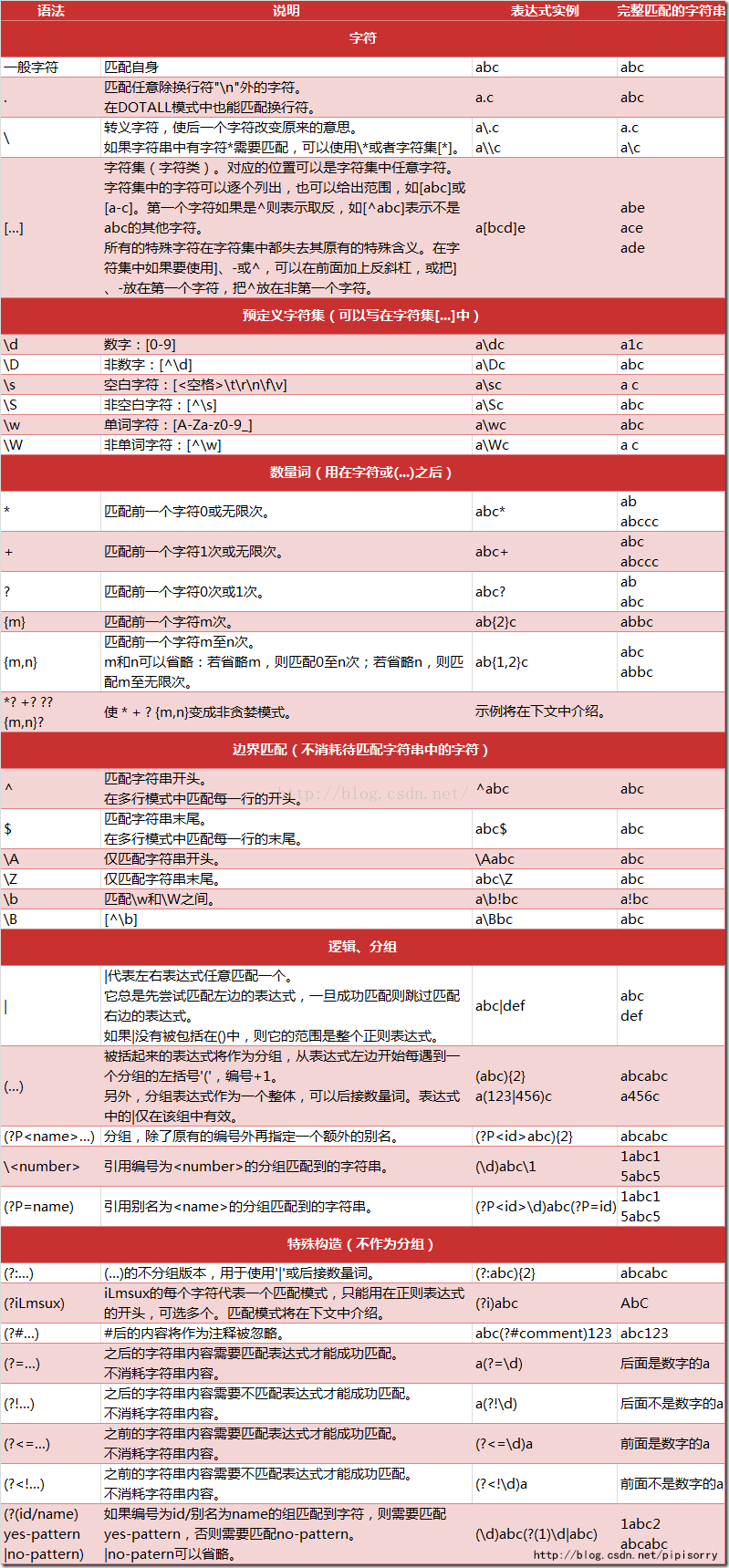
Python支持的正则表达式元字符和语法
基于Python2.4,不过一般通用,无论是c, java, python3, mysql, 还是linux, notepad++。
可参考[notepad++正则表达式使用][Java正则表达式小记][linux通配符和正则表达式][mysql语法、特殊符号及正则表达式的使用][正则表达式 - C语言]
python正则表达式中的其他特殊符号
| \cx | 匹配由x指明的控制字符。例如,\cM匹配一个Control-M或回车符。x的值必须为A-Z或a-z之一。否则,将c视为一个原义的「c」字符。 |
|---|---|
| \xn | 匹配n,其中n为十六进制转义值。十六进制转义值必须为确定的两个数字长。例如,「\x41」匹配「A」。「\x041」则等价于「\x04&1」。正則表达式中可以使用ASCII编码。. |
| \num | 向后引用(back-reference)一个子字符串(substring),该子字符串与正则表达式的第num个用括号围起来的子表达式(subexpression)匹配。其中num是从1开始的正整数,其上限可能是99。例如:「(.)\1」匹配两个连续的相同字符。 |
| \n | 标识一个八进制转义值或一个向后引用。如果\n之前至少n个获取的子表达式,则n为向后引用。否则,如果n为八进制数字(0-7),则n为一个八进制转义值。 |
| \nm | 标识一个八进制转义值或一个向后引用。如果\nm之前至少有nm个获得子表达式,则nm为向后引用。如果\nm之前至少有n个获取,则n为一个后跟文字m的向后引用。如果前面的条件都不满足,若n和m均为八进制数字(0-7),则\nm将匹配八进制转义值nm。 |
| \nml | 如果n为八进制数字(0-3),且m和l均为八进制数字(0-7),则匹配八进制转义值nml。 |
| \un | 匹配n,其中n是一个用四个十六进制数字表示的Unicode字符。例如,\u00A9匹配版权符号(©)。 |
正则表达式语法
基本规则
‘[‘ ‘]’ 字符集合设定符
由一对方括号括起来的字符,表明一个字符集合,能够匹配包含在其中的任意一个字符。比如 [abc123],表明字符’a’ ‘b’ ‘c’ ‘1’ ‘2’ ‘3’都符合它的要求。可以被匹配。
在方括号中,有一些特殊字符具有特殊的含义,它们被称为元字符(metacharacters):
- `-`(连字符):用于指定字符范围。例如,`[a-z]` 表示匹配任意小写字母。用[a-zA-Z]来指定所以英文字母的大小写,不可以把大小的顺序颠倒了。-应该是只有在a-z这种情况下才是特殊字符。
