




 博客内容介绍了如何处理PAT(A1025)排名问题,包括输入输出格式、解决思路和注意事项。首先,按考场读取数据并排序,接着对所有考生进行全局排序,并计算排名。关键在于处理分数相同的情况,确保排名的正确性。代码实现中包含了对排名的记录和输出方法。
博客内容介绍了如何处理PAT(A1025)排名问题,包括输入输出格式、解决思路和注意事项。首先,按考场读取数据并排序,接着对所有考生进行全局排序,并计算排名。关键在于处理分数相同的情况,确保排名的正确性。代码实现中包含了对排名的记录和输出方法。
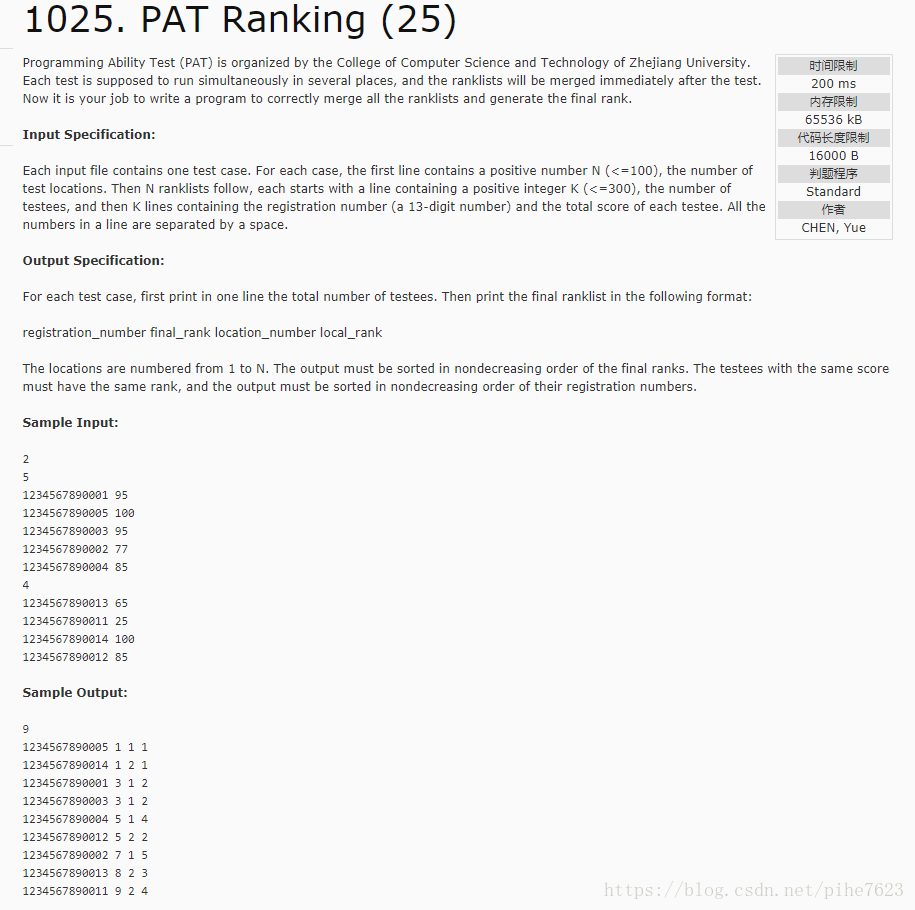
输入输出翻译:
输入:
第一行:输入考场数目n
第二行:输入第一个考场人数k
此处k行 输入准考证号 成绩
上面两行的循环
输出:
第一行:总人数
第二行:准考证号 排名 考场号 考场中的排名
思路:
按输入读入,第二行开始是一个循环。
结构体存信息,cmp函数中用strcmp<0实现从小到大排。
1.先对读入的每一考场的考生排序,将其排名写入结构体。
2.对所有考生排序。
3.一边算总排名一边输出。
注意点:
都写在注释里了2333
此处待补一个:
需要记录排名的写法:
将排序完的第一个个体排名记为1,遍历剩余个体,分数相等则等于上一个个体的排名,不等则排名加1
stu[0].r=1;
for(int i=1;i<num;i++){
if(stu[i].score==stu[i-1].score){
stu[i].local_rank = stu[i-1].local_rank;
}else{
stu[i].local_rank=i+1;
}
} 不需要记录排名直接输出的写法:
int r=1;
for(int i=0;i<n;i++){
if(i>0&&stu[i].score!=stu[i-1].score){
r=i+1;
}
}代码 嘤嘤嘤 (╥╯^╰╥) 码了两天。注意(num-k)
#include <cstdio>
#include <algorithm>
#include <cstring>
using namespace std;
struct Student{
char id[15];//准考证号
int score;
int local_number;//考场号
int local_rank;//考场内排名
}stu[30010];//300*100
bool cmp(Student a,Student b){
if(a.score!=b.score) return a.score>b.score;//从大到小排
else return strcmp(a.id,b.id)<0;//分数一样的按准考证号排 ,小于号就是字典序小的在前面
}
int main(){
int n,k,num=0;//n考场数,num总考生数
scanf("%d",&n);//读考场数
for(int i=1;i<=n;i++){
scanf("%d",&k);//读考场人数
for(int j=0;j<k;j++){
scanf("%s %d",stu[num].id,&stu[num].score); //注意这里结构体的写法
stu[num].local_number = i;//该考生的考场号为i
num++;
} //for循环结束后,num为总考生数 eg:5
/*再进行下一个考场2 有四个人 总共就有九个人*/
sort(stu+num-k,stu+num,cmp);
//!!!这里注意5-5=0就是本考场的开始,
/*第二个考场的时候,假设四人,开始是 9-4=5 是第二个考场的开始*/
/*开始对每一考场排名*/
stu[num-k].local_rank = 1;//注意这里 num-k才是开始,此时num是该考场人数
for(int j=num-k+1;j<num;j++){//这里不能直接等于1呀,不然下个考场就不适用啦
if(stu[j].score==stu[j-1].score){
stu[j].local_rank = stu[j-1].local_rank;//分数相同就赋一样的排名
}else{
stu[j].local_rank = j+1-(num-k);//减去(num-k)是因为后面的考场要减去前面考场的人数才是从1开始的排名
/**(num-k)对第一考场的人不影响就是0.对后面的考场,(num-k)就是减去之前考场的人数
因为都是存在stu里的,要想对每个考场得人排名的话,(num-k)才是每个考场的开始**/
}
}
}
/*现在可以输出啦*/
printf("%d\n",num);//总考生人数
/*差点忘了排一个所有考场考生的排序*/
sort(stu,stu+num,cmp);
int r = 1;
for(int i=0;i<num;i++){
if(i>0&&stu[i].score!=stu[i-1].score){
r=i+1;
}
printf("%s ",stu[i].id);
printf("%d %d %d\n",r,stu[i].local_number,stu[i].local_rank);
}
return 0;
} 
















 574
574

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









