






目录
分析框架:
数据读取:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from datetime import datetime
%matplotlib inline
#绘图风格,选用的是R语言绘图库风格
plt.style.use('ggplot')
# user_id:用户ID,order_dt:购买日期,order_products:购买产品数量,order_amount:购买金额
data = pd.read_table('CDNOW_master.txt',sep='\s+',header=None,names=['user_id','order_dt','order_products','order_amount'])
data.head(10)
data.describe()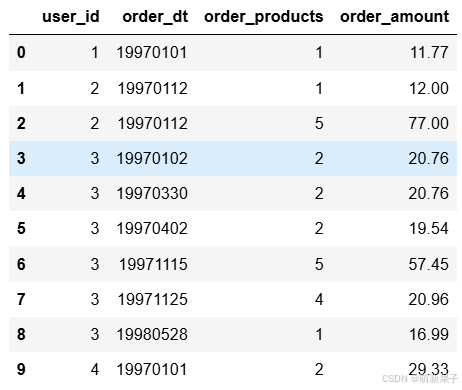
可以从数据中看出,存在同一个用户多次购买该产品记录,同时日期格式存在问题,需要手动转换
进行数据描述后,可以看出购买产品数量最小为1,但是购买金额最小却是0,可能数据集存在问题或者刷单/免费赠送情况。同时,绝大部分订单的购买产品数量都不大,多为1-3之间,存在大客户(购买99个产品)。绝大部分订单消费金额在10-50之间。
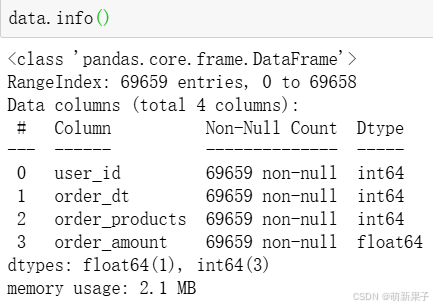
可以看出,数据集一共近七万条,且没有缺失值。时间类型需要把Int转换。
数据处理:
#转换数据类型
data['order_date'] = pd.to_datetime(data['order_dt'],format='%Y%m%d')
#format按照指定格式
#%Y:1994 %m:两位月份 %d两位日数 %y:两位年份94 %h:两位小时 %M:两位分钟 %s:两位秒
#datetime64[M] 表示将日期数据转换为“年月”格式,即只保留年份和月份,而忽略具体的日期。
data['month'] = data['order_date'].astype('datetime64[M]') #[M]:控制转换后精度
data.head()
增加一列仅精确到月份的,便于后续针对月用户活动数据进行分析。
数据分析:
用户整体消费分析
#按月份统计产品购买数量,消费金额,次数,人数
#消费趋势分析
plt.figure(figsize=(20,15),dpi=100)
#每月产品购买数量
plt.subplot(221) #两行两列占据第一个位置
data.groupby(by='month')['order_products'].sum().plot() #默认折线图
plt.title('每月产品购买数量')
#每月消费金额
plt.subplot(222) #两行两列占据第一个位置