- `^`(脱字符):用于否定字符类。例如,`[^0-9]` 表示匹配任意非数字字符。[^a-zA-Z]表明不匹配所有英文字母。但是如果 ‘^’不在开头,则它就不再是表示取非,而表示其本身,如[a-z^A-Z]表明匹配所有的英文字母和字符’^’。
- `\`(反斜杠):用于转义特殊字符。例如,[\[\]] 表示匹配方括号字符。
另外匹配方括号字符本身,可以使用转义字符 `\` 进行转义,例如 \[ 或 \]。
除了这些特殊字符外,其他字符在方括号中都表示它们自身的字符。
Note: ^[a-zA-Z]是去匹配目标字符串中以中括号中的a—z或者A—Z开头的字符;[^a-zA-Z]是去匹配目标字符串中非a—z也非A—Z的字符。
‘|’ 或规则
A|B, A 和 B 可以是任意正则表达式,创建一个正则表达式,匹配 A 或者 B. 任意个正则表达式可以用 '|'连接。它也可以在组合(见下列)内使用。扫描目标字符串时, '|' 分隔开的正则样式从左到右进行匹配。当一个样式完全匹配时,这个分支就被接受。意思就是,一旦 A 匹配成功, B 就不再进行匹配,即便它能产生一个更好的匹配。或者说,'|' 操作符绝不贪婪。
将两个规则并列起来,以‘|’连接,表示只要满足其中之一就可以匹配。比如
[a-zA-Z]|[0-9] 表示满足数字或字母就可以匹配,这个规则等价于 [a-zA-Z0-9]
’|’要注意两点:
第一, 它在’[‘ ‘]’之中不再表示或,而表示他本身的字符。
第二, 它的有效范围是它两边的整条规则,比如‘dog|cat’匹配的是‘dog’和’cat’,而不是’g’和’c’。如果想限定它的有效范围,必需使用一个无捕获组 ‘(?: )’包起来。比如要匹配 ‘I have a dog’或’I have a cat’,需要写成r’I have a (?:dog|cat)’ ,而不能写成 r’I have a dog|cat’,其中dog和cat是字符串,不能是变量。
例:
s = ‘I have a dog , I have a cat’
re.findall( r’I have a (?:dog|cat)’ , s )
[‘I have a dog’, ‘I have a cat’] #正如我们所要的
下面再看看不用无捕获组会是什么后果:
re.findall( r’I have a dog|cat’ , s )
[‘I have a dog’, ‘cat’] #它将’I have a dog’ 和’cat’当成两个规则了
至于无捕获组的使用,后面将仔细说明。这里先跳过。
一个bug?
