




执行摘要
在数据成为企业命脉、人工智能(AI)成为核心竞争力的时代,选择正确的数据与AI平台已成为决定企业未来成败的关键战略决策。本文对当前市场上三家最具影响力的平台——Databricks、Snowflake和Palantir Foundry——进行了一次全面、深入的比较分析。我们的研究旨在穿透市场营销的表象,深入剖析各平台的 foundational philosophies(基本理念)、核心架构、AI能力、治理框架,为技术和战略决策者提供一份权威的、可操作的参考指南。
核心发现:
-
Databricks:开放的AI原生先锋。 Databricks源于学术界和开源社区,其核心战略是提供一个统一、开放的“湖仓一体(Lakehouse)”平台,覆盖从数据工程到尖端生成式AI的完整生命周期。其优势在于无与伦比的灵活性、对开源生态的深度整合以及为数据科学家和机器学习工程师量身打造的强大工具链(Mosaic AI)。然而,这种灵活性也带来了相对陡峭的学习曲线和更高的管理复杂性。对于那些希望构建和完全掌控自有AI模型、拥抱开源标准、并拥有强大技术团队的企业而言,Databricks是其首选。
-
Snowflake:从云数据仓库到AI数据云的转型者。 Snowflake以其革命性的“多集群共享数据”架构颠覆了云数据仓库市场,其核心优势在于极致的易用性、近乎零维护的体验和卓越的SQL查询性能。面对AI浪潮,Snowflake正积极通过Snowpark和Cortex AI将AI/ML能力引入其数据云,旨在将AI工作负载吸引到其庞大的数据引力中心。其战略是降低AI应用的门槛,使广大的数据分析师和商业智能(BI)用户也能轻松利用AI。对于那些以BI和分析为核心、希望在现有数据基础上渐进式引入AI能力、并看重平台易用性和管理简便性的企业,Snowflake展现出强大的吸引力。
-
Palantir Foundry:面向决策的终极操作系统。 Palantir的出身决定了其独特的定位——它并非一个单纯的数据工具,而是一个为复杂运营场景设计的“决策操作系统”。其核心是“本体(Ontology)”,一个将企业所有数据、逻辑和行动映射为现实世界数字孪生的语义层。Palantir的强项在于处理复杂、异构的数据,并将分析结果与实际业务流程深度绑定,实现“人机协同”下的实时决策。其AI平台(AIP)旨在将AI智能体安全地嵌入到运营流程中。然而,这种强大的能力伴随着高昂的成本、封闭的生态系统和深刻的组织变革需求。对于那些面临高风险、复杂决策环境,追求运营效率极致优化,并愿意进行重大战略投资的大型企业和政府机构,Palantir Foundry提供了无可替代的价值。
战略建议:
选择哪个平台并非一个简单的技术问题,而是一个与企业文化、人才结构、战略目标和财务模型深度绑定的决策。
-
技术驱动型和AI原生型组织应优先考虑Databricks,以最大化其技术自由度和创新速度。
-
业务驱动型和分析成熟型组织应优先考虑Snowflake,以利用其数据资产并快速赋能业务团队。
-
运营驱动型和面临复杂决策挑战的组织应优先考虑Palantir Foundry,以实现数据、分析与运营的闭环,重塑核心业务流程。
本报告将逐一解构这三大平台的方方面面,为您的关键决策提供坚实的数据与洞察支持。
I. 基本理念与战略要务
要真正理解Databricks、Snowflake和Palantir Foundry之间的差异,必须追溯它们的起源。公司的“企业DNA”并非仅仅是历史背景,而是决定其当前架构、市场策略和核心价值主张的根本性因素。它们各自的创始理念塑造了它们今天的战略要务,并预示了它们未来的发展轨迹。
Databricks:开源的AI原生先锋
-