data.groupby(by='month')['order_amount'].sum().plot() #默认折线图
plt.title('每月产品售出金额')
#每月消费次数
plt.subplot(223) #两行两列占据第一个位置
data.groupby(by='month')['user_id'].count().plot() #默认折线图
plt.title('每月用户消费次数')
#每月消费人数
plt.subplot(224) #两行两列占据第一个位置
data.groupby(by='month')['user_id'].apply(lambda x:len(x.drop_duplicates())).plot() #默认折线图
plt.title('每月消费人数')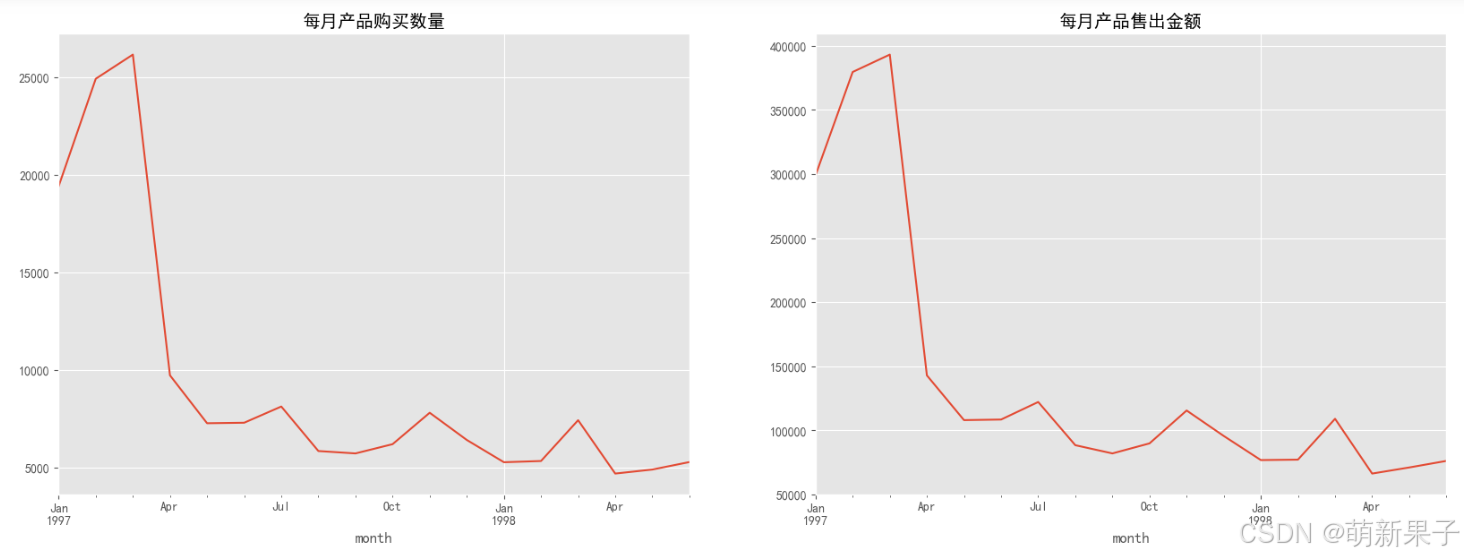
我们可以从图上一和图二看出产品售出呈现下降趋势
1997年1-3月销量高,后面销量下降并保持稳定,说明用户粘性不足;
需要结合业务分析原因(例如春节前后影响,公司销售策略影响,政策影响等)
从图三图四可以看出,二月份消费人数增多时,消费次数却减少,有可能出现大订单。
前三个月的消费订单数在10000笔左右,后续月份的平均消费订单数则在2500笔;
前三个月每月的消费人数在8000-10000之间,后续月份平均消费人数在2000人。
用户个体消费分析
用户分组进行消费描述性统计
user_group = data.groupby(by='user_id').sum()
print(user_group.describe())
print('用户数量:',len(user_group))
可以观察到,消费人数共有23570名用户购买该CD。
消费数量平均购买7个CD,但是中位数为3,且最大值为1033,表现为右偏分布。
消费金额平均为106,中位数为43,且存在消费高的用户,平均数与75%分位数相近,属于右偏分布。
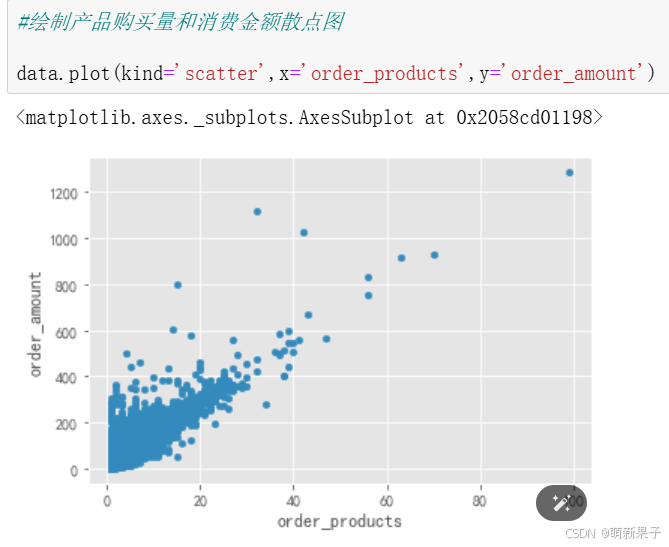 dui
dui
可以看出,用户消费金额与购买量呈线性关系,斜率为CD单价,约15左右
极值点较少,可忽略不计,对样本影响不大。
直方图观察消费分布情况
#绘制直方图,观察消费分布情况
plt.figure(figsize=(10,3),dpi=100)
plt.subplot(121)
plt.xlabel('每个订单消费金额')
#bins:区间分数,影响柱子宽度。宽度=(最大值-最小值)/bins
data['order_amount'].plot(kind='hist',bins=60)
plt.subplot(122)
plt.xlabel('每个uid购买数量')
