






接上一篇博客
把我的代码和别人的代码对比了一下,发现了些许的不同。
我是在推理的时候遇到了问题,可能问题的解决办法并不在推理处。
而是应该思考是不是在前一部分,建立会话的时候的时候出现了问题。
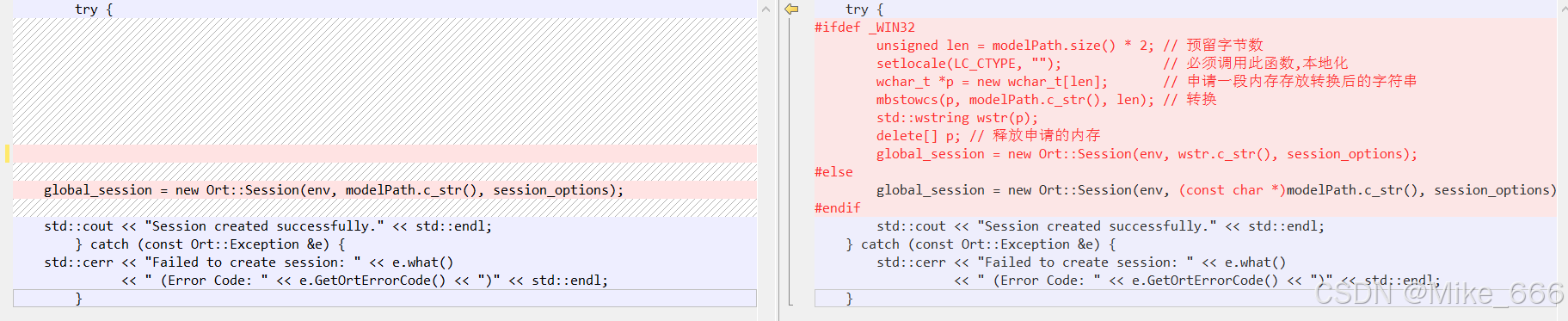
左边是我的代码,右边是别人的代码

---------------------------------------
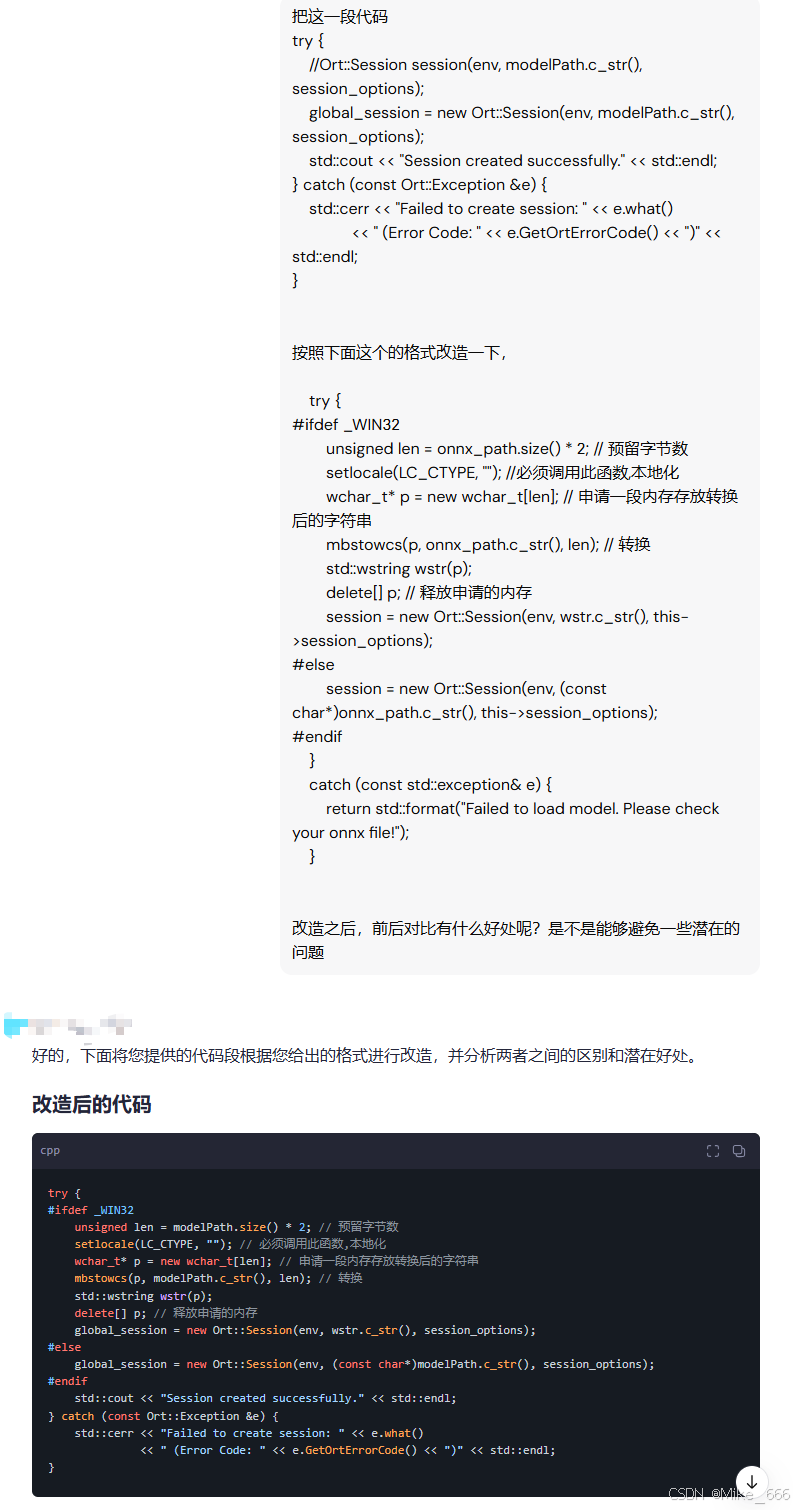

至此,问题解决
20241209
-----------------------------------------------------------------
接上一篇博客
把我的代码和别人的代码对比了一下,发现了些许的不同。
我是在推理的时候遇到了问题,可能问题的解决办法并不在推理处。
而是应该思考是不是在前一部分,建立会话的时候的时候出现了问题。
左边是我的代码,右边是别人的代码
---------------------------------------
至此,问题解决
20241209
-----------------------------------------------------------------
 13万+
4182
1407
1642
13万+
4182
1407
1642

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言



























