




引言
在现代数据技术栈中,工作流编排平台是实现复杂数据管道自动化、调度和监控的核心组件。在众多开源解决方案中,Apache Airflow 和 Apache DolphinScheduler 已成为两个最引人注目的领导者。然而,它们代表了两种截然不同的设计哲学和架构范式。本报告旨在对这两个平台进行详尽的比较分析,为技术领导者、数据工程经理和解决方案架构师在选择最适合其组织需求的工具时提供一个明确、深入的决策依据。
本次分析的核心在于两大平台根本性的哲学分歧:Airflow 坚定地奉行“工作流即代码”(Workflow-as-Code)的理念,而 DolphinScheduler 则倡导“可视化优先、低代码”的方法。这一分歧不仅仅是用户界面的差异,它深刻地影响了平台的架构设计、目标用户、可扩展性模式、治理模型以及企业级功能的实现方式。
-
核心差异综述:
-
架构与可扩展性:Airflow 采用基于组件的集中式架构,其可扩展性高度依赖于所选的执行器(Executor);而 DolphinScheduler 采用原生分布式、去中心化的多 Master/多 Worker 架构,通过 ZooKeeper 实现协调,天生具备高可用性。
-
用户体验与开发模式:Airflow 是一个以开发者为中心的平台,要求用户具备 Python 编程能力,以代码形式定义、版本化和测试工作流。DolphinScheduler 则通过其强大的拖拽式图形界面,极大地降低了使用门槛,旨在实现数据管道创建的“民主化”,让数据分析师和科学家也能参与其中。
-
企业级功能:DolphinScheduler 在多租户、资源隔离和工作流版本控制等企业级功能上提供了更完善的开箱即用支持。而在 Airflow 中,实现同等级别的功能通常需要复杂的配置、自定义开发和严格的平台工程实践。
-
社区与生态系统:Airflow 拥有一个更庞大、更成熟的社区和极其丰富的第三方集成生态系统,这使其在解决问题和对接多样化服务方面具有显著优势。DolphinScheduler 的社区虽然规模较小,但增长迅速,并专注于大数据生态系统的深度集成。
-
本报告将从基础哲学、架构设计、用户体验、功能特性、企业级能力以及社区生态等多个维度展开详细论述,并最终提供一个战略性的决策框架,帮助组织根据其自身的技术栈、团队技能、治理需求和扩展目标,做出最明智的选择。
