



 本文介绍了SQL窗口函数的作用和使用,包括组内排名、OLAP函数以及rank、dense_rank、row_number等专用窗口函数的实例应用。通过示例展示了如何利用窗口函数进行分组排序、统计每个部门员工人数以及解决经典排名和比较问题,对比了窗口函数与Group By和关联子查询的差异。
本文介绍了SQL窗口函数的作用和使用,包括组内排名、OLAP函数以及rank、dense_rank、row_number等专用窗口函数的实例应用。通过示例展示了如何利用窗口函数进行分组排序、统计每个部门员工人数以及解决经典排名和比较问题,对比了窗口函数与Group By和关联子查询的差异。
1: 窗口函数的作用
业务需求场景:
组内排名:部门业绩排名
找出某个部门业绩前几位的员工等
2:窗口函数使用
窗口函数,也叫OLAP函数(Online Anallytical Processing,联机分析处理),可以对数据库数据进行实时分析处理。
<窗口函数> over (
partition by <用于分组的列名>
order by <用于排序的列名>
)
其中<窗口函数>有以下形式
<窗口函数>
1) 专用窗口函数,包括后面要讲到的rank, dense_rank, row_number等专用窗口函数。
2) 聚合函数,如sum. avg, count, max, min等
3:实例应用
- 数据准备
create table t_empsalary (
id int,
dep varchar(10),
emp varchar(10),
salary number
)
insert into t_empsalary values (1,'财务部','张明',3000);
insert into t_empsalary values (2,'财务部','刘明',6500);
insert into t_empsalary values (3,'财务部','李云',3500);
insert into t_empsalary values (4,'行政部','李华',2500);
insert into t_empsalary values (5,'行政部','张玲',4000);
insert into t_empsalary values (6,'行政部','张花',3800);
insert into t_empsalary values (7,'销售部','张磊',3000);
insert into t_empsalary values (8,'销售部','李飞',16000);
insert into t_empsalary values (9,'销售部','肖明',8000);
insert into t_empsalary values (10,'销售部','韩磊',12000);select * from t_empsalary
数据据如下:其中dep,部门 emp,员工 salary 工资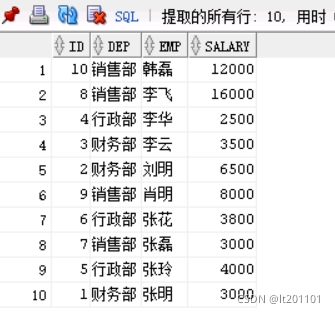
-
专用窗口函数 rank()
select dep,emp,salary,rank() over (partition by dep
order by salary desc) as ranking
from t_empsalary
查询结果如下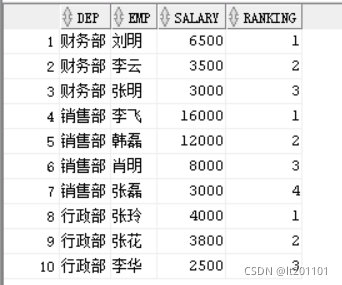
分析:
1)每个部门内:按部门分组
partition by用来对表分组。
2)按工资排名
order by子句的功能是对分组后的结果进行排序,
窗口函数具备了我们之前学过的group by子句分组的功能和order by子句排序的功能。那么,为什么还要用窗口函数呢?
以统计每个部门员工人数为例
Group By
select dep,count(emp)
from t_empsalary
group by dep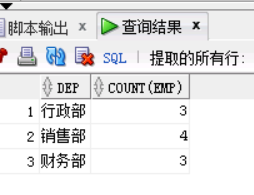
利用窗口函数统计
SELECT
