







 本文介绍了SQL作为声明性语言的特点,以及数据库管理系统(DBMS)如何通过优化器来确定最佳的查询执行计划。文章还深入探讨了PostgreSQL如何利用统计信息评估不同执行计划的成本,并最终选择最高效的一个。
本文介绍了SQL作为声明性语言的特点,以及数据库管理系统(DBMS)如何通过优化器来确定最佳的查询执行计划。文章还深入探讨了PostgreSQL如何利用统计信息评估不同执行计划的成本,并最终选择最高效的一个。
作者:瀚高PG实验室 (Highgo PG Lab)
SQL是一种声明性语言,用户请求他们需要的东西而不需要明确告知计算机应该用什么方式得到相应的结果。这些工作是由DBMS(数据库管理系统)来完成的。DBMS将DML声明转化成为操纵所需记录集合的程序,它要确保返回正确的结果以及在理想情况下,速度越快越好。
这里的速度越快越好意味着:
1、将磁盘访问降到最低。
2、给与顺序读一个优先级(对于机械硬盘尤其重要)。
3、降低CPU操作数。
4、降低内存占用。
为了实现速度越快越好这个目标,DBMS中有一个优化器,它的作用是找出最好的执行方案。
PostgreSQL中的优化器是基于一种成本的机制来运作的。PostgreSQL会计算多个执行计划的成本,然后选取最低的那个来执行。
PostgreSQL估计计划成本的方式:基于统计信息估计计划中各个节点的成本。PostgreSQL会分析各个表来获取一个统计信息样本(这个操作通常是由autovacuum这个守护进程来完成的)。
统计信息
统计信息的其中一部分是每个表和索引中项的总数,以及每个表和索引占用的磁盘块数。这些信息保存在pg_class表的reltuples和relpages列中。我们可以这样查询相关信息:
SELECT relname, reltuples, relpages FROM pg_calss;基数
基数在集合理论中是指一个集合中元素的数量。在数据库中,基数返回一个数组中所有维度上元素数量的总和。这实际上是调用unnest会产生的行数。
我们举一个例子来说明:
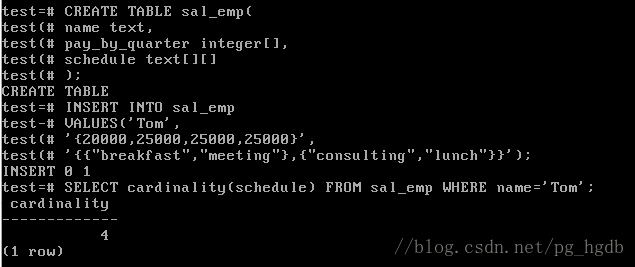
图1 基数
如图1所示,我们创建了表sal_emp,并向表中插入了一条记录,之后查询cardinality的值。
选择度
选择度是执行完预估之后返回的记录的部分。例如,一个people表中有四分之一是儿童,那么person = ‘child’ 的选择度就是0.25。所以如果我们知道people的总数,我们就可以根据这个选择度估计其中儿童的数目。这些估计值可以被EXPLAIN语句(用于展示执行计划)获取。


















 1230
1230

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