data.groupby(by='user_id')['order_products'].sum().plot(kind='hist',bins=60)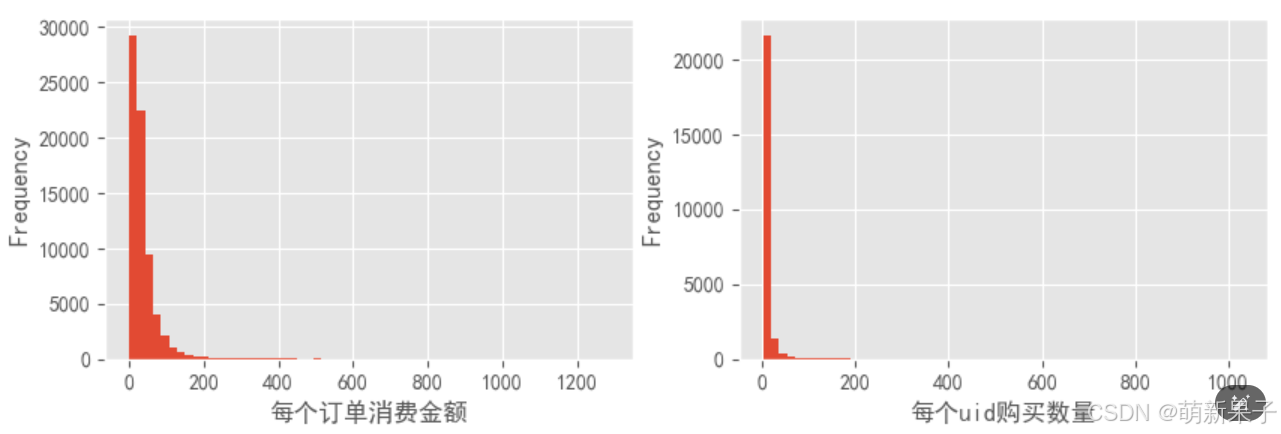
可以看出,订单消费金额大部分在100以内,单个用户购买数量较小,为50以内。
用户画像主要为消费金额低,购买小于50个产品的用户人数占大多数,这在电商行业较为普遍。
用户累计消费金额占比分析(贡献度)
#用户分组,汇总消费金额,排序,重置索引
user_cumsum = data.groupby(by='user_id')['order_amount'].sum().sort_values().reset_index()
user_cumsum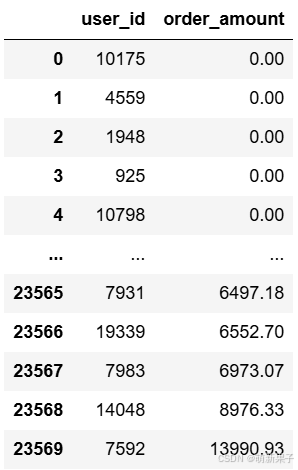
#用户消费金额累加,累加函数 cumsum
#这样算贡献率为要算的用户范围直接除以最后一行的总和就好了
user_cumsum['amount_cumsum'] = user_cumsum['order_amount'].cumsum()
user_cumsum.tail()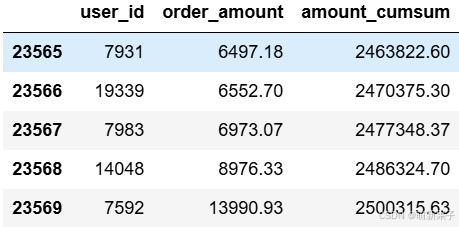
amount_total = user_cumsum['amount_cumsum'].max()#消费总额
#计算贡献度
#axis=0 或 'index':对每一列应用函数(默认)。axis=1 或 'columns':对每一行应用函数。
user_cumsum['prop'] = user_cumsum.apply(lambda x:x['amount_cumsum']/amount_total,axis=1)
user_cumsum.tail()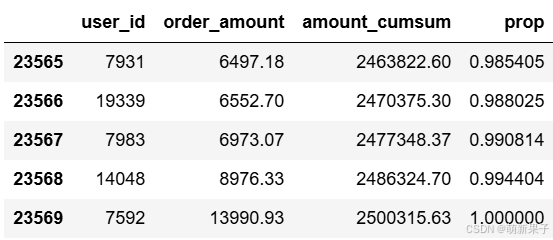
prop列表示的是截止到该用户,所购买产品金额的贡献度
user_cumsum['prop'].plot()
plt.xlabel('用户数量')
plt.ylabel('贡献度')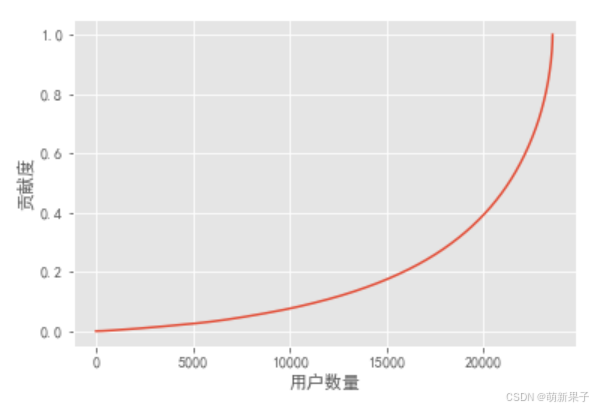
我们可以看到,两万名用户贡献了百分之四十的销量,三千多名用户贡献了百分之六十的销量。这也体现了二八法则。
用户消费行为
首购时间
用户分组,选择最早购买时间,计算一天有多少新用户
data.groupby(by='user_id')['order_date'].min().value_counts().plot()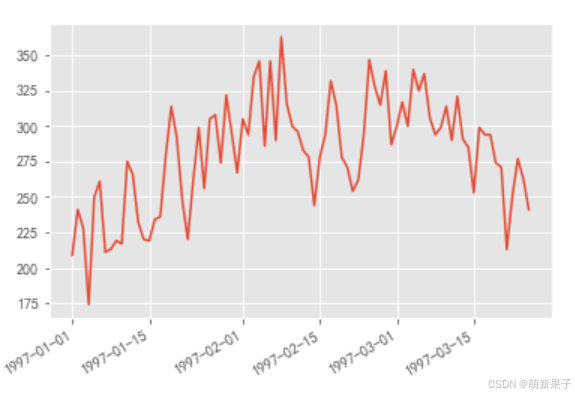
从图中可以看出,新用户的变化从1.1-2.1呈现明显递增趋势,说明公司可能有价格的变化和促销活动的开展,而2.1后新用户增加总体呈现递减趋势。
最后一次购买时间
