




 本文介绍了Python中多线程编程的基本概念与实践技巧,包括线程的优势、状态管理、全局变量共享问题及解决办法等内容。
本文介绍了Python中多线程编程的基本概念与实践技巧,包括线程的优势、状态管理、全局变量共享问题及解决办法等内容。
python系统编程篇之线程
python多线程
多线程类似于同时执行多个不同程序,多线程运行有如下优点:
- 使用线程可以把占据长时间的程序中的任务放到后台去处理。
- 用户界面可以更加吸引人,这样比如用户点击了一个按钮去触发某些事件的处理,可以弹出一个进度条来显示处理的进度
- 程序的运行速度可能加快
- 在一些等待的任务实现上如用户输入、文件读写和网络收发数据等,线程就比较有用了。在这种情况下我们可以释放一些珍贵的资源如内存占用等等。
- 线程在执行过程中与进程还是有区别的。每个独立的线程有一个程序运行的入口、顺序执行序列和程序的出口。但是线程不能够独立执行,必须依存在应用程序中,由应用程序提供多个线程执行控制。
每个线程都有他自己的一组CPU寄存器,称为线程的上下文,该上下文反映了线程上次运行该线程的CPU寄存器的状态。
指令指针和堆栈指针寄存器是线程上下文中两个最重要的寄存器,线程总是在进程得到上下文中运行的,这些地址都用于标志拥有线程的进程地址空间中的内存。
- 线程可以被抢占(中断)。
在其他线程正在运行时,线程可以暂时搁置(也称为睡眠) – 这就是线程的退让。
threading模块
单线程执行
import time
def func():
print('这是一个方法!')
time.sleep(1)
if __name__ == '__main__':
start_time = time.time()
for i in range(5):
func()
end_time = time.time()
print('程序运行的时间为 %d s' % (end_time-start_time))运行结果:
这是一个方法!
这是一个方法!
这是一个方法!
这是一个方法!
这是一个方法!
程序运行的时间为 5 s
多线程执行
在上述的程序中稍作修改,使函数在多个线程中执行,再次观察运行时间
import threading
import time
def func():
print('这是一个方法!')
time.sleep(1)
if __name__ == '__main__':
start_time = time.time()
for i in range(5):
# func()
t1 = threading.Thread(target=func)
t1.start()
t1.join()
end_time = time.time()
print('程序运行的时间为 %0.2f s' % (end_time-start_time))运行结果:
这是一个方法!
这是一个方法!
这是一个方法!
这是一个方法!
这是一个方法!
程序运行的时间为 1.00 s
从程序运行结果可以看出,单线程运行结果是5秒,而使用了threading模块中的Thread方法之后,程序的运行时间变成了1秒。
线程状态
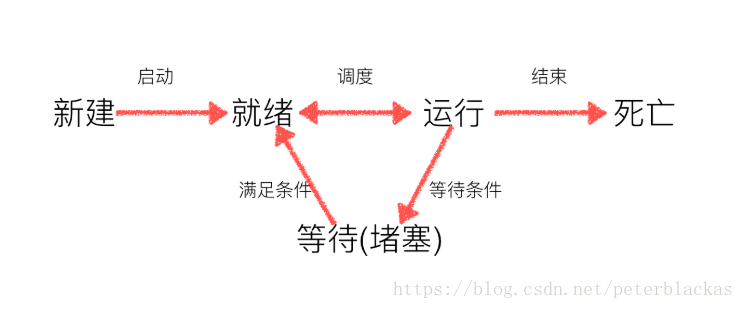
图中展示了线程的三种状态,
就绪状态:就绪状态表示该线程可以运行但没有运行,等待CPU调度的一个状态,即当CPU调度让该线程运行时,该线程可以立刻运行。
等待(阻塞)状态:等待(阻塞)状态表示该线程即使CPU调度该线程让其运行时,还线程也不会运行,需要满足一个条件,该线程才能从等待状态变为就绪状态。
运行状态:该线程在运行中。
共享全局变量问题
上一篇写到,进程之间是不共享全局变量的,那在线程之间,能否共享全局变量呢?
用实例来说明,
import threading
import time
g_list = [1,2,3,4]
def work1(num):
global g_list
g_list.append(num)
print('work1 the list is ',g_list)
def work2(num):
global g_list
g_list.append(num)
print('work2 the list is ',g_list)
if __name__ == '__main__':
for i in range(3):
t1 = threading.Thread(target=work1,args=(i*10,))
t2 = threading.Thread(target=work2,args=(i*100,))
t1.start()
t2.start()运行结果:
work1 the list is [1, 2, 3, 4, 0]
work2 the list is [1, 2, 3, 4, 0, 0]
work1 the list is [1, 2, 3, 4, 0, 0, 10]
work2 the list is [1, 2, 3, 4, 0, 0, 10, 100]
work1 the list is [1, 2, 3, 4, 0, 0, 10, 100, 20]
work2 the list is [1, 2, 3, 4, 0, 0, 10, 100, 20, 200]
g_list is [1, 2, 3, 4, 0, 0, 10, 100, 20, 200]
Process finished with exit code 0
通过程序运行的结果可以看到,线程之间是共享全局变量的
- 在一个进程内的所有线程共享全局变量,能够在不适用其他方式的前提下完成多线程之间的数据共享(这点要比多进程要好)
- 缺点就是,线程是对全局变量随意遂改可能造成多线程之间对全局变量的混乱(即线程非安全)
多线程开发中遇到的问题
假设两个线程t1和t2都要对num=0进行增1运算,t1和t2都各对num修改10次,num的最终的结果应该为20。
