 Spark读取HDFS加密区数据乱码解决方案
Spark读取HDFS加密区数据乱码解决方案





 本文介绍了在启用HDFS加密区后,遇到Spark读取数据出现乱码的问题。经过排查,发现原因是项目依赖的Hadoop版本过低(2.0),而Hadoop从2.6版本开始支持加密区。更新Hadoop依赖至2.6以上版本,即可解决乱码问题。同时,若通过hdfs://地址:端口方式指定路径,需要配置`dfs.encryption.key.provider.uri`。
本文介绍了在启用HDFS加密区后,遇到Spark读取数据出现乱码的问题。经过排查,发现原因是项目依赖的Hadoop版本过低(2.0),而Hadoop从2.6版本开始支持加密区。更新Hadoop依赖至2.6以上版本,即可解决乱码问题。同时,若通过hdfs://地址:端口方式指定路径,需要配置`dfs.encryption.key.provider.uri`。
因为项目需求,需要启用hdfs加密区,为了验证对现有程序的影响,我在自己的集群上配置了加密区,并测试spark和java程序读取数据。
spark程序代码如下
System.setProperty("HADOOP_USER_NAME", "user1")
val spark = SparkSession
.builder()
.master("local")
.getOrCreate()
// val data = spark.read.text("/user1/a.txt")
val data = spark.read.text("/user/user1/a.txt")
data.show()
一开始我读取到的是乱码,
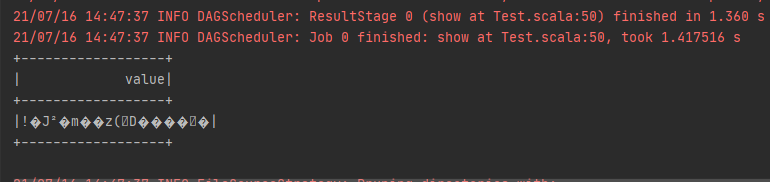
网上关于java和spark读取hdfs加密区数据的资料极少,基本都是在讲解hdfs加密区实现原理,或者使用命令行进行操作,而且都模糊的说道支持Hadoop客户端透明读写数据。我在网上搜索很久仅在一篇文章中找到明确说明spark程序无需任何更改即可读写加密区数据,因此我以为spark需要进行特殊配置或者更改代码。
后来无意中新建了一个项目,把代码拷过来,发现能正常读取数据。
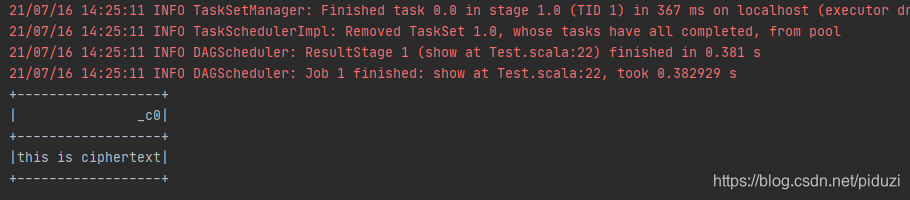
仔细排查之后才发现是依赖的问题。
我在pom中添加了spark 2.3.0,以为会传递依赖到hadoop2.6.0。但是实际上因为我还添加了hbase1.2.6,最终maven引用的是had
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 631
631

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









