






 本文详细介绍了PyTorch中分布式训练的两种主要模式:Parameter Server和Allreduce,探讨了同步更新与异步更新的优缺点,并强调Allreduce模式在现代深度学习中的重要性。此外,还提到了PyTorch分布式训练的具体实施步骤和注意事项。
本文详细介绍了PyTorch中分布式训练的两种主要模式:Parameter Server和Allreduce,探讨了同步更新与异步更新的优缺点,并强调Allreduce模式在现代深度学习中的重要性。此外,还提到了PyTorch分布式训练的具体实施步骤和注意事项。
不同数据并行方案(parameter server 模式和 allreduce 模式,同步更新和异步更新)的详细介绍。
分布式算法原理
Parameter server 模式
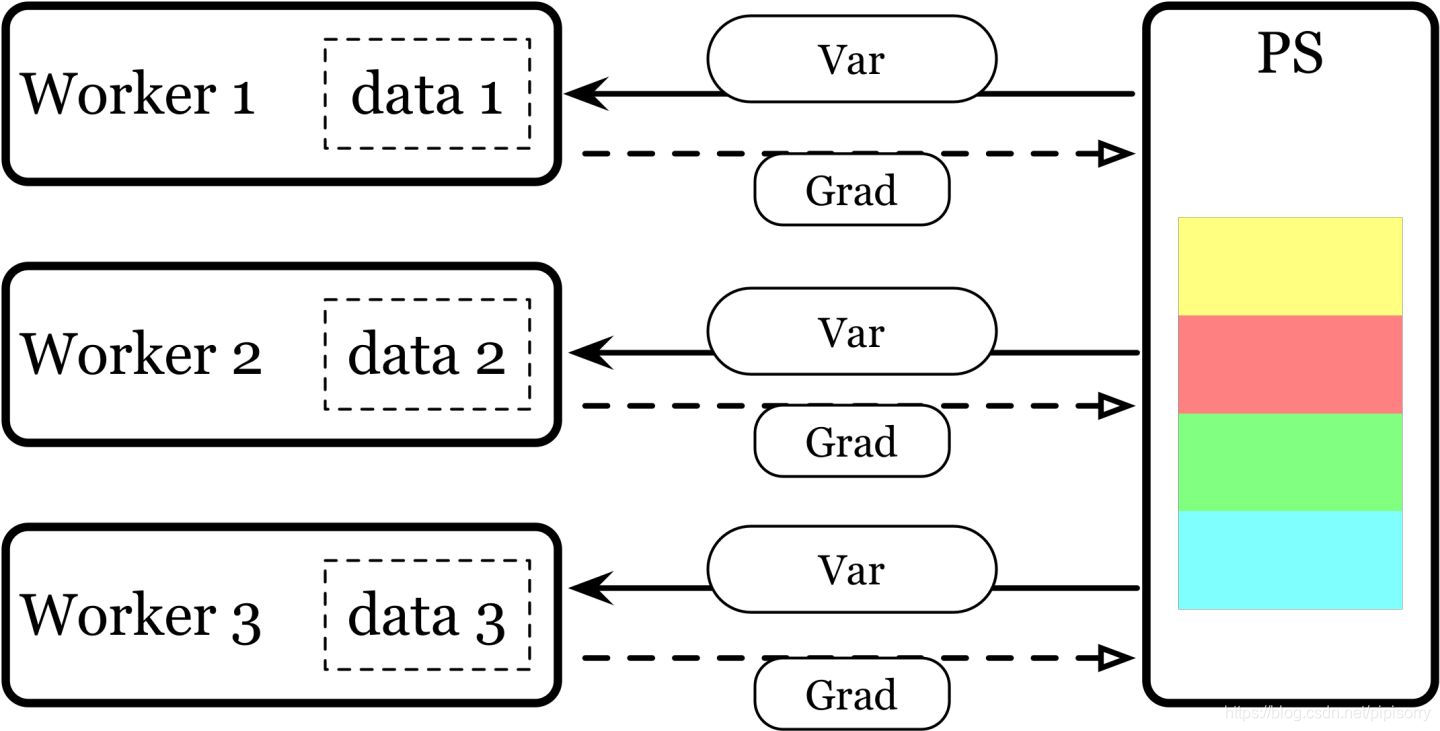
以参数𝜃为同步基础,我们可以采用 master-slave 的同步模式:将 node 分成两种角色:parameter server(ps) 负责维护一份最新的参数 ,worker 负责利用从 ps 读到的最新参数计算出梯度(forward 和 backprop),并对 ps 发送梯度和参数更新请求。这被称为 parameter server 的模式,tensorflow 就是围绕这个思路设计的。
Deep learning 之前的大规模模型通常体现在特征量上,模型仍旧是浅层的线性模型。特征量增大(百万到千万级别的特征量)带来的是特征的稀疏,所以每个 worker 平均只需要很少一部分变量就可以完成计算,和 ps 间的数据传输量不会很大。早期每个 host 的算力和资源量不大,所以增大计算规模往往意味着增大主机的数量,这带来的是 host 故障率的提高。 master-slave 的模式可以让系统拥有较好的容错能力。