上面正如官网[re — Regular expression operations¶]所说,'|' 操作符绝不贪婪,但是print(re.search('(?<!d)c|(?:ab)c', 'abc').group(0))返回的是abc而不是第一个匹配c,这个很让lz疑惑。
‘.’ 匹配所有字符匹配除换行符’\n’外的所有字符
如果使用了=re.S选项,匹配包括’\n’的所有字符。
例:
s=’123 \n456 \n789’
findall(r‘.+’,s)
[‘123’, ‘456’, ‘789’]
re.findall(r‘.+’ , s , re.S)
[‘123\n456\n789’]
‘^’和’$’ 匹配字符串开头和结尾
注意’^’不能在‘[ ]’中,否则请看上面的’[‘ ‘]’说明。
在多行模式下,它们可以匹配每一行的行首和行尾。具体请看后面compile函数说明的’M’选项部分
‘\A’ 匹配字符串开头
匹配字符串的开头。它和’^’的区别是,’\A’只匹配整个字符串的开头(相当于单行模式),即使在’M’模式下,它也不会匹配其它行的行首。
‘\Z’ 匹配字符串结尾
匹配字符串的结尾。它和’$’的区别是,’\Z’只匹配整个字符串的结尾,即使在’M’模式下,它也不会匹配其它各行的行尾。
例:
s= ‘12 34\n56 78\n90’
re.findall( r’^\d+’ , s , re.M ) #匹配位于行首的数字
[‘12’, ‘56’, ‘90’]
re.findall( r’\A\d+’, s , re.M ) #匹配位于字符串开头的数字
[‘12’]
re.findall( r’\d+$’ , s , re.M ) #匹配位于行尾的数字
[‘34’, ‘78’, ‘90’]
re.findall( r’\d+\Z’ , s , re.M ) #匹配位于字符串尾的数字
[‘90’]
‘\d’ 匹配数字
’\d’表示匹配一个数字,即等价于[0-9]
‘\D’ 匹配非数字
匹配一个非数字的字符,等价于[^0-9]
‘\w’ 匹配字母和数字
匹配所有的英文字母和数字(还包括中文!!!),即等价于[a-zA-Z0-9]。
‘\W’ 匹配非英文字母和数字
即’\w’的补集,等价于[^a-zA-Z0-9]。
匹配中文
r'[\u4e00-\u9fa5]+'
py2可能需要:如果是中文匹配,一定要先将中文解码成unicode decode('中文的编码类型如utf-8/gbk')(如py2中),输出时再编码成.encode('中文的编码类型如utf-8/gbk')。否则使用如[中文],可能并不是匹配这两个中文中的任意一个,而是对应字节的4个字节中的一个了[\?\?\?\?]。
‘\s’ 匹配间隔符
即匹配空格符、制表符、回车符等表示分隔意义的字符,它等价于[ \t\r\n\f\v]。(注意最前面有个空格)
‘\S’ 匹配非间隔符
即间隔符的补集,等价于[^ \t\r\n\f\v]
‘\b’ 匹配单词边界(相当于前向界定和后向界定)
它匹配一个单词的边界,比如空格等,不过它是一个‘0’长度字符,它匹配完的字符串不会包括那个分界的字符。而如果用’\s’来匹配的话,则匹配出的字符串中会包含那个分界符。
例:
s = ‘abc abcde bc bcd’
re.findall( r’\bbc\b’ , s ) #匹配一个单独的单词 ‘bc’ ,而当它是其它单词的一部分的时候不匹配
[‘bc’] #只找到了那个单独的’bc’
re.findall( r’\sbc\s’ , s ) #匹配一个单独的单词 ‘bc’
[’ bc ‘] #只找到那个单独的’bc’,不过注意前后有两个空格,可能有点看不清楚
‘\B’ 匹配非边界
和’\b’相反,它只匹配非边界的字符。它同样是个0长度字符。
re.findall( r’\Bbc\w+’ , s ) #匹配包含’bc’但不以’bc’为开头的单词
[‘bcde’] #成功匹配了’abcde’中的’bcde’,而没有匹配’bcd’
精确匹配和最小匹配