表 1:高级功能比较矩阵
| 特性/维度 | Apache Airflow | Apache DolphinScheduler |
| 核心哲学 | 工作流即代码 (Workflow-as-Code),强调编程的灵活性和可扩展性。 | 可视化优先,低代码/无代码,旨在降低使用门槛,实现数据大众化。 |
| 主要用户 | 数据工程师、具备 Python 技能的开发者。 | 数据工程师、数据分析师、数据科学家、运维人员。 |
| 核心架构 | 集中式调度器(2.x后支持多调度器),组件化设计,可插拔执行器。 | 去中心化,多 Master/多 Worker,基于 ZooKeeper 协调的原生分布式架构。 |
| 高可用性 (HA) | 通过配置冗余组件(如多调度器、多Webserver)和高可用元数据数据库实现。 | 架构原生支持,通过 ZooKeeper 实现 Master 自动故障转移和选举。 |
| 工作流定义 | 纯 Python 代码(DAG 文件),支持动态生成。 | 主要通过 Web UI 拖拽创建,同时支持 Python SDK 和 YAML 定义。 |
| 多租户 | 原生不支持,实现成本高,需通过复杂配置(如K8s Executor)或多实例部署达成。 | 原生支持,提供租户、用户、Worker 组等多层级隔离。 |
| 资源管理 | 通过资源池(Pools)限制并发,通过队列(Queues)将任务路由到特定 Worker。 | 通过 Worker 组将任务绑定到特定机器,提供更强的物理资源隔离。 |
| 社区规模 | 极其庞大且成熟,拥有海量的贡献者和第三方资源。 | 规模较小但增长迅速,尤其在亚太地区非常活跃。 |
| 生态系统广度 | 极广,拥有数百个官方和社区贡献的提供商(Providers),覆盖各类SaaS和云服务。 | 较集中,深度集成主流大数据组件(Spark, Flink, Hive等),第三方集成较少。 |
第一部分:基础哲学与核心概念
选择一个工作流编排工具,远不止是选择一系列功能,更是选择一种构建、管理和治理数据管道的哲学。Apache Airflow 和 Apache DolphinScheduler 在这一点上展现了截然不同的理念,这些理念从根本上塑造了它们的每一个方面。
