1 、资源调度与任务调度
资源调度过程
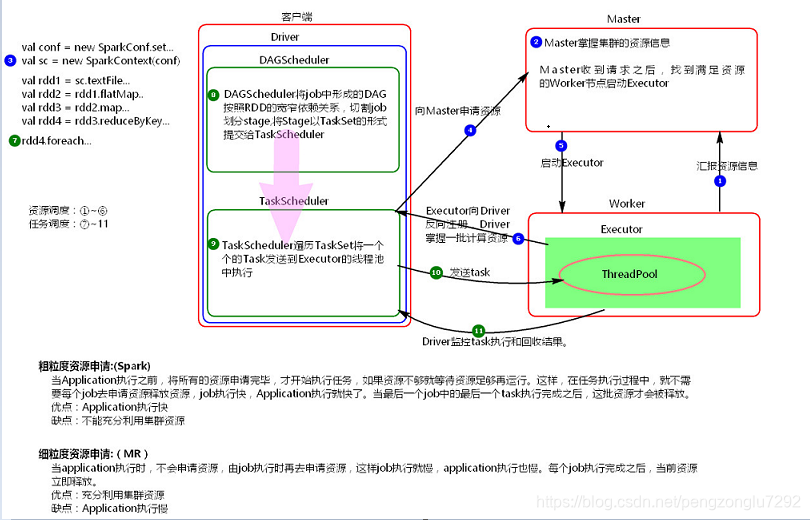
资源调度:
1、new SparkContext时在启动driver。
2、driver/AM启动成功则向主节点申请资源。
3、主节点接收到请求返回给driver/AM一批节点信息。
4、driver/AM接收到回应则到对应的从节点启动executor。
5、executor成功启动则向driver注册自己。
注:
spark:
粗粒度资源申请,一次性将当前应用程序所有job的资源全部申请过来
等该应用程序所有job全部结束再释放资源。
特点:
避免了资源的反复申请,但降低了资源的利用率。效率高
MR:
细粒度资源申请,一个task申请一次资源,task结束释放资源。
特点:
资源反复申请,资源利用率高。效率低。
补充:
1、默认每个节点志气一个executor,该executor会申请当前节点的所有core和1G内存,如果当前节点运行driver,则留一个core给driver。
2、如果想在当前节点启动多个executor,请设置--executor-cores。但当前节点的所有executor依然会占用当前节点所有的core。
3、如果不想executor占用当前节点的所有core,则可以指定应用程序的--total-executor-cores。
4、设置了启动多个executor后,executor的数量也回受--executor-memory的限制。
5、同一个应用程序的executor是在集群中分散启动的。
任务调度过程
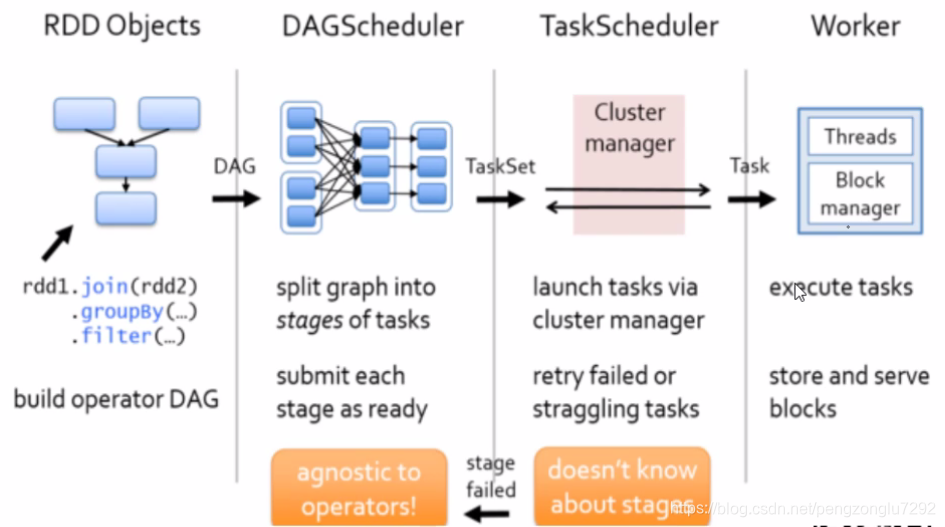
任务调度:
1、一个action算子触发一个job形成一个DAG有向无环图,DAG图会提交给DAGScheduler处理。
2、DAGScheduler接收到DAG图会根据rdd依赖关系划分stage,然后将每个stage以TaskSet的形式提
交给TaskScheduler处理。
3、TaskScheduler接收到TaskSet则会将内部的task发送到executor的线程池中执行。
分析:
task在线程池中执行失败,步骤3重试两次,都失败,2重试,再3,3失败三次,再2。。。
步骤2累计会执行4次。每次执行步骤2会累积执行3次步骤3。
所以一个task失败,其实该task已经执行了12次了。
如果一个task失败,则当前stage失败,stage失败,当前job失败,job失败,当前应用程序失败。
所以一个task失败,一个应用程序失败。
但对于成功执行的task,如果数据写入了数据库,数据库就真的有数据了。
推测式执行:
TaskScheduler还有一个功能,就是启动推测式执行。
如果某一个task执行缓慢,在一些低负载机器启动几个task,哪边先执行完则采用哪边的结果。
2、广播变量与累加器
1、共享变量
一般情况下,Spark的每个task实际上操作的是变量的一个独立副本数据。
比如在代码中定义了一个list,list定义的代码实际上在driver端执行,通过算子操作list是在
executor端执行,executor端每一个task都会有一份list的相关数据。
共享变量可以让每一个executor中只保留一份list的数据。
Spark提供了两种有限的共享变量:广播变量(broadcast variable)和累加器(accumulator)。
driver端执行:
配置信息、类中变量声明定义及操作、类中的输出
executor端执行:
rdd的操作逻辑
2、广播变量
特点:
只读,广播变量的值executor端不可更改
不能广播rdd,可以广播rdd的结果
只能在driver端定义,在executor端使用
示例:
scala> val a = sc.broadcast(Array(1, 2, 3))
a: org.apache.spark.broadcast.Broadcast[Array[Int]] = Broadcast(0)
scala> a.value
res0: Array[Int] = Array(1, 2, 3)
3、累加器
相当于分布式中的全局变量
特点:
只能在driver端定义,在driver和executor使用均可
累加器不仅可以累加数值,还可以累加对象等(自定义累加器)
示例:
scala>val acc=sc.double.LongAccumulator("acc") #定义
scala>acc.add(1) #累加,也可以在driver端定义初始值
scala>acc.value #获取累加值
4、自定义累加器








 本文介绍了Spark中的资源调度与任务调度流程,包括资源调度的特点及其与MapReduce的区别,并详细解析了任务调度的具体步骤。此外,还探讨了Spark中的广播变量与累加器,包括它们的特点和使用场景。
本文介绍了Spark中的资源调度与任务调度流程,包括资源调度的特点及其与MapReduce的区别,并详细解析了任务调度的具体步骤。此外,还探讨了Spark中的广播变量与累加器,包括它们的特点和使用场景。


















 2741
2741

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