Python正则式还可以精确指定匹配的次数 :
1. ‘{m}’ 精确匹配m次; ‘{m,n}’ 匹配最少m次,最多n次。(n>m)
2. 如果你只想指定一个最少次数或只指定一个最多次数,你可以把另外一个参数空起来。比如你想指定最少3次,可以写成 {3,} (注意那个逗号),同样如果只想指定最大为5次,可以写成{,5},也可以写成{0,5}。
例 寻找下面字符串中
a:3位数
b: 2位数到4位数
c: 5位数以上的数
d: 4位数以下的数
>>> s= ‘ 1 22 333 4444 55555 666666 ‘
>>> re.findall( r’\b\d{3}\b’ , s ) # a:3位数
['333']
>>> re.findall( r’\b\d{2,4}\b’ , s ) # b: 2位数到4位数
['22', '333', '4444']
>>> re.findall( r’\b\d{5,}\b’, s ) # c: 5位数以上的数
['55555', '666666']
>>> re.findall( r’\b\d{1,4}\b’ , s ) # 4位数以下的数
['1', '22', '333', '4444']数量词的贪婪模式与非贪婪模式 ‘*?’ ‘+?’ ‘??’ 最小匹配
正则表达式通常用于在文本中查找匹配的字符串。Python里数量词默认是贪婪的(在少数语言里也可能是默认非贪婪),总是尝试匹配尽可能多的字符;非贪婪的则相反,总是尝试匹配尽可能少的字符。例如:正则表达式"ab*"如果用于查找"abbbc",将找到"abbb"。而如果使用非贪婪的数量词"ab*?",将找到"a"。[python正则表达式]
‘*’ ‘+’ ‘?’通常都是尽可能多的匹配字符。有时候我们希望它尽可能少的匹配。比如一个c语言的注释 ‘/* part 1 */ /* part 2 */’,如果使用最大规则:
>>> s =r ‘/* part 1 */ code /* part 2 */’
>>> re.findall( r’/\*.*\*/’ , s )
[‘/* part 1 */ code /* part 2 */’]结果把整个字符串都包括进去了。如果把规则改写成
>>> re.findall( r’/\*.*?\*/’ , s ) #在*后面加上?,表示尽可能少的匹配
['/* part 1 */', '/* part 2 */']结果正确的匹配出了注释里的内容
‘(?:)’ 无捕获组
当你要将一部分规则作为一个整体对它进行某些操作,比如指定其重复次数时,你需要将这部分规则用’(?:’ ‘)’把它包围起来,而不能仅仅只用一对括号。
例:匹配字符串中重复的’ab’
s=’ababab abbabb aabaab’
re.findall( r’\b(?:ab)+\b’ , s )
[‘ababab’]
如果仅使用一对括号: re.findall( r’\b(ab)+\b’ , s )
[‘ab’]
这是因为如果只使用一对括号,那么这就成为了一个组(group)。
‘(?# )’ 注释
Python允许你在正则表达式中写入注释,在’(?#’ ‘)’之间的内容将被忽略。
(?iLmsux) 编译选项指定
Python的正则式可以指定一些选项,这个选项可以写在findall或compile的参数中,也可以写在正则式里,成为正则式的一部分。这在某些情况下会便利一些。具体的选项含义请看后面的compile函数的说明。
此处编译选项’i’ 等价于IGNORECASE ,L 等价于 LOCAL ,m 等价于 MULTILINE ,s 等价于 DOTALL ,u 等价于 UNICODE , x 等价于 VERBOSE 。
请注意它们的大小写。在使用时可以只指定一部分,比如只指定忽略大小写,可写为 ‘(?i)’,要同时忽略大小写并使用多行模式,可以写为 ‘(?im)’。
另外要注意选项的有效范围是整条规则,即写在规则的任何地方,选项都会对全部整条正则式有效。
前向界定与后向界定
