









对之前一节部分进行实践,使用keras进行实现,keras关于循环神经网络有多个方法。https://keras.io/zh/layers/recurrent/
- SimpleRNN
- LSTM+CNN
样本
使用ai挑战赛用户评论信息,这里仅用验证集的数据(数据量少一些,运行快一些)
标签取了用户消费后感受字段。该字段标签有1'正面情感', 0'中性情感', -1'负面情感', -2'情感倾向未提及'
| 评论内容 | 标签 |
|---|---|
| 趁着国庆节,一家人在白天在山里玩耍之后,晚上决定吃李记搅团。 | 1 |
模型
1.导入库
import pandas as pd
import numpy as np
import json
import os
from keras.preprocessing.text import Tokenizer
from keras.preprocessing import sequence
from keras.models import Sequential
from keras.layers.embeddings import Embedding
from keras.layers import Dropout, Conv1D, MaxPooling1D, LSTM, Dense, Bidirectional, SimpleRNN
from keras.utils import to_categorical
2.数据预处理
Tokenizer生成字典如下(截取部分):
{",": 1, "的": 2, "。": 3, "是": 4, "不": 5, " ": 6, "了": 7, "一": 8, "有": 9, "很": 10, "吃": 11, "\n": 12, "好": 13, "点": 14, "还": 15, "个": 16, "味": 17, "菜": 18, "就": 19, "来": 20, "我": 21, "这": 22, "也": 23, "\"": 24, "人": 25, "!": 26, "大": 27, "上": 28, "家": 29, "都": 30, "道": 31, "面": 32, "多": 33, "以": 34, "在": 35, "肉": 36, "店": 37, "没": 38, "可": 39, "感": 40, "小": 41, "到": 42, "里": 43, "觉": 44, "口": 45, "错": 46, "过": 47, "去": 48, "说": 49, "服": 50, "和": 51, "比": 52, "下": 53, "务": 54, "要": 55, "后": 56, "得": 57, "餐": 58, "子": 59, "们": 60, "鱼": 61, "会": 62, "次": 63, "时": 64}
处理主体部分。
data = pd.read_csv('data/sample.csv')
contents = data['content']
#取一列"本次消费感受"作为标签数据 2'正面情感', 1'中性情感', -1'负面情感', 0'情感倾向未提及'
labels = data['others_overall_experience']
#文字用数字表示
tokenizer = Tokenizer(filters='\t\n', char_level=True)
tokenizer.fit_on_texts(contents)
word_dict_file = 'build/dictionary.json'
#保存字典 在预测时为了使用相同的映射这里需要保存字典 预测时候直接使用该字典进行文字转数字
if not os.path.exists(os.path.dirname(word_dict_file)):
os.makedirs(os.path.dirname(word_dict_file))
with open(word_dict_file, 'w',encoding='utf-8') as outfile:
json.dump(tokenizer.word_index, outfile, ensure_ascii=False)
num_words = len(tokenizer.word_index)+1
#将文字使用字典转成数字
contents_tokenizer = tokenizer.texts_to_sequences(contents)
#将文本填充到相同的长度
x_processed = sequence.pad_sequences(contents_tokenizer, maxlen=512, value=0)
train_size = int(data.shape[0] * .75)
x_train, x_test = x_processed[:train_size], x_processed[train_size:]
labels = labels+2 #将-1 0 这样标签转成正数 输出再减掉即可
labels = to_categorical(labels)
y_train, y_test = labels[:train_size], labels[train_size:]
3.模型
- 使用双向RNN
- Embedding词嵌入层 将词向量映射到维度更低且能有词与词之间关系。
- Bidirectional(SimpleRNN(units=512)) 双向RNN
- Dropout 训练中每次更新输入单元的按比率随机设置为0 防止过拟合
- Dense 全连接层 输出4个标签的概率
- LSTM 长短期记忆网络
- Conv1D一维卷积 MaxPooling1D 一维池化
- categorical_crossentropy 多分类损失函数 二分类使用binary_crossentropy 优化器adam
3.1 双向RNN
model1 = Sequential()
model1.add(Embedding(num_words, 32, input_length=512))
model1.add(Dropout(0.2))
model1.add(Bidirectional(SimpleRNN(units=512)))
model1.add(Dropout(0.2))
model1.add(Dense(4, activation='sigmoid'))
model1.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
print(model1.summary())
model1.fit(x_train, y_train, validation_split=0.25, epochs=20, batch_size=512)
网络结构:
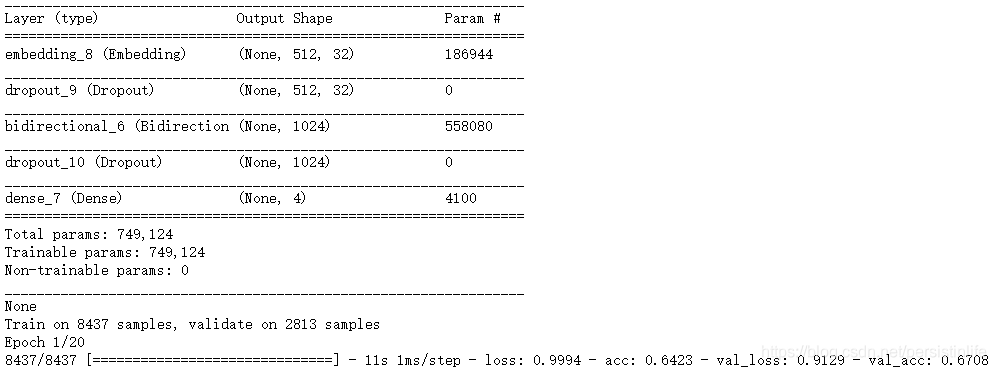
预测结果:
score, acc = model.evaluate(x_test, y_test, verbose=1, batch_size=1024)
print("Model Accuracy: {:0.2f}%".format(acc * 100))
# 66.16%
3.2 LSTM
model2 = Sequential()
model2.add(Embedding(num_words, 32, input_length=512))
model2.add(Dropout(0.2))
model2.add(LSTM(64, recurrent_dropout=0.5))
model2.add(Dropout(0.2))
model2.add(Dense(4, activation='sigmoid'))
model2.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
print(model2.summary())
model2.fit(x_train, y_train, validation_split=0.25, epochs=20, batch_size=512)
网络结构:

预测结果:
score, acc = model2.evaluate(x_test, y_test, verbose=1, batch_size=1024)
print("Model Accuracy: {:0.2f}%".format(acc * 100))
# 68.67%
3.3 LSTM+ CNN
model3 = Sequential()
model3.add(Embedding(num_words, 32, input_length=512))
model3.add(Dropout(0.2))
model3.add(Conv1D(64, 5, activation='relu'))
model3.add(MaxPooling1D(pool_size=4))
model3.add(LSTM(64, recurrent_dropout=0.2))
model3.add(Dropout(0.2))
model3.add(Dense(4, activation='sigmoid'))
model3.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
print(model3.summary())
model3.fit(x_train, y_train, validation_split=0.25, epochs=20, batch_size=512)
网络结构:

预测结果:
score, acc = model3.evaluate(x_test, y_test, verbose=1, batch_size=1024)
print("Model Accuracy: {:0.2f}%".format(acc * 100))
# 74.21%
3.4 小结一下
-
从LSTM和RNN对比看,LSTM的对序列模型学习能力更强(当然这里也涉及到参数调优。是有优化点)
-
在序列模型中加入卷积操作能加快网络训练时间
模型调优是个有趣的过程,其他模型调试中~


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