data.groupby(by='user_id')['order_date'].max().value_counts().plot()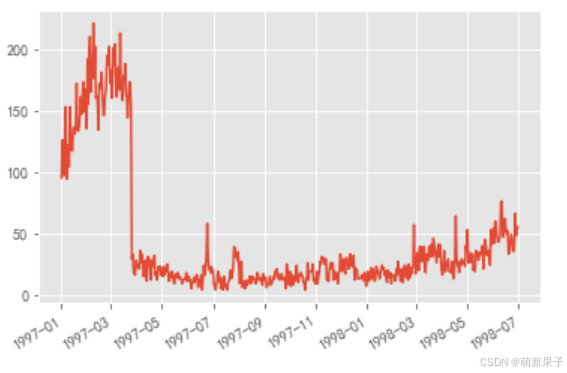
大多数用户最后购买时间集中在前三个月,,说明缺少忠诚用户。1997年5月用户最后购买次数急剧减少,说明很多用户在此时 停止复购,CD 公司的客户保持率较低。
用户分层
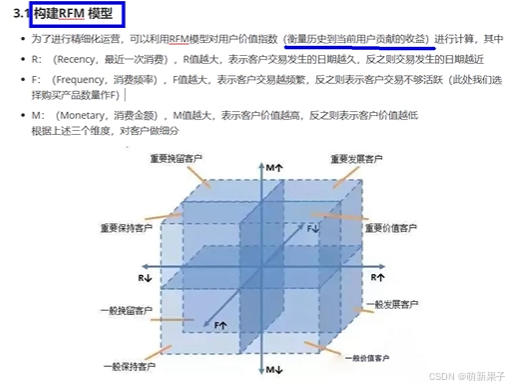
透视表:可动态直观显示汇总结果。(pivot_table)(报表神器)
#透视表(index:相当于group分组,values指取出的列,aggfunc指对于列的处理方法,聚合函数必须有效)
rfm = data.pivot_table(index='user_id',
values=['order_products','order_amount','order_date'],
aggfunc={
'order_date':'max',#最后一次购买时间
'order_products':'sum',#购买数量总和
'order_amount':'sum'#消费总金额
})
rfm.head()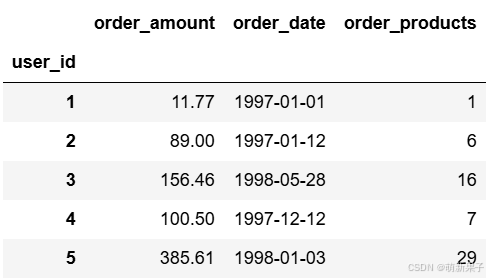
#最近一次消费离现在时间差,转换精度,精确到天(保留一位小数)
rfm['R'] = (rfm['order_date'].max() - rfm['order_date'])/np.timedelta64(1,'D')
rfm.rename(columns={'order_products':'F','order_amount':'M'},inplace=True)
rfm.head()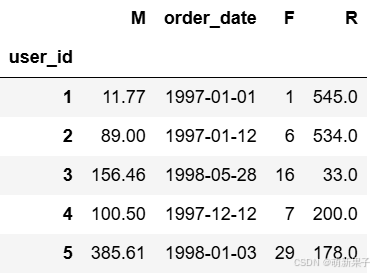
RFM计算:每一列数据减去数据所在列平均值,有正有负,结果与1比较,结果>=1,设置为1,否则为0,把每条记录转换为特定代码(例:110,001,010,100……)
#定义函数,转为字符串
def rfm_func(x):
level = x.apply(lambda x:'1' if x>=1 else '0' )
label = level['R'] + level['F'] + level['M']#字符串拼接
d = {
'111':'重要价值客户',
'011':'重要保持客户',
'101':'重要发展客户',
'001':'重要挽留客户',
'010':'一般保持客户',
'000':'一般挽留客户',
'110':'一般价值客户',
'100':'一般发展客户'
}
result = d[label]
return result
#每一列数据减去数据所在列平均值
rfm['label'] = rfm[['R','F','M']].apply(lambda x:x-x.mean()).apply(rfm_func,axis=1)