A. Apache Airflow:“工作流即代码”的范式
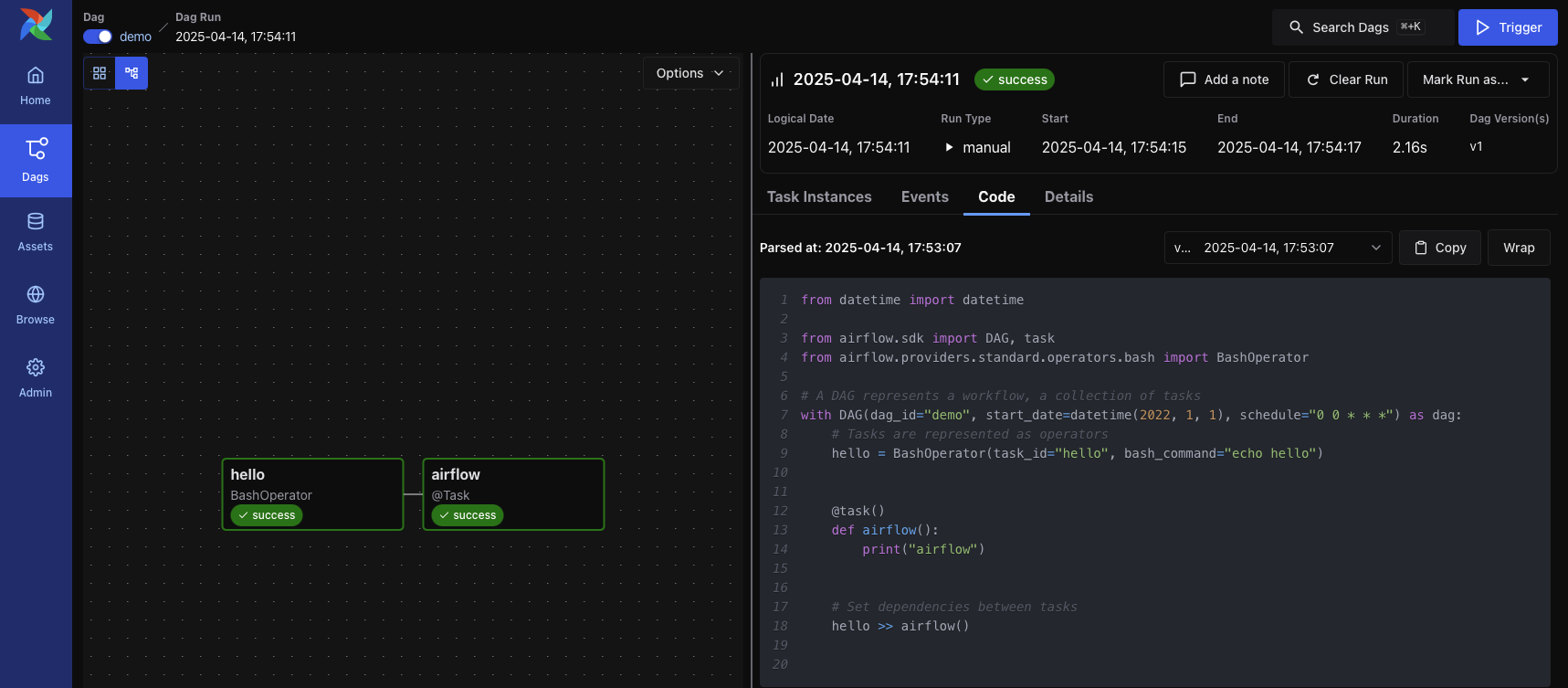
Apache Airflow 的核心身份是一个用于以编程方式创作、调度和监控工作流的平台。其最根本的信条是将数据管道定义为代码,具体来说是 Python 代码。这一原则赋予了工作流前所未有的动态性、灵活性和可维护性。开发者可以利用 Python 的全部功能,如循环、条件判断、类继承等,来动态生成复杂的任务流,这超越了静态配置文件所能达到的极限。
这种“工作流即代码”的方法带来了软件工程最佳实践在数据工程领域的应用。数据管道可以像任何其他软件一样被版本控制(例如使用 Git)、进行代码审查、编写单元测试和集成测试,从而极大地提高了数据管道的健壮性和协作效率。
在 Airflow 的世界里,核心概念紧密围绕代码展开:
-
DAG (Directed Acyclic Graph):有向无环图是 Airflow 工作流的蓝图。它是一个 Python 文件,定义了一个由任务组成的集合,以及这些任务之间的依赖关系和执行顺序。
-
Operator:算子是预定义的任务模板,封装了执行特定工作的逻辑,例如
BashOperator用于执行 Bash 命令,PythonOperator用于执行 Python 函数。它们是构成 DAG 的基本构建块,决定了“做什么”。 -
Task:任务是 Operator 在 DAG 中被实例化的一个节点。一个 Operator 类可以被多次实例化,从而在同一个 DAG 中创建多个具有不同参数的任务。
B. Apache DolphinScheduler:可视化优先、低代码的方案
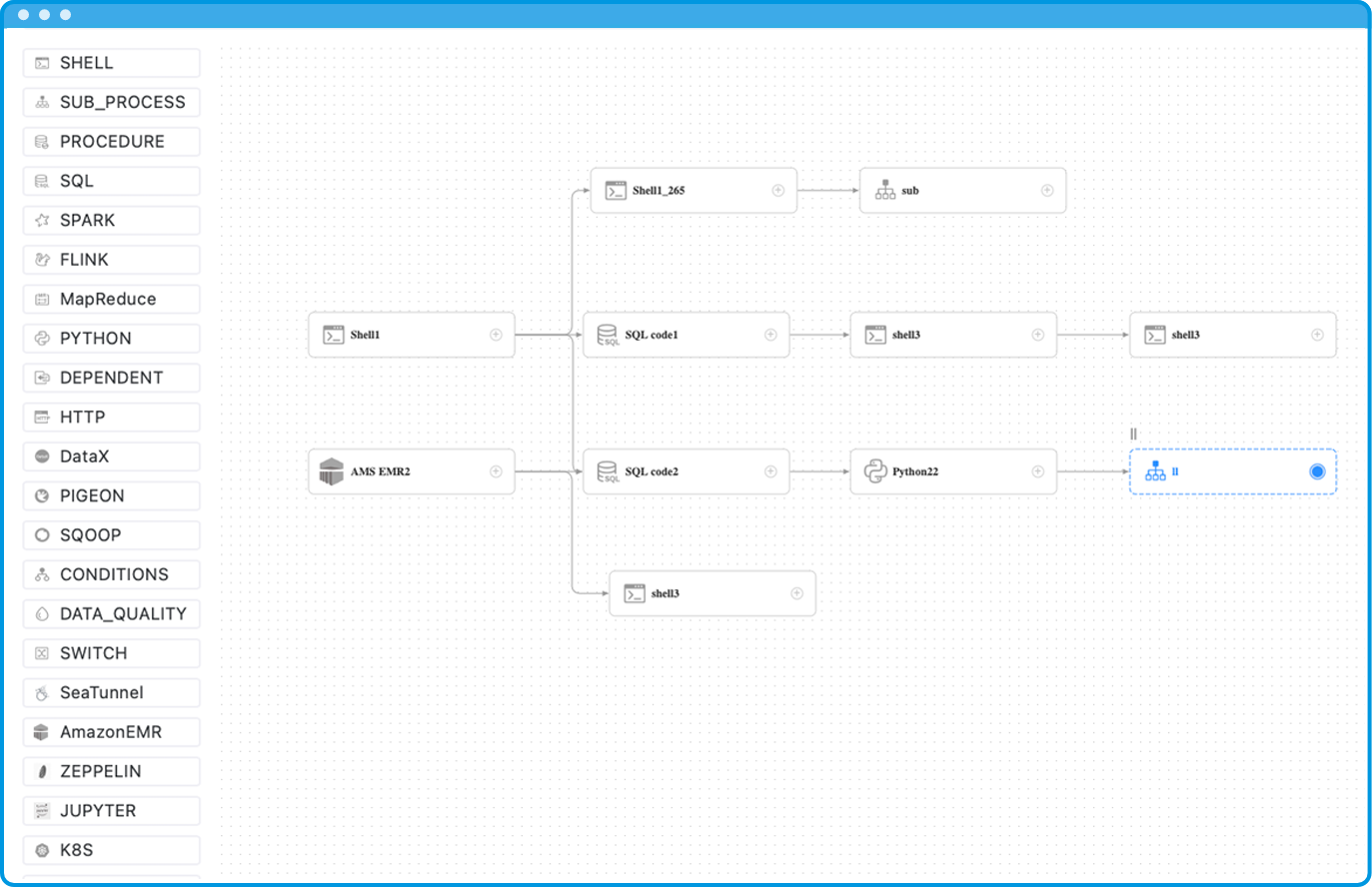
Apache DolphinScheduler 的诞生,很大程度上是对 Airflow 等代码优先工具所带来的高学习曲线和复杂性的一种回应。它的核心目标是通过提供一个强大的可视化 DAG 界面,来解决复杂的数据任务依赖问题,使得非专业开发者也能轻松上手。