但是现在随着模型的加深,参数之间的相互依赖增大,需要传输的参数量增大,使得 ps 的传输带宽逐渐成为瓶颈。而随着 host 计算能力的增强,我们需要的 host 数越来越少,故障率变低,容错的需求也越来越少。现在主流的做法更是变成了单机多卡。这使得 parameter server 的设计变得不适用于深度学习的计算。
ps 拿到参数后,视更新的方案不同可以分为同步更新(synchronous update)和异步更新(asynchronous update)。
同步更新
这是最低效的方案,这也是 tensorflow 多卡官方示例介绍的方案。ps 会同时充当 reducer 的角色,等待所有 worker 都发来梯度和参数更新请求后,ps 会对梯度取平均(reduce mean),并用平均过后的梯度更新一次参数。各个 worker 在从 ps 读取最新参数的过程中,以及等待 ps 更新参数的过程中,都是处于空闲状态。
异步更新
谷歌是最早使用 parameter server + 异步更新方案进行深度网络训练的。异步更新是 parameter server 模式的标配,其收敛性已经有证明。与同步更新不同,异步更新中 ps 在收到 worker 的梯度以及更新请求的时候,会立即对参数发起更新,而不等待其他 worker。在完成梯度的计算后,worker 会立刻从 ps 上读取参数,进行下一步的迭代。
异步更新将各个 work 和 ps 的通信在时间上分散开,使得数据传输的等待时间减少。同时各个 worker 也不需要和其他 worker 同步,减少了阻塞的时间,特别是异构的 worker 产生的阻塞。这增加了模型训练的吞吐量(throughput)。
但是异步更新的方案会引入两个不稳定性来源:
- 参数和更新用的梯度并不来自同一个迭代。用来更新的梯度可能是几步更新前的参数算出来的。
- 参数的读取并没有加锁。这导致 worker 可能会读到更新一半的参数。
对于落后于当前迭代的梯度(staled gradients),上述实现采取的做法是直接丢掉。这造成了不同 worker racing 的情况,对计算资源和数据的利用效率不高。