rfm.head()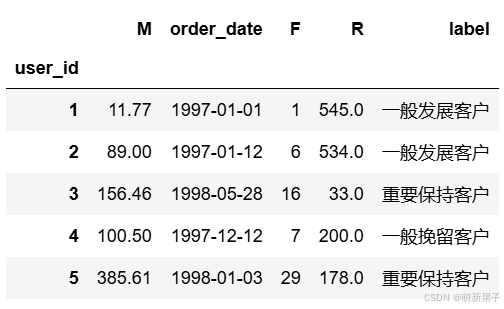
#客户分层可视化
for label,grouped in rfm.groupby(by='label'):
print(label,grouped)
x = grouped['F']
y = grouped['R']
plt.scatter(x,y,label = label)
plt.legend() #显示图例
plt.xlabel('Frequency')
plt.ylabel('Recenttime')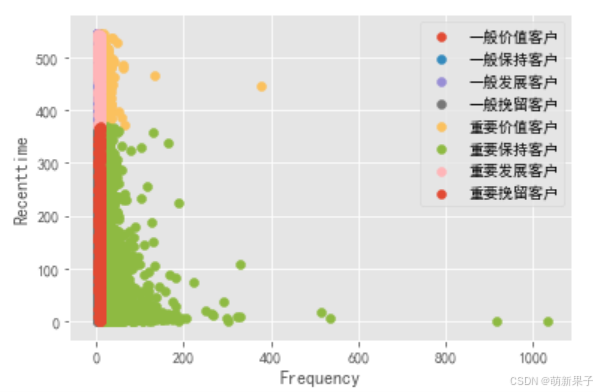
从图中可以看出,R较小,F、M较大,这是公司喜欢的用户,表示产品售卖的不错。
新老用户分析
首先进行用户分层处理,用透视表的形式
#用户分层数据
pivoted_counts = data.pivot_table(
index='user_id',
columns='month',#视表的列将基于 month 列的值。
values='order_dt',
aggfunc='count'
).fillna(0)#将没有消费记录补为0
pivoted_counts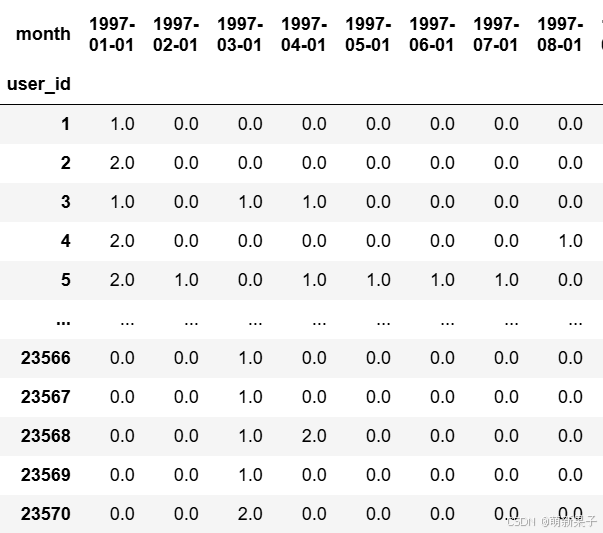
浮点数不好观察,把他转换为1和0
df_purchase = pivoted_counts.applymap(lambda x:'1' if x>0 else 0)
#apply:作用于用户dataframe数据中的一行或一列数据
#applymap:作用于dataframe数据的每一个元素
#map:series函数,在dataframe中无法使用map函数,其作用于series中每个元素
df_purchase.head()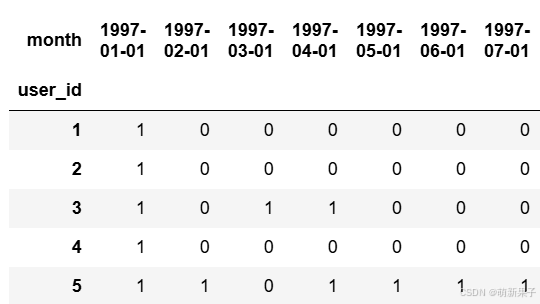
判断新老用户,活跃用户,回流用户
def active_status(data):#data为整行数据,共18列
status = []#存储18个月的状态:unreg\new\active\unactive\return
for i in range(18):
#本月无消费
if data[i] == 0:
if len(status) == 0:#前面无记录(97年1月)
status.append('unreg')
else:#判断上个月状态
if status[i-1] == 'unreg':
status.append('unreg')
else:
status.append('unactive')#无论上个月是否消费过,本月无消费,均为不活跃
pass
#本月有消费
else:
if len(status) == 0:
status.append('new')#第一次消费