有时候需要匹配一个跟在特定内容后面的或者在特定内容前面的字符串,Python提供一个简便的前向界定和后向界定功能,或者叫前导指定和跟从指定功能。它们是:
‘(?<=…)’ 前向界定
匹配字符串的当前位置,它前面匹配 … 的内容到当前位置。这叫:dfn:positive lookbehind assertion(正向后视断定)。 (?<=abc)def 会在 'abcdef' 中找到一个匹配,因为后视会往后看3个字符并检查是否包含匹配的样式。包含的匹配样式必须是定长的,即使用前向界定的字符串长度必须是常数,意思就是 abc 或 a|b 是允许的,但是 a* 和 a{3,4}还有a|bc不可以,否则报错:sre_constants.error: look-behind requires fixed-width pattern。解决方案是相同长度的字符串加到不同的n个前向界定如(?<!a|e)(?<!bc|df)。
示例:
前面不能是两个字符(包括中文)以上就替换:
a = "省|自治区|市|特别行政区|县|自治州|(?<!^\\w{1})州|自治县|区|镇|旗|自治旗|林区|街道|少数民族乡|民族乡|自治乡|乡|壮族|回族|满族|维吾尔族?|苗族|彝族|土家族|藏族|(?<!内)蒙古族?|侗族|布依族|瑶族|白族|朝鲜族|哈尼族|黎族|哈萨克族|傣族|锡伯族|傈僳族"
print(re.sub(a, '', "文山州")) print(re.sub(a, '', "苏州"))
输出:文山 苏州
Note:java中的实现:(?<!^[\u4e00-\u9fa5])州 或者 (?<=^[\u4e00-\u9fa5]{2,})州(java中后面这个不会出fixed-width pattern错误)
注意以 positive lookbehind assertions 开始的样式,如 (?<=abc)def ,并不是从 a 开始搜索,而是从 d 往回看的。
‘(?=…)’ 后向界定
括号中的’…’代表你希望匹配的字符串后面应该出现的字符串。
例: 你希望找出c语言的注释中的内容,它们是包含在’/’和’/’之间,不过你并不希望匹配的结果把’/’和’/’也包括进来,那么你可以这样用:
s=r'/* comment 1 */ code /* comment 2 */'
print(re.findall(r'(?<=/\*).*?(?=\*/)', s))
[' comment 1 ', ' comment 2 ']Note:
1. 注意这里我们仍然使用了最小匹配,以避免把整个字符串给匹配进去了。
2. 前向界定括号中的表达式必须是常值,也即你不可以在前向界定的括号里写正则式或者变量。
比如你如果在下面的字符串中想找到被字母夹在中间的数字,你不可以用前向界定:
s = ‘aaa111aaa , bbb222 , 333ccc ‘
re.findall( r’(?<=[a-z]+)\d+(?=[a-z]+)’ , s ) # 错误的用法
它会给出一个错误信息:
error: look-behind requires fixed-width pattern
不过如果你只要找出后面接着有字母的数字,你可以在后向界定写正则式:
re.findall( r’\d+(?=[a-z]+)’, s )
[‘111’, ‘333’]
如果你一定要匹配包夹在字母中间的数字,你可以使用组(group)的方式
re.findall (r’[a-z]+(\d+)[a-z]+’ , s )
[‘111’]
组的使用将在后面详细讲解。
前向非界定和后向非界定
‘(?< !…)’前向非界定(<和!中间是没有空格的,makedown编辑器会将博客中的< !当成注释不显示, - -!给醉了。。。)
只有当你希望的字符串前面不是’…’的内容时才匹配
‘(?!…)’后向非界定
只有当你希望的字符串后面不跟着’…’内容时才匹配。
接上例,希望匹配后面不跟着字母的数字
re.findall( r’\d+(?!\w+)’ , s )
[‘222’]
注意这里我们使用了\w而不是像上面那样用[a-z],因为如果这样写的话,结果会是:
re.findall( r’\d+(?![a-z]+)’ , s )
[‘11’, ‘222’, ‘33’]
这和我们期望的似乎有点不一样,是因为’111’和’222’中的前两个数字也是满足这个要求的。正则式的使用还是要相当小心的。
组
上面那些规则的话,还是有很多情况下会非常麻烦,比如使用前向界定和后向界定取夹在字母中间的数字的例子。用前面讲过的规则都很难达到目的,但是用了组以后就很简单了。
‘(‘’)’ 无命名组
最基本的组是由一对圆括号括起来的正则式。比如上面匹配包夹在字母中间的数字的例子中使用的(\d+),我们再回顾一下这个例子:
s = 'aaa111aaa , bbb222 , 333ccc '
print(re.findall (r'[a-z]+(\d+)[a-z]+' , s ) )
[‘111’]
Note:findall函数只返回了包含在’()’中的内容,而虽然前面和后面的内容都匹配成功了,却并不包含在结果中。
用组来实现前后向界定
s = 'dfidabc:dfidefdoildef'
pre = 'abc'
post = 'def'
patten = pre + '[::].+?' + post
answer = re.findall(patten, s)
print(answer)
['abc:dfidef']
Note:其中还用到了上面的最小匹配规则
‘(?P…)’ 命名组
‘(?P’代表这是一个Python的语法扩展’<…>’里面是你给这个组起的名字,比如你可以给一个全部由数字组成的组叫做’num’,它的形式就是’(?P\d+)’ {’(?P<num>\d+)’吧}。起了名字之后,我们就可以在后面的正则式中通过名字调用这个组,它的形式是‘(?P=name)’ 调用已匹配的命名组。
要注意,再次调用的这个组是已被匹配的组,也就是说它里面的内容是和前面命名组里的内容是一样的。
s=’aaa111aaa,bbb222,333ccc,444ddd444,555eee666,fff777ggg’
我们看看下面的正则式会返回什么样的结果:
re.findall( r’([a-z]+)\d+([a-z]+)’ , s ) # 找出中间夹有数字的字母
[(‘aaa’, ‘aaa’), (‘fff’, ‘ggg’)]
re.findall( r ‘(?P[a-z]+)\d+(?P=g1)’ , s ) #找出被中间夹有数字的前后同样的字母
[‘aaa’]
re.findall( r’[a-z]+(/d+)([a-z]+)’ , s ) #找出前面有字母引导,中间是数字,后面是字母的字符串中的中间的数字和后面的字母
[(‘111’, ‘aaa’), (‘777’, ‘ggg’)]
我们可以通过命名组的名字在后面调用已匹配的命名组,不过名字也不是必需的。
‘\number’ 通过序号调用已匹配的组
正则式中(并不能使用在sub函数中)的每个组都有一个序号,序号是按组从左到右,从1开始的数字,你可以通过下面的形式来调用已匹配的组
比如上面找出被中间夹有数字的前后同样的字母的例子,也可以写成:
re.findall( r’([a-z]+)\d+\1’ , s )
[‘aaa’]
结果是一样的。
再看一个例子
s=’111aaa222aaa111 , 333bbb444bb33’
re.findall( r’(\d+)([a-z]+)(\d+)(\2)(\1)’ , s ) #找出完全对称的 数字-字母-数字-字母-数字 中的数字和字母
[(‘111’, ‘aaa’, ‘222’, ‘aaa’, ‘111’)]
条件匹配功能(Python2.4以后的re模块)
‘(?(id/name)yes-pattern|no-pattern)’ 判断指定组是否已匹配,执行相应的规则
这个规则的含义是,如果id/name指定的组在前面匹配成功了,则执行yes-pattern的正则式,否则执行no-pattern的正则式。