DolphinScheduler 的首要交互方式是其基于 Web 的拖拽式画布。用户可以从工具面板中选择不同的任务类型(如 Shell、SQL、Spark),将它们拖到画布上,然后通过连接线来定义它们之间的依赖关系。这种方式极其直观,对于构建标准化的 ETL 流程,几乎不需要任何编码知识,从而极大地提高了效率并降低了出错的可能性。这种设计理念旨在“民主化”数据管道的创建过程,让数据分析师、数据科学家甚至业务人员都能参与到工作流的构建中来。
然而,DolphinScheduler 并非仅限于可视化操作。它深刻理解工程师对于代码控制和自动化(CI/CD)的需求,因此提供了强大的 PyDolphinScheduler Python SDK 和对 YAML 文件定义的支持。这使得开发者依然可以采用“工作流即代码”的模式,将工作流定义纳入版本控制和自动化部署流程,实现了两种模式的互补。
C. 核心抽象的比较分析
尽管两个平台都以 DAG 作为工作流的基础模型,但它们对这一核心抽象的实现和管理方式却大相径庭,这直接反映了它们的设计哲学。
-
DAG/工作流的本质:在 Airflow 中,DAG 本身就是一个 Python 对象。调度器通过扫描指定的目录,动态地发现并解析这些 Python 文件来加载 DAG。DAG 的定义和它的代码表示是同一的。而在 DolphinScheduler 中,工作流(在旧版本中称为“流程定义”)的本质是一个存储在元数据数据库中的配置实体,通常是一个 JSON 对象。这个实体可以通过多种途径创建:UI 上的可视化操作、调用 API 接口,或是通过 PyDolphinScheduler SDK 提交。这种架构上的差异意味着,Airflow 的工作流定义是“文件系统驱动”的,而 DolphinScheduler 是“数据库驱动”的。这一根本区别对系统的架构、扩展性和状态管理产生了深远影响。例如,DolphinScheduler 的 Worker 节点在执行任务时是无状态的,它们不需要访问整个 DAG 的定义文件,只需从 Master 接收具体的任务指令即可,这简化了 Worker 节点的扩展。
-
任务/算子的交互:Airflow 的生态系统以其丰富的 Ope
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 9695
9695

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