else:
if status[i-1] == 'unactive':
status.append('return')
elif status[i-1] == 'unreg':
status.append('new')
else:
status.append('active')
return pd.Series(status,df_purchase.columns)#值为status,列名为df_purchase的列名,pd.series指对行进行操作
purchase_states = df_purchase.apply(active_status,axis=1)
purchase_states.head()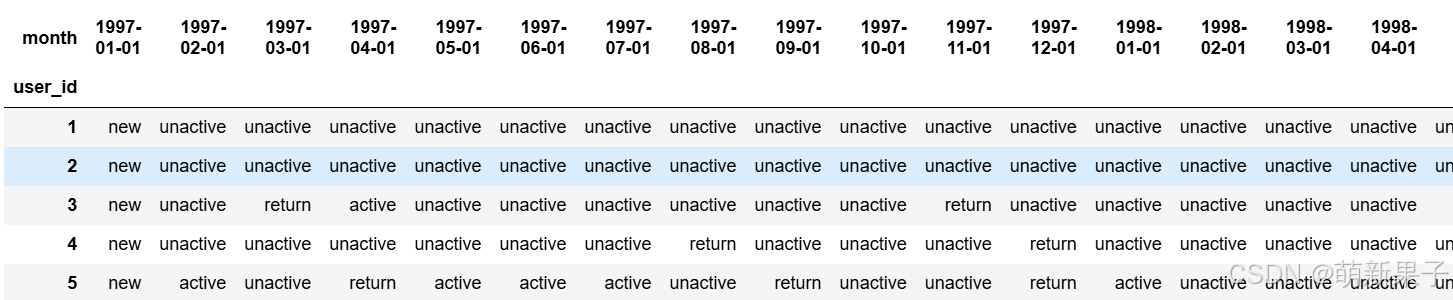
#分析各类用户占比情况,用NaN空值替换unreg(没必要分析)
purchase_states_ct = purchase_states.replace('unreg',np.NaN).apply(lambda x:pd.value_counts(x))
purchase_states_ct.head()
可视化:
#数据可视化,把空值补为0
#将数据进行转置
purchase_states_ct.T.fillna(0).plot.area()
#面积图是一种展示数据随时间变化的图表,通常用于显示数量的变化和组成部分的比例。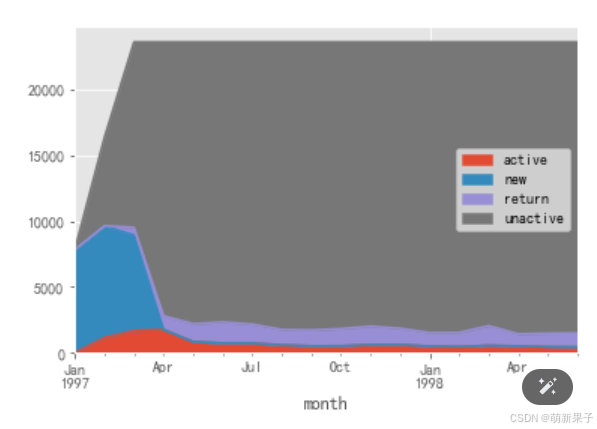
可以看出,新用户在1-4月大量注册,并较为活跃,4月后趋于稳定;
4月之后,回流用户较为稳定,是网站重点客户。
#用户占比(例:return/该月总消费人数)
rate = purchase_states_ct.T.fillna(0).apply(lambda x: x/x.sum(),axis=1)
plt.plot(rate['return'],label='return')
plt.plot(rate['active'],label='active')
#plt.plot(rate['unactive'],label='unactive')
plt.legend()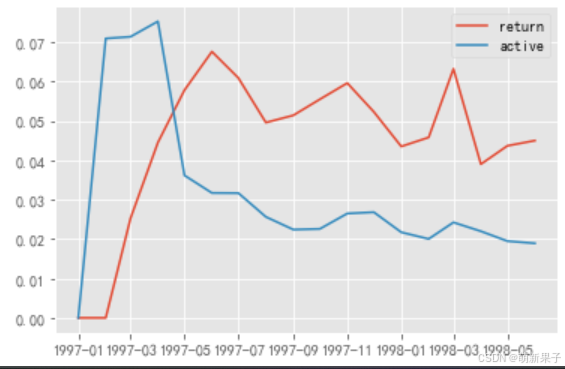
从图中可以看出,从2月开始,回流用户逐渐增加,到六月份开始逐步保持稳定,平均维持在5%的比例;
活跃用户从1-2月增加趋势较大(猜测活动营销吸引新用户),4月开始极速下降至5月,随后趋于平稳下降趋势,平均占比2.5%左右。
用户购买周期
相邻两次购买产品的时间间隔
#shift函数:可把数据移动到指定位置(整体向左\右\上下移一行\列)
#计算购买周期(购买日期时间差)