举个例子,比如要匹配一些形如 usr@mail 的邮箱地址,不过有的写成< usr@mail >即用一对<>括起来,有点则没有,要匹配这两种情况,可以这样写
>>> s=<usr1@mail1> usr2@maill2'
>>> re.findall( r'(<)?\s*(\w+@\w+)\s*(?(1)>)' , s )
[('<', 'usr1@mail1'), ('', 'usr2@maill2')]不过如果目标字符串如下
>>> s='<usr1@mail1> usr2@maill2 <usr3@mail3 usr4@mail4> < usr5@mail5 '而你想得到要么由一对<>包围起来的一个邮件地址,要么得到一个没有被<>包围起来的地址,但不想得到一对<>中间包围的多个地址或不完整的<>中的地址,那么使用这个式子并不能得到你想要的结果
>>> re.findall( r'(<)?\s*(\w+@\w+)\s*(?(1)>)' , s )
[('<', 'usr1@mail1'), ('', 'usr2@maill2'), ('', 'usr3@mail3'), ('', 'usr4@mail4'), ('', 'usr5@mail5')]它仍然找到了所有的邮件地址。想要实现这个功能,单纯的使用findall有点吃力,需要使用其它的一些函数,比如match或search函数,再配合一些控制功能。
[Regular Expression Syntax¶]
正则表达式可视化

[正则可视化]
[regexper]
python正则表达式re模块
正则表达式使用示例
1 . 校验密码强度
密码的强度必须是包含大小写字母和数字的组合,不能使用特殊字符,长度在8-10之间。
^(?=.*\\d)(?=.*[a-z])(?=.*[A-Z]).{8,10}$
4. 校验E-Mail 地址
[\\w!#$%&'*+/=?^_`{|}~-]+(?:\\.[\\w!#$%&'*+/=?^_`{|}~-]+)*@(?:[\\w](?:[\\w-]*[\\w])?\\.)+[\\w](?:[\\w-]*[\\w])?
5. 校验身份证号码
15位:
^[1-9]\\d{7}((0\\d)|(1[0-2]))(([0|1|2]\\d)|3[0-1])\\d{3}$
18位:
^[1-9]\\d{5}[1-9]\\d{3}((0\\d)|(1[0-2]))(([0|1|2]\\d)|3[0-1])\\d{3}([0-9]|X)$
6. 校验日期
“yyyy-mm-dd“ 格式的日期校验,已考虑平闰年。
^(?:(?!0000)[0-9]{4}-(?:(?:0[1-9]|1[0-2])-(?:0[1-9]|1[0-9]|2[0-8])|(?:0[13-9]|1[0-2])-(?:29|30)|(?:0[13578]|1[02])-31)|(?:[0-9]{2}(?:0[48]|[2468][048]|[13579][26])|(?:0[48]|[2468][048]|[13579][26])00)-02-29)$
8. 校验手机号
下面是国内 13、15、18开头的手机号正则表达式。(可根据目前国内收集号扩展前两位开头号码)
^(13[0-9]|14[5|7]|15[0|1|2|3|5|6|7|8|9]|18[0|1|2|3|5|6|7|8|9])\\d{8}$
10. 校验IP-v4地址
\\b(?:(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\\.){3}(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\\b
11. 校验IP-v6地址