核心身份: Databricks自我定位为“数据与AI公司”,这直接反映了其深厚的学术和开源背景。公司于2013年由Apache Spark™、Delta Lake、MLflow和Unity Catalog的原创者们创立,其整个哲学构建于一个核心信念之上:在一个开放的架构上统一数据与AI。
-
战略要务: Databricks的首要战略任务是提供一个单一、开放的平台,以避免供应商锁定,并服务于从数据工程到最前沿AI/ML应用的完整数据生命周期。他们的目标是成为数据科学家和机器学习工程师的默认平台,这些人要求极高的灵活性、控制权以及对最新开源创新的无缝访问。公司对MosaicML的收购以及自主研发DBRX这样的顶级开源大语言模型,清晰地表明了其引领生成式AI时代的雄心——不仅提供工具,更提供核心模型。
-
证据支撑: 公司的历史深深植根于加州大学伯克利分校的AMPLab实验室,其最初的愿景就是通过商业化并改进Apache Spark,来“主导大数据平台领域”。Databricks持续不断地为Spark、Delta Lake和MLflow等关键开源项目做出重大贡献,这不仅是其技术实力的体现,更是其核心价值主张的基石。
Snowflake:从云数据仓库到AI数据云的转型者
-
核心身份: Snowflake的起点非常明确——创建一个“为云而生的数据仓库”。公司于2012年由来自Oracle的三位数据仓库专家创立,他们最初的天才之处在于彻底颠覆了传统数仓的架构,利用云的弹性,从根本上分离了存储与计算。这一创新催生了一个“即插即用”、几乎无需维护的革命性产品。
-
战略要务: 在主导了云数据仓库市场之后,Snowflake当前的核心战略要务是避免被商品化。它必须进化,超越一个单纯的高性能SQL引擎。将品牌升级为“AI数据云”,并大力投入研发Cortex AI和Snowpark,代表了一次关键的战略转型:将AI/ML工作负载吸引到其数据之上。其目标是捕获利润丰厚的AI预算,防止客户为了进行机器学习而将数据迁移到像Databricks这样的平台。
-
证据支撑: 创始人的愿景是克服传统本地部署和第一代云数据平台的局限性。其巨大的成功体现在庞大的客户基数(超过11,578家)和惊人的日均查询量(63亿次)。近期,Snowflake正积极向联邦政府等新市场和特定行业(如旅游、医疗)扩张,这表明其在核心业务之外寻求持续增长的强烈动力。
Palantir:面向决策的终极操作系统
-
核心身份: Palantir从根本上说是一家软件公司,它构建的是用于支持“运营决策”的“数据融合平台”,而不仅仅是用于分析。它的起源是为美国情报界(USIC)和国防部(DoD)等高风险、高保密性机构服务,这就要求其平台必须为处理高度复杂、模糊且常常是非结构化的数据环境而设计。
-
战略要务: 成为现代企业的“操作系统”。Palantir的焦点并非为数据团队提供孤立的工具,而是创建一个企业的整体“数字孪生”——即“本体”(Ontology)。这个本体将数据、分析和业务运营连接成一个单一的、可操作的框架。公司向商业领域的扩张,本质上是将这种在情报界千锤百炼的方法论,应用于解决复杂的商业问题,如供应链优化和智能制造。
-
证据支撑: 公司的核心产品,Gotham(面向政府)和Foundry(面向商业),其设计初衷就是为了“识别隐藏在数据集深处的模式”,并“促进分析师与操作员之间的无缝交接”。其客户案例反复强调的是运营成果——节省成本、提高效率、优化流程——而非纯粹的分析成就。
核心洞察与启示
分析这三家公司的基本理念揭示了两个深刻的战略现实。
首先,企业DNA决定了战略命运。每家公司的创始理念是预测其优势和劣势的最强指标。
-
Databricks的开源DNA决定了它的灵活性和对技术人员的吸引力。它诞生于Spark创造者之手,而Spark是一个开源的、代码优先的框架。因此,Databricks的平台天然地服务于那些习惯于代码、重视开放标准的开发者和数据科学家。这是它的核心优势。反之,这也为非技术用户制造了“陡峭的学习曲线”,这是其DNA的直接产物。