order_diff = data.groupby(by='user_id').apply(lambda x: x['order_date']-x['order_date'].shift())#当前订单日期-上次订单日期
order_diff.describe()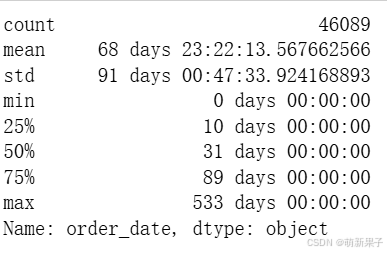
可视化:
#数据可视化周期
(order_diff/np.timedelta64(1,'D')).hist(bins=15)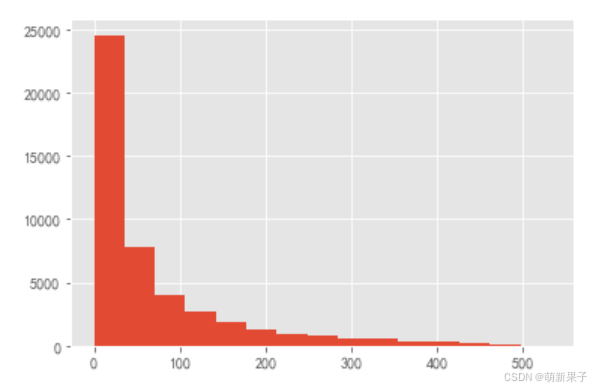
从图中可以看出,平均消费周期为68天,大部分用户消费周期少于100天;
图像呈现长尾分布,大部分用户消费周期较短,少部分为不积极用户;针对消费频率低的用户,运营部门可以在这批用户消费3天后进行电话回访,或赠送优惠券等活动,增大消费频率。
用户生命周期
第一次消费与最后一次消费的差值
#agg函数:以对数据进行汇总操作,例如计算均值、总和、最大值、最小值等。
user_life = data.groupby(by='user_id')['order_date'].agg(['min','max'])
(user_life['max']==user_life['min']).value_counts().plot.pie(autopct='%1.1f%%')#仅消费一次,保留一位小数
plt.legend(['仅消费一次','多次消费'])
plt.title('用户消费比例')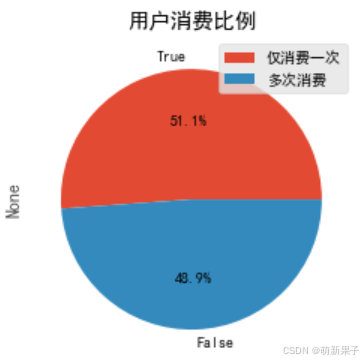
从图中看出,一半以上用户仅消费一次,说明运营情况存在问题,留存率较差,用户粘性低。
#生命周期
(user_life['max']-user_life['min']).describe()
可以看出,四分位数一直到75%才为294天,可知大部分用户只购买一次产品;
75%分位数之后的用户为核心用户,需要重点维持。
绘制所有用户生命周期直方图和多次购买产品的用户直方图
plt.figure(figsize=(12,6))
plt.subplot(121)
((user_life['max']-user_life['min'])/np.timedelta64(1,'D')).hist(bins=15)
plt.title('用户生命周期')
plt.xlabel('天数')
plt.ylabel('用户人数')
plt.subplot(122)
u_1 = (user_life['max']-user_life['min']).reset_index()[0]/np.timedelta64(1,'D')#加索引取天数列,转换为天数数值类型
u_1[u_1>0].hist(bins=15)
plt.title('多消费用户生命周期')
plt.xlabel('天数')
plt.ylabel('用户人数')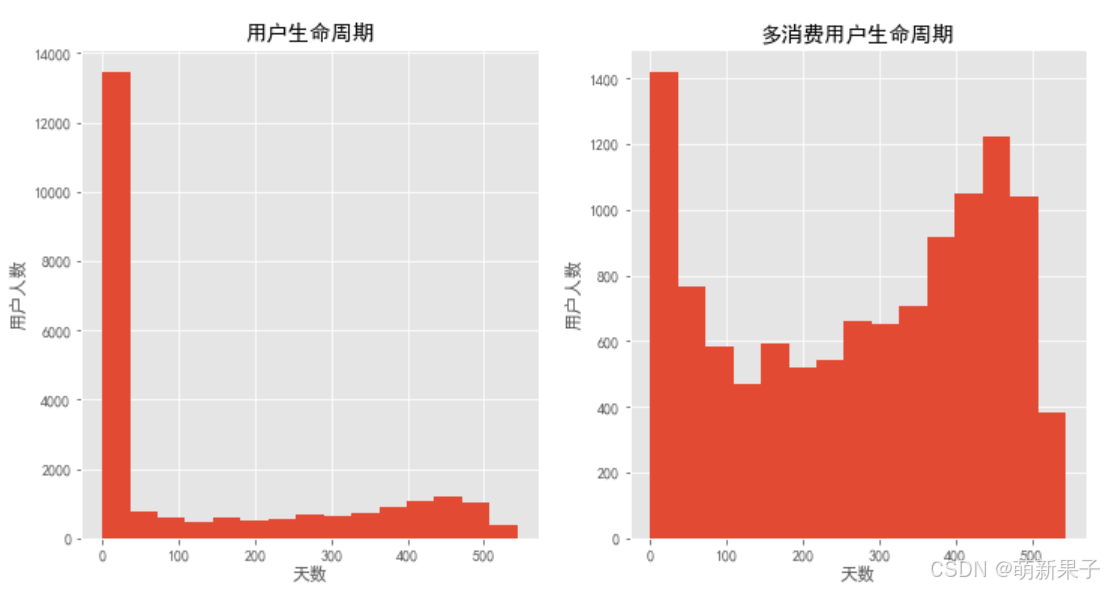