上述两个不稳定性来源要求模型采用更小的学习率(learning rate)。而小学习率加上上述的不稳定性会带来收敛速度的显著降低,同时训练发散(divergence)的风险也增大了,这两者抵消了异步训练带来的吞吐量的提高。实际使用中经常会看到 loss 有时候会突然变得很高(overshoot)。所以异步更新目前已经不是主流优化方向了。
Allreduce 模式
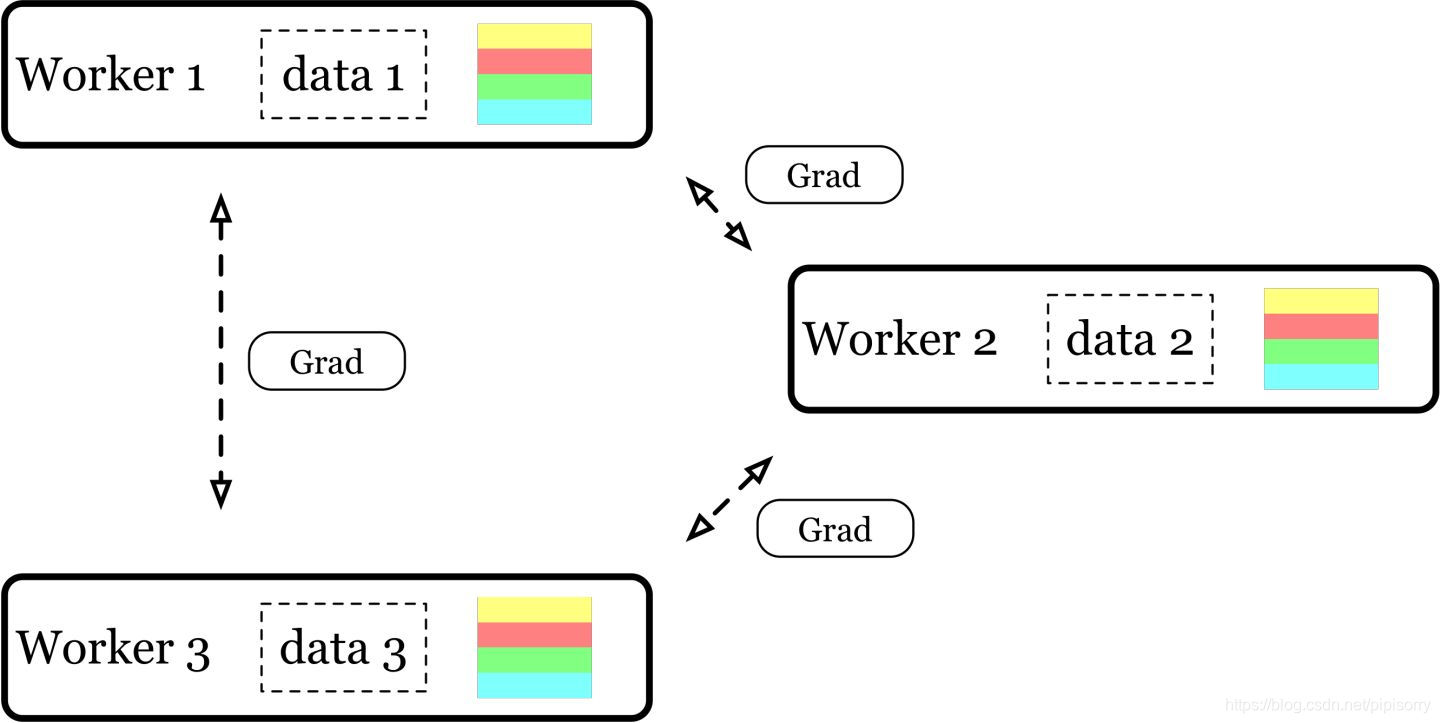
参数 𝜃 的变化来自于使用各个 node 算出的梯度对其进行的更新。如果在初始化的时候便同步了所有 node 拿到的参数拷贝 𝜃_i ,并在参数更新之前对梯度进行同步,这样在任何时刻各个 node 的参数拷贝 𝜃_i 都是一致的。所以我们可以以梯度为同步基础,间接实现参数 𝜃 的同步。而梯度的同步则依赖于 allreduce 操作(peer-to-peer 的通信)的高效实现。在 Allreduce 模式中,所有 node 同时充当 ps 和 worker 的角色。
每个 node 可以直接利用本地的参数拷贝 𝜃_i 进行 forward 和 backprop 的计算,免除了 parameter server 模式中从 ps 读取参数的阻塞。所有 node 都得到算出梯度后,执行 allreduce 操作,各个 node 都会得到全部 node 的梯度平均。最后各个 node 利用拿到的梯度平均对本地的 𝜃_i 进行一次更新。在目前简单的 ring-allreduce 的实现下,各个 node 需要发送和接受一份梯度。
Nvidia 开发了高效的 GPU 集合通信库 NCCL (Nvidia collective communication library)。
