



 本文探讨了服务器并发量低的原因,重点分析了MySQL数据库调用的效率问题。内存、磁盘响应速度和表文件大小是影响并发量的主要因素。通过添加索引、底层数据拆分策略以及优化调用效率,可以有效提升MySQL的并发处理能力。虽然MySQL并发效率较低,但由于其在关联计算上的优势,使其在关系型数据库中仍占有重要地位。
本文探讨了服务器并发量低的原因,重点分析了MySQL数据库调用的效率问题。内存、磁盘响应速度和表文件大小是影响并发量的主要因素。通过添加索引、底层数据拆分策略以及优化调用效率,可以有效提升MySQL的并发处理能力。虽然MySQL并发效率较低,但由于其在关联计算上的优势,使其在关系型数据库中仍占有重要地位。
一般服务器的并发量:
并发量指的是每秒同时处理的线程
通常都比较低,在几百左右
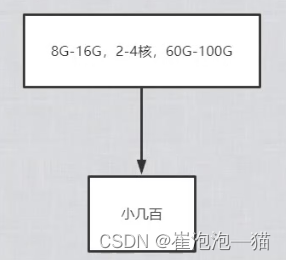
为什么并发量这么低?
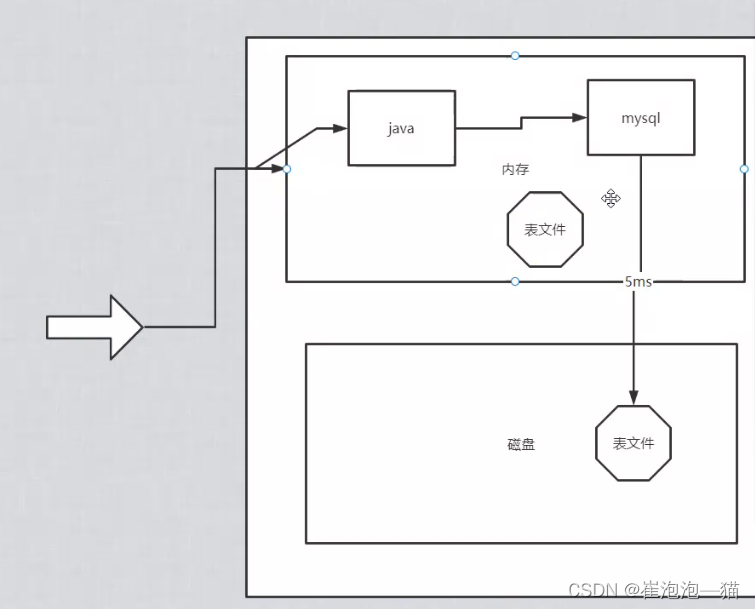
一个项目的内存:
在数据库里面,一个表在磁盘中是按文件存储的,在公司里面使用的磁盘都是机械硬盘,响应的时间较慢
时间开销:
mysql读取文件时要先将表文件加载到内存中,假设该表大小是500M,数据库单次访问表文件消耗时间是5ms,由于要多次调用,那么调用表文件的消耗的时间可能是几十ms,因此并发量不高主要是消耗在mysql调用上面
每秒并发量计算:
并发量计算要计算两个参数,一个是线程空间消耗,一个是线程存活时间
假设一个线程平均消耗内存大小为200M,存活时间为50ms,可供使用的内存大小为4G,那么每次可以调用4G/200M=20个线程,1秒可以调用1s/50ms=20次,那么1秒可以调用20*20=400个线程,并发量也就是400
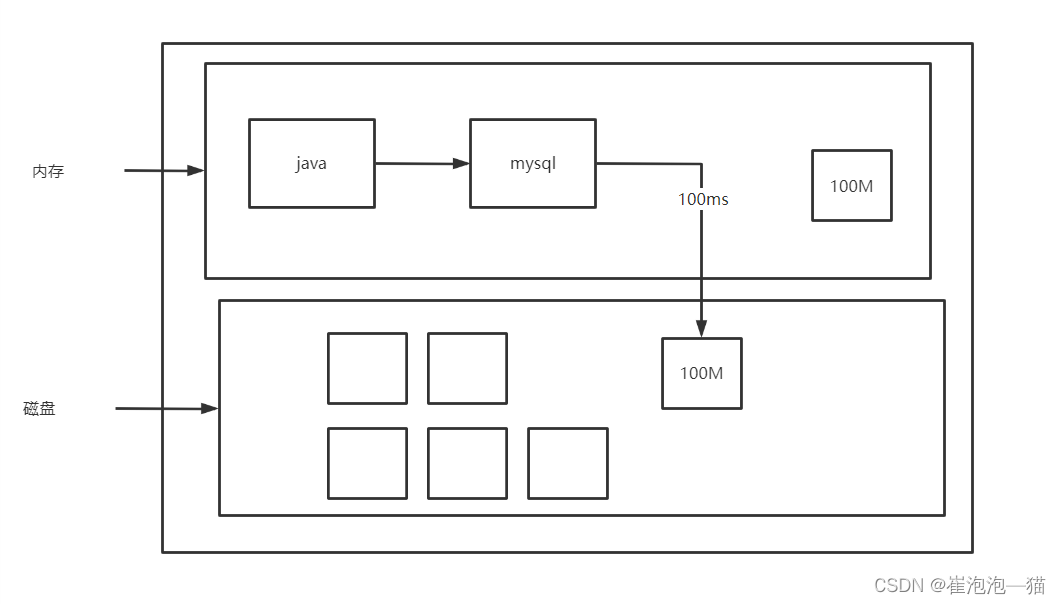
限制瓶颈:
在数据库中可能一个表文件的大小达到几个G的大小,随之mysql调用表文件的时间也会变慢,因此并发量主要的限制瓶颈就是mysql数据库调用问题
如果只调用java没有对硬盘操作:

如果排除数据库,单纯只调用java代码和服务器那么调用速度是非常快的
在服务器选择中,除了Tomcat,nigix也可以当做服务器使用,由于是根据c语言写的,处理速度非常快,可以达到数十万每秒,但是nigix不能运行除c以外的程序,因此使用率不高
提高mysql调用效率
正常来说调用一个大小为100M的表消耗的内存为100M
添加索引:
假设我们是用一个大小为10M的索引,每个表文件在索引中占用20k,那么一次调用只消耗10M+20k的内存消耗
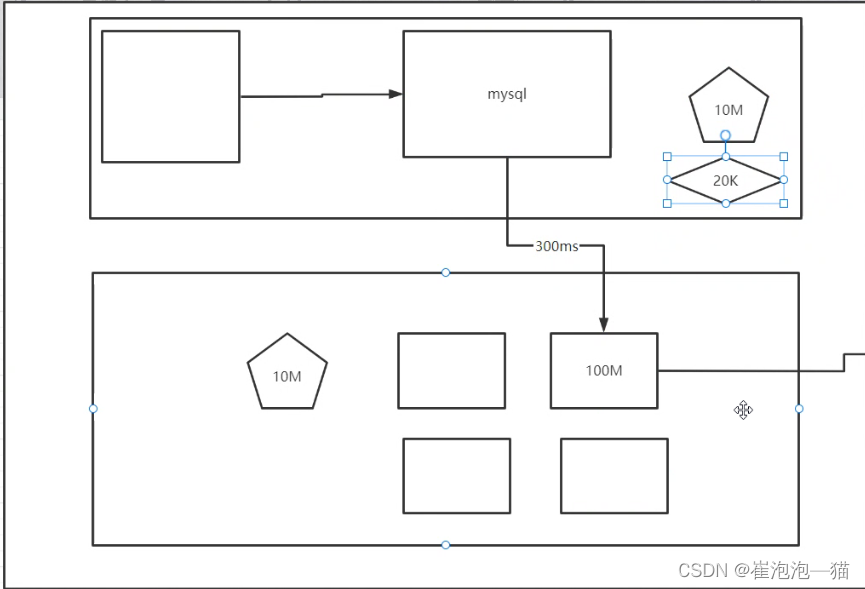
底层拆分策略:
假设我们将一个表划分为一个个大小为10k的小模块,当我们查找需要的数据时,通过算法查找到数据所在的模块中,那么我们每次损耗的内存大小仅为模块的大小
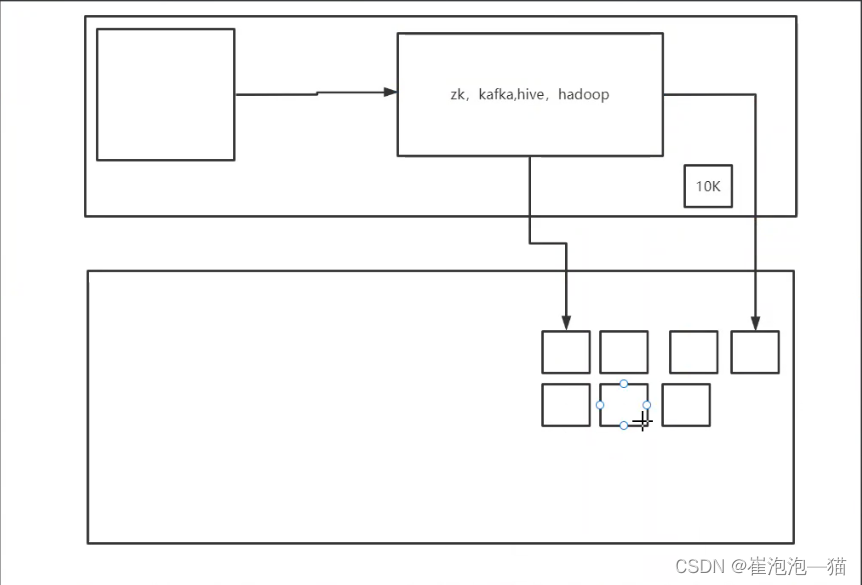
mysql效率这么低为什么不舍弃:
数据库分为关系型和非关系型,区别在于是否擅长关联计算,如sum,avg,max,min等操作,mysql数据库因为数据都在一个表里,因此关联计算非常方便,所有mysql数据库都擅长关联计算,非关系型是单点计算,mysql数据库之所以不被淘汰是因为擅长关联计算。

















 5958
5958

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