dep,
emp,
salary,
count(emp) over
(
PARTITION BY dep
ORDER BY dep
) as 部门员工总数 FROM t_empsalary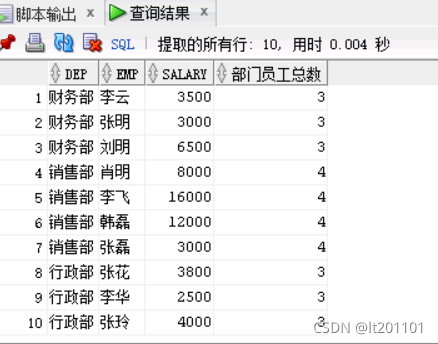
可以看出利用窗口函数可以实现
A:同时实现分组排序功能
B: 不改变原有数据记录数
-
其他专业窗口函数
rank, dense_rank, row_number
select dep,emp,salary,
rank() over (order by salary desc) as ranking,
dense_rank() over (order by salary desc) as dese_rank,
row_number() over (order by salary desc) as row_num
from t_empsalary
查询结果如下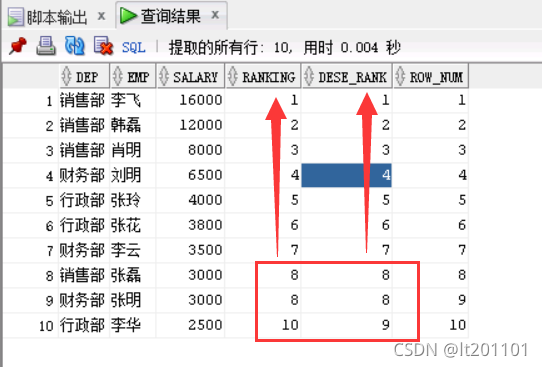
区别如红箭头指向
rank(): 1,2,3,3,5
dense_rank() 1,2,3,3,4
备注:上述的这三个专用窗口函数中,函数后面的括号不需要任何参数,保持()空着就可以 -
聚合窗口函数
select dep,emp,salary,
sum(salary) over (order by id) as current_sum,
avg(salary) over (order by id) as current_avg,
count(salary) over (order by id) as current_count,
max(salary) over (order by id) as current_max,
min(salary) over (order by id) as current_min
from t_empsalary
查询结果如下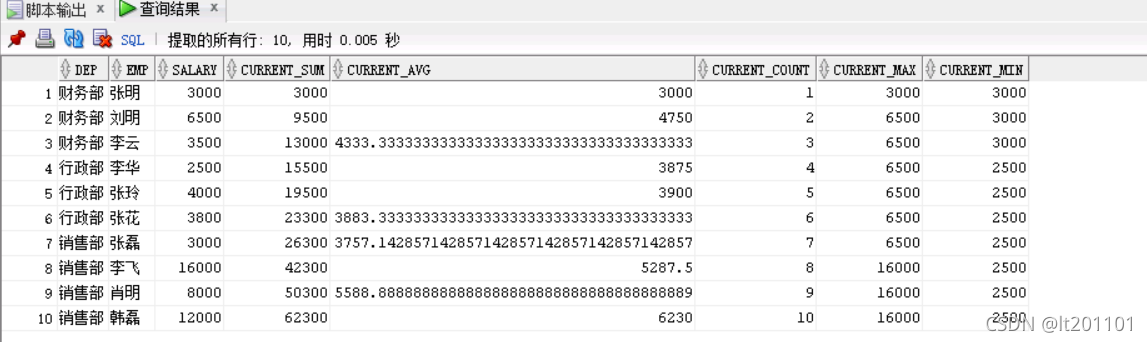
-
业务需求案例
需求1:查询工资高于组内员工平均工资的员工
不使用窗口函数
select a.*, b.asalary as 平均工资
from t_empsalary a
left join ( select dep, avg(salary) as asalary
from t_empsalary
group by dep)b
on b.dep = a.dep
where a.salary > b.asalary
结果: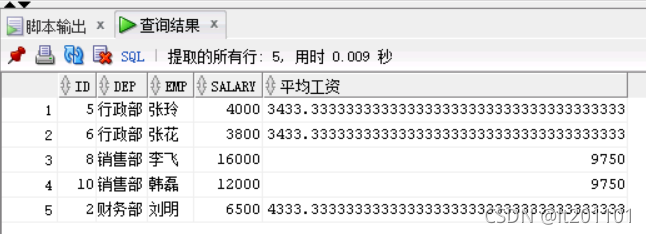
使用窗口函数
select * from
(select dep,emp,salary,
avg(salary) over(
partition by dep
) as 平均工资
from t_empsalary ) a
where salary > 平均工资
结果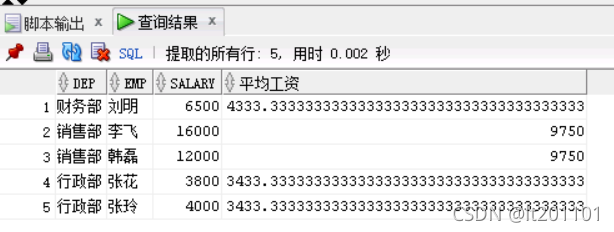
需求2:查询每个部门前工资最高的前2名员工
select * from
(select dep,emp,salary,
rank() over(
partition by dep
order by salary desc
) as sort
from t_empsalary) a
where a.sort<3
结果: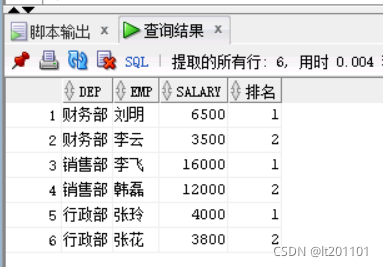
- 使用场景分析
1)经典top N问题
找出每个部门排名前N的员工
2)经典排名问题
业务需求“在每组内排名”,比如:每个部门按业绩来排名
3)在每个组里比较的问题
比如查找每个组里大于平均值的数据,可以有两种方法:
方法1,使用前面窗口函数案例来实现
方法2,使用关联子查询

















 177
177

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