parameter server + 异步更新会因为 node 数目的增加而使得 worker 平均可以使用的 PCIe 带宽减少。Allreduce 模式则没有这个问题:由于使用了 ring-allreduce,传输耗时在一定规模内基本不随 node 数目的增加而变化,计算提速和 node 数目可以大致做到线性关系(linear scaling)。但集群规模变大的时候,由于卡间直连的成本变高,通常会设置多个中间通信节点(switch),从而产生网络阻塞,此时线性关系也不再成立。
同步更新也让我们可以使用比异步更新更大的学习率(learning rate),且训练发散(divergence)的风险和单卡训练一致。但当系统中存在异构的 worker 的时候,更新仍然会被最慢的 worker 阻塞住。所幸随着 host 的计算能力增强,计算需要的 host 数量减少,worker 同构的要求比较容易实现。
Allreduce 模式由于可扩展性强,现在已经渐渐成为主流的多卡/分布式训练方案。
ring-allreduce
ring-allreduce 在并行计算领域提出很久了,但是直到2017年,百度才高效地在 tensorflow 上实现了基于 ring-allreduce 的深度学习分布式训练。这是他们介绍时用的 slides。Nvidia在介绍 NCCL 的 slides 里面也有一个很形象的算法图示。
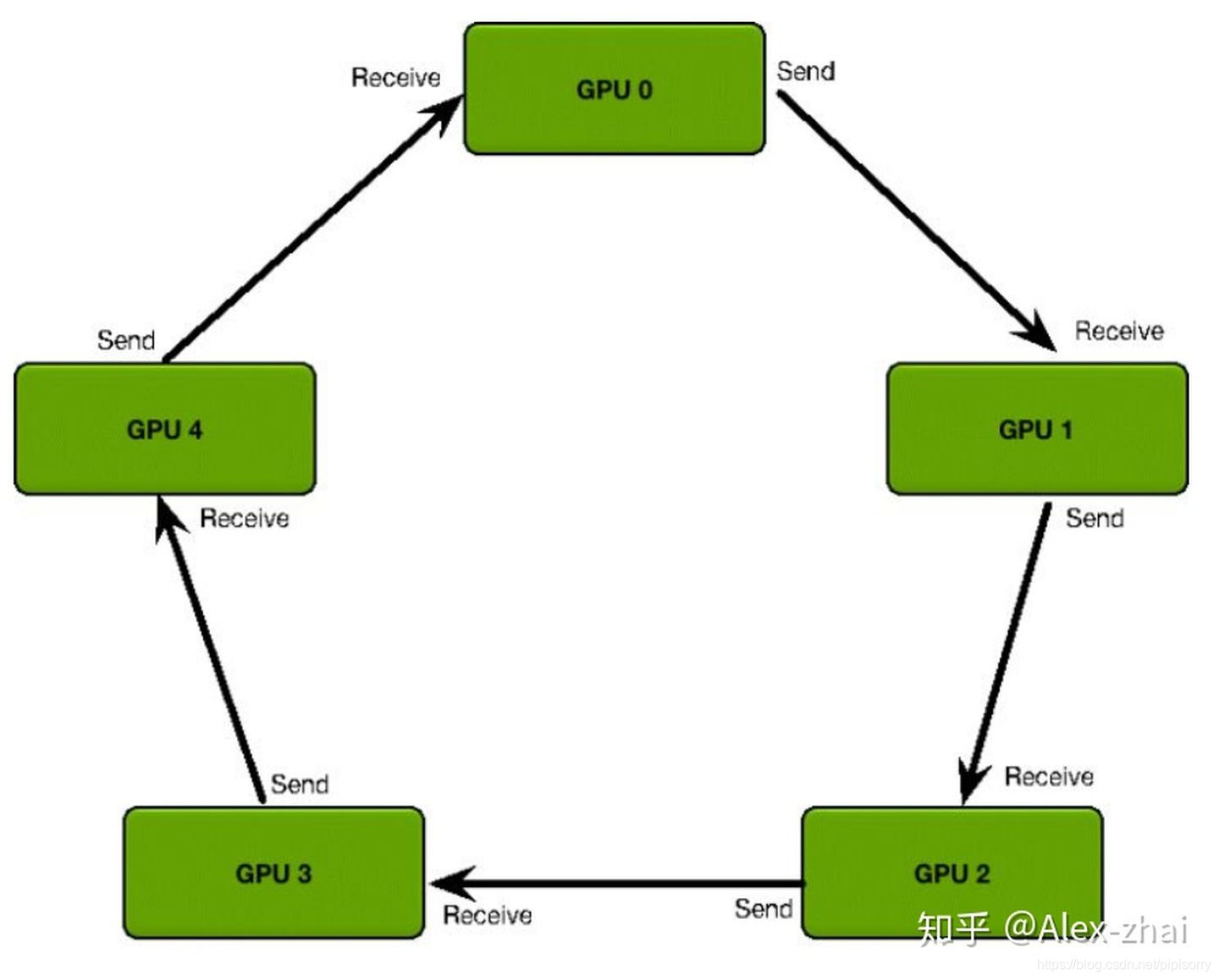
每个 GPU 只从左邻居接受数据、并发送数据给右邻居。
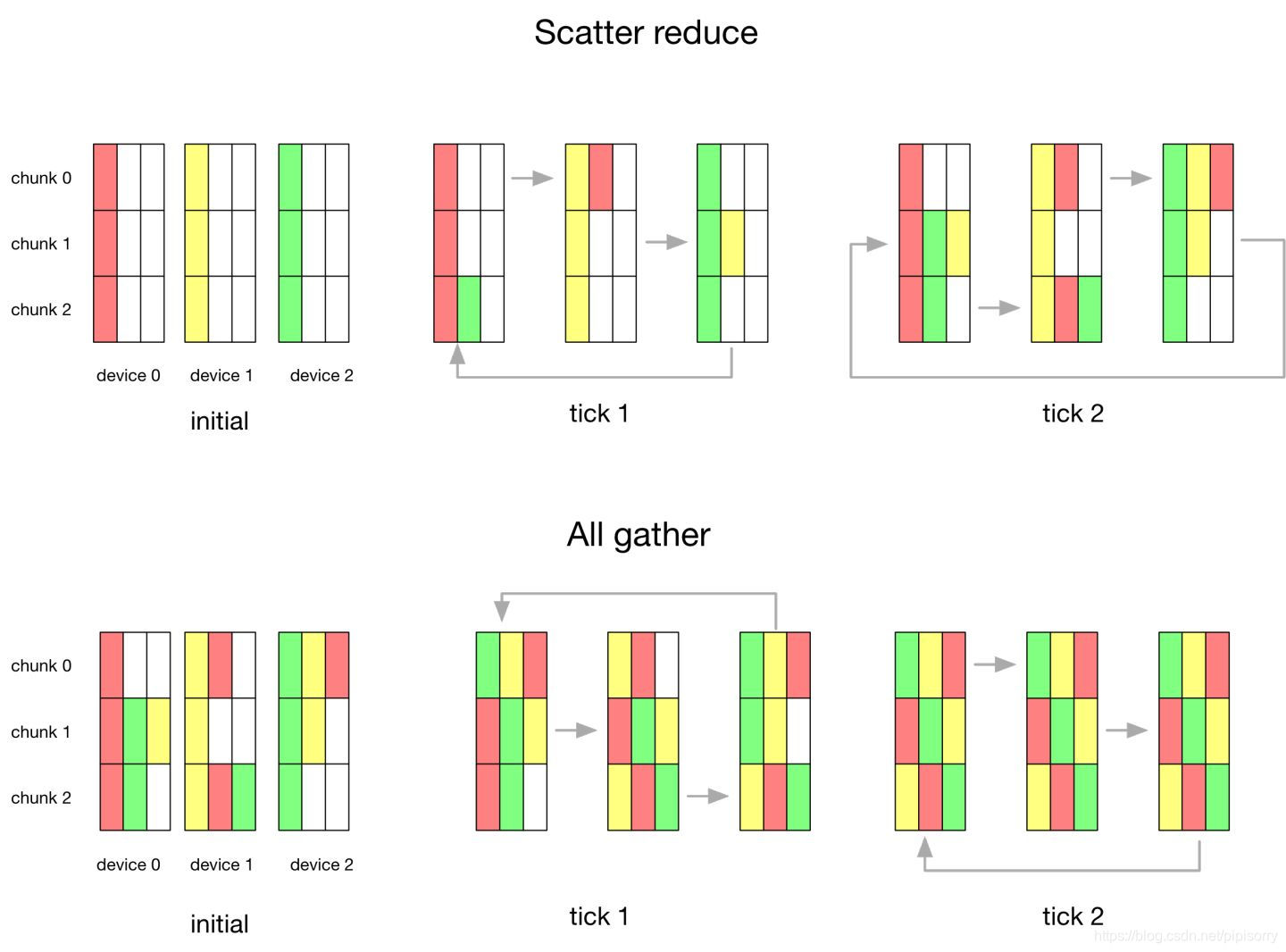
算法主要分两步:
1. scatter-reduce:会逐步交换彼此的梯度并融合,最后每个 GPU 都会包含完整融合梯度的一部分。
2. allgather:GPU 会逐步交换彼此不完整的融合梯度,最后所有 GPU 都会得到完整的融合梯度。
[浅谈Tensorflow分布式架构:ring all-reduce算法]
Pytorch分布式训练方法说明
[分布式训练的通讯方法[Point-to-Point Communication;Collective Communication]]
Pytorch分布式训练
分布式训练时:
1 需要将data/num_process。Assuming we have 2 replicas, then each process will have a train_set of 60000 / 2 = 30000 samples.
2 需要将batch_size/num_process。divide the batch size by the number of replicas in order to maintain the overall batch size of 128. 同时,如果batch_size/num_process,b变小,学习率应该也要变小。和https://youzipi.blog.youkuaiyun.com/article/details/109192443一致,也和ps异步更新中的“要求模型采用更小的学习率”一致。
示例
write our usual forward-backward-optimize training code, and add a function call to average the gradients of our models. (The following is largely inspired from the official PyTorch MNIST example.)
Note: size即world_size,分片个数;rank即分片id 范围[0, size-1]。
""" Distributed Synchronous SGD Example """
def run(rank, size):
torch.manual_seed(1234)
train_set, bsz = partition_dataset()
model = Net()
optimizer = optim.SGD(model.parameters(),
lr=0.01, momentum=0.5)
num_batches = ceil(len(train_set.dataset) / float(bsz))
for epoch in range(10):
epoch_loss = 0.0
for data, target in train_set:
optimizer.zero_grad()
output = model(data)
loss = F.nll_loss(output, target)
epoch_loss += loss.item()
loss.backward()
average_gradients(model)
optimizer.step()
print('Rank ', dist.get_rank(), ', epoch ',
epoch, ': ', epoch_loss / num_batches)
It remains to implement the average_gradients(model) function, which simply takes in a model and averages its gradients across the whole world.""" Gradient averaging. """
def average_gradients(model):
size = float(dist.get_world_size())
for param in model.parameters():
dist.all_reduce(param.grad.data, op=dist.reduce_op.SUM)
param.grad.data /= size[https://pytorch.org/tutorials/intermediate/dist_tuto.html#distributed-training]
from: -柚子皮-
ref:


















 235
235

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