从图中可以看出,在多次消费用户的群体中,生命周期小于100天的可以归结为普通用户,忠诚度低;生命周期大于300天的用户作为忠诚用户,需重点维护。
用户复购率
每个月用户购买次数>1为复购用户
复购率为复购用户/普通消费用户(购买次数=1)
因此,将用户本月购买次数为0的设置为NaN(以免干扰count计数)
purchase_r = pivoted_counts.applymap(lambda x:1 if x>1 else np.NaN if x==0 else 0)
#purchase_r.sum() 复购用户
#purchase_r.count() 消费总人数(无NaN)
(purchase_r.sum()/purchase_r.count()).plot(figsize=(12,6))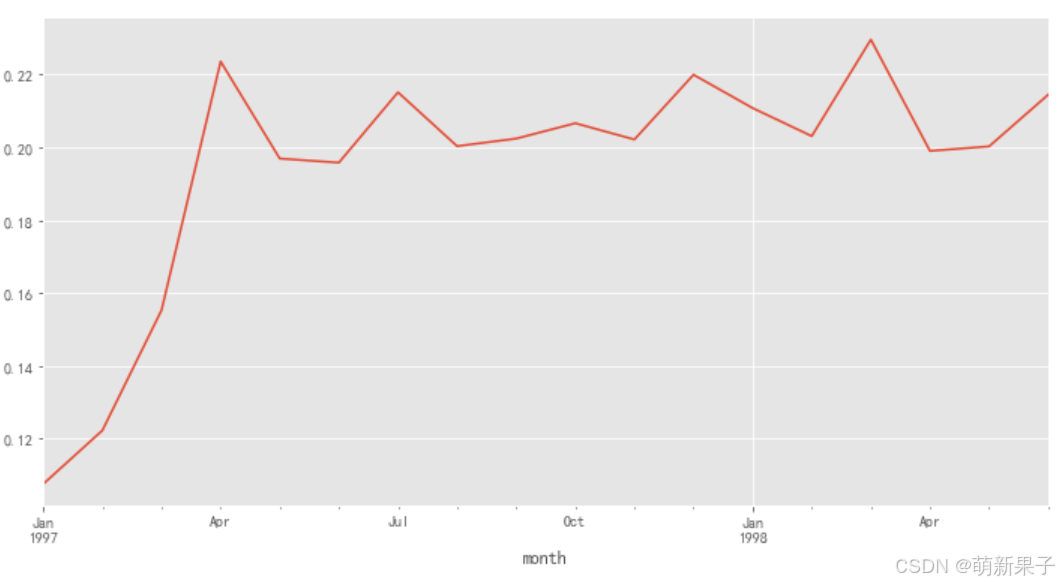
从图中可以看出,复购率从一至四月上涨率较快,然后趋于平稳,维持在20%-22%。
用户回购率
def purchase_back(data):
status = []#存储用户回购率状态
#1:回购用户 0:非回购用户(当前月消费,下月未消费) NaN:(当前月下月均未消费)
for i in range(17):
#当前月份消费
if data[i] == 1:
if data[i+1] == 1:
status.append(1)
elif data[i+1] == 0:
status.append(0)
else:
status.append(np.NaN)
status.append(np.NaN)#填充最后一列数据
return pd.Series(status,df_purchase.columns)
purchase_b = df_purchase.apply(purchase_back,axis=1)
purchase_b.head()
(purchase_b.sum()/purchase_b.count()).plot(label='回购率')
从图中可以看出,复购率低于回购率,前三个月逐渐上升,后面趋于稳定。
总结
该项目主要针对用户消费行为进行分析,分别从整体趋势,个体特征,消费额,消费周期等方面进行拆分。主要运用到以下方法:
1.针对用户按照月份提取进行整体个体分析,分析维度为人数,消费金额和购买量;
2.消费分析:首购时间,最后一次购买时间,相邻两个购物时间间隔,用户分层(RFM+数据透视表pivoted),分析维度为新、活跃、不活跃用户流失分析,回流用户分析;
3.复购率和回购率分析。
注:此文章为学习笔记记录

















 809
809

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