(([0-9a-fA-F]{1,4}:){7,7}[0-9a-fA-F]{1,4}|([0-9a-fA-F]{1,4}:){1,7}:|([0-9a-fA-F]{1,4}:){1,6}:[0-9a-fA-F]{1,4}|([0-9a-fA-F]{1,4}:){1,5}(:[0-9a-fA-F]{1,4}){1,2}|([0-9a-fA-F]{1,4}:){1,4}(:[0-9a-fA-F]{1,4}){1,3}|([0-9a-fA-F]{1,4}:){1,3}(:[0-9a-fA-F]{1,4}){1,4}|([0-9a-fA-F]{1,4}:){1,2}(:[0-9a-fA-F]{1,4}){1,5}|[0-9a-fA-F]{1,4}:((:[0-9a-fA-F]{1,4}){1,6})|:((:[0-9a-fA-F]{1,4}){1,7}|:)|fe80:(:[0-9a-fA-F]{0,4}){0,4}%[0-9a-zA-Z]{1,}|::(ffff(:0{1,4}){0,1}:){0,1}((25[0-5]|(2[0-4]|1{0,1}[0-9]){0,1}[0-9])\\.){3,3}(25[0-5]|(2[0-4]|1{0,1}[0-9]){0,1}[0-9])|([0-9a-fA-F]{1,4}:){1,4}:((25[0-5]|(2[0-4]|1{0,1}[0-9]){0,1}[0-9])\\.){3,3}(25[0-5]|(2[0-4]|1{0,1}[0-9]){0,1}[0-9]))
12. 检查URL的前缀
应用开发中很多时候需要区分请求是HTTPS还是HTTP,通过下面的表达式可以取出一个url的前缀然后再逻辑判断。
if (!s.match(/^[a-zA-Z]+:\\/\\//))
{
s = 'http://' + s;
}
13. 提取URL链接
^(f|ht){1}(tp|tps):\\/\\/([\\w-]+\\.)+[\\w-]+(\\/[\\w- ./?%&=]*)?
14. 文件路径及扩展名校验
验证windows下文件路径和扩展名(下面的例子中为.txt文件)
^([a-zA-Z]\\:|\\\\)\\\\([^\\\\]+\\\\)*[^\\/:*?"<>|]+\\.txt(l)?$
15. 提取Color Hex Codes
有时需要抽取网页中的颜色代码,可以使用下面的表达式。
^#([A-Fa-f0-9]{6}|[A-Fa-f0-9]{3})$
16. 提取网页图片
假若你想提取网页中所有图片信息,可以利用下面的表达式。
\\< *[img][^\\\\>]*[src] *= *[\\"\\']{0,1}([^\\"\\'\\ >]*)
17. 提取html页面超链接
(<a\\s*(?!.*\\brel=)[^>]*)(href="https?:\\/\\/)((?!(?:(?:www\\.)?'.implode('|(?:www\\.)?', $follow_list).'))[^"]+)"((?!.*\\brel=)[^>]*)(?:[^>]*)>
18. 查找CSS属性
^\\s*[a-zA-Z\\-]+\\s*[:]{1}\\s[a-zA-Z0-9\\s.#]+[;]{1}
19. 抽取移除HMTL注释
<!--(.*?)-->
20. 匹配HTML标签属性
<\\/?\\w+((\\s+\\w+(\\s*=\\s*(?:".*?"|'.*?'|[\\^'">\\s]+))?)+\\s*|\\s*)\\/?>
21. 匹配不是以abc开头的行
^[^abc].*\n
正则表达式中容易出错的bug
使用python中的re模块进行匹配(或者其它的如sql中的)
r = re.match('(\d+)-(\d+)(?!个|月)', '0-10个月')这个返回<_sre.SRE_Match object; span=(0, 3), match='0-1'>
说明正则匹配时只要能匹配就匹配,也没有那么默认非贪婪。
利用正则表达式排除特定字符串
^(?!.*helloworld).*$
from:Python输入输出详解_-柚子皮-的博客-优快云博客
ref:¶

















 539
539

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