但是由于是多线程访问,有可能出现下面情况:
在num=0时,t1取得num=0。此时系统把t1调度为”sleeping”状态,把t2转换为”running”状态,t2也获得num=0。然后t2对得到的值进行加1并赋给num,使得num=1。然后系统又把t2调度为”sleeping”,把t1转为”running”。线程t1又把它之前得到的0加1后赋值给num。这样,明明t1和t2都完成了1次加1工作,但结果仍然是num=1。
from threading import Thread
import time
g_num = 0
def test1():
global g_num
for i in range(1000000):
g_num += 1
print("---test1---g_num=%d"%g_num)
def test2():
global g_num
for i in range(1000000):
g_num += 1
print("---test2---g_num=%d"%g_num)
p1 = Thread(target=test1)
p1.start()
# time.sleep(3) #取消屏蔽之后 再次运行程序,结果会不一样,,,为啥呢?
p2 = Thread(target=test2)
p2.start()
print("---g_num=%d---"%g_num)运行结果:
—g_num=135270—
—test1—g_num=1194664
—test2—g_num=1281067
每次运行结果会有不同,但一般都不是2000000。
问题产生的原因就是没有控制多个线程对同一资源的访问,对数据造成破坏,使得线程运行的结果不可预期。这种现象称为“线程不安全”。
解决问题的思路
对于提出的那个计算错误的问题,可以通过线程同步来进行解决思路,如下:
- 系统调用t1,然后获取到num的值为0,此时上一把锁,即不允许其他现在操作num
- 对num的值进行+1
- 解锁,此时num的值为1,其他的线程就可以使用num了,而且是num的值不是0而是1
- 同理其他线程在对num进行修改时,都要先上锁,处理完后再解锁,在上锁的整个过程中不允许其他线程访问,就保证了数据的正确性
互斥锁
当多个线程几乎同时修改某一个共享数据的时候,需要进行同步控制
线程同步能够保证多个线程安全访问竞争资源,最简单的同步机制是引入互斥锁。
互斥锁为资源引入一个状态:锁定/非锁定。
某个线程要更改共享数据时,先将其锁定,此时资源的状态为“锁定”,其他线程不能更改;直到该线程释放资源,将资源的状态变成“非锁定”,其他的线程才能再次锁定该资源。互斥锁保证了每次只有一个线程进行写入操作,从而保证了多线程情况下数据的正确性。
threading模块中定义了Lock类,可以方便的处理锁定:
#创建锁
mutex = threading.Lock()
#锁定
mutex.acquire([blocking])
#释放
mutex.release()其中,锁定方法acquire可以有一个blocking参数。
- 如果设定blocking为True,则当前线程会堵塞,直到获取到这个锁为止(如果没有指定,那么默认为True)
- 如果设定blocking为False,则当前线程不会堵塞
那么就可以利用互斥锁解决上述问题,
from threading import Thread, Lock
import time
g_num = 0
def test1():
global g_num
for i in range(1000000):
#True表示堵塞 即如果这个锁在上锁之前已经被上锁了,那么这个线程会在这里一直等待到解锁为止
#False表示非堵塞,即不管本次调用能够成功上锁,都不会卡在这,而是继续执行下面的代码
mutexFlag = mutex.acquire(True)
if mutexFlag:
g_num += 1
mutex.release()
print("---test1---g_num=%d"%g_num)
def test2():
global g_num
for i in range(1000000):
mutexFlag = mutex.acquire(True) #True表示堵塞
if mutexFlag:
g_num += 1
mutex.release()
print("---test2---g_num=%d"%g_num)
#创建一个互斥锁
#这个所默认是未上锁的状态
mutex = Lock()
p1 = Thread(target=test1)
p1.start()
p2 = Thread(target=test2)
p2.start()
print("---g_num=%d---"%g_num)运行结果:
—test2—g_num=1994194
—test1—g_num=2000000
—g_num=2000000—
上锁解锁过程
当一个线程调用锁的acquire()方法获得锁时,锁就进入“locked”状态。
每次只有一个线程可以获得锁。如果此时另一个线程试图获得这个锁,该线程就会变为“blocked”状态,称为“阻塞”,直到拥有锁的线程调用锁的release()方法释放锁之后,锁进入“unlocked”状态。
线程调度程序从处于同步阻塞状态的线程中选择一个来获得锁,并使得该线程进入运行(running)状态。
锁的好处:
- 确保了某段关键代码只能由一个线程从头到尾完整地执行
锁的坏处:
- 阻止了多线程并发执行,包含锁的某段代码实际上只能以单线程模式执行,效率就大大地下降了
- 由于可以存在多个锁,不同的线程持有不同的锁,并试图获取对方持有的锁时,可能会造成死锁

















 421
421

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