-
Snowflake的“简化”DNA决定了它的易用性和对BI分析师的巨大吸引力。其创始人来自Oracle,深知管理传统数仓的痛苦。因此,他们构建了一个将所有复杂性都抽象掉的平台,实现了“近乎零维护”。这是它的核心优势。其代价是,平台提供的细粒度控制较少,并且最初在编程和ML工作负载方面能力较弱,这也是他们现在通过Snowpark和Cortex奋力弥补的短板。
-
Palantir的“任务关键”DNA决定了它对运营成果的执着和自上而下的销售模式。它由CIA的风险投资部门资助,旨在解决复杂的情报问题。因此,它的平台围绕着对现实世界实体和关系的建模(即本体)来构建,以支持决策,而不仅仅是查询。这是它独特的、难以复制的优势。其代价是,这是一个高度“固执己见”、极其复杂且昂贵的平台。它不是一个可以轻易采纳的“工具”,而是一项需要深刻组织变革的企业级实施方案。
其次,三方正在争夺企业的“数据与AI引力中心”。所有三家公司都渴望成为企业数据和AI战略的核心枢纽,但它们的路径截然不同。
-
Snowflake希望利用其在数据仓库领域建立的强大数据引力,将新兴的AI工作负载拉入其生态系统。其市场宣传反复强调将工作负载“直接带到数据上”,以“消除孤岛式开发”,这是一种防御性策略,旨在将数据和预算保留在自己的平台内。
-
Databricks则利用其在AI和ML领域的引力,试图将数据从传统的、孤立的数仓中拉出,汇入其统一的湖仓一体架构中。它所倡导的“湖仓一体(Lakehouse)”架构,本身就是一种进攻性战略,旨在统一数据范式,挑战Snowflake等封闭数仓的地位。
-
Palantir的策略则更为激进,它试图通过在其所有源系统之上创建一个本体论层,从而使数据的物理位置变得无关紧要。其平台拥有超过200个数据连接器,并能使用“虚拟表”等技术访问数据而无需移动数据。这是一种抽象化战略,无论数据身在何处,Palantir都力图成为观察、理解和操作数据的唯一“单一窗格”。
这场竞争的本质揭示了一个根本性的冲突:Snowflake和Databricks在争论数据应该“在哪里存储和处理”,而Palantir则在争论它应该是“如何被理解和操作”的唯一渠道,无论数据位于何处。这个差异对企业的长期技术选型、风险管理和战略自主性具有深远影响。
II. 架构对决:三大蓝图的解构
本章节将从哲学理念转向技术实现,对每个平台的核心架构进行一次彻底的技术解构。这三大平台的设计蓝图不仅反映了它们的创始理念,也直接决定了它们的功能、性能、成本和适用场景。
Databricks湖仓一体(Lakehouse):开放与统一的典范
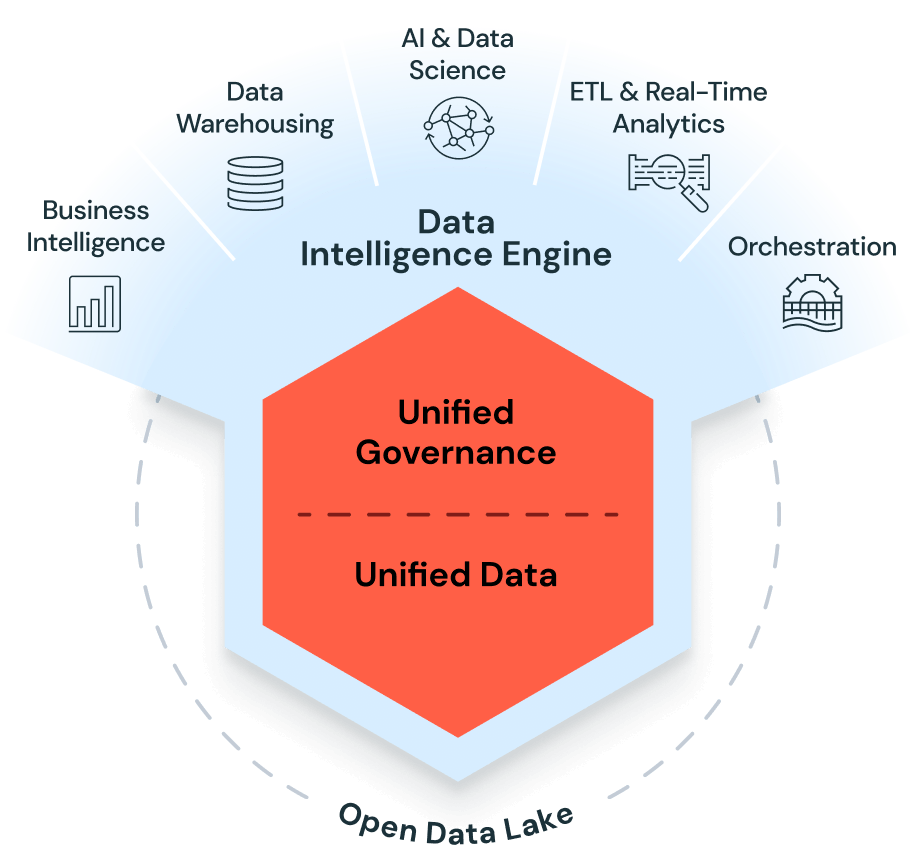
-
核心架构: Databricks构建在一个开放的湖仓一体(Lakehouse)架构之上。该架构旨在融合数据湖(Data Lake)的低成本、高灵活性存储(利用AWS S3、Azure ADLS、Google GCS等云对象存储)与数据仓库(Data Warehouse)的高性能和治理功能。
-
关键组件:
-
Delta Lake: 这是湖仓一体架构的基石。作为一个开源存储层,Delta Lake为存储在云对象存储上的数据带来了ACID事务、模式强制(Schema Enforcement)和时间旅行(数据版本控制)等关键能力。它有效地将原始的、不可靠的数据湖文件(如Parquet格式)转变为可靠、可查询的表,这是在开放
-
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 426
426

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











