




 本文详细探讨了HDFS的架构设计,包括HDFS的三个核心进程:NameNode、DataNode和SecondaryNameNode。分析了block的大小和副本数,重点阐述了NameNode的功能,如目录结构、fsimage和edits log的管理,以及DataNode的角色,它如何存储数据块并定期向NameNode报告。同时,还介绍了SecondaryNameNode的作用和HDFS的权限系统。
本文详细探讨了HDFS的架构设计,包括HDFS的三个核心进程:NameNode、DataNode和SecondaryNameNode。分析了block的大小和副本数,重点阐述了NameNode的功能,如目录结构、fsimage和edits log的管理,以及DataNode的角色,它如何存储数据块并定期向NameNode报告。同时,还介绍了SecondaryNameNode的作用和HDFS的权限系统。
HDFS架构设计
1、HDFS的三个进程
NameNode:接受客户端请求、管理hdfs、维护文件元信息和操作日志
DataNode:存储数据块和数据块校验和、通过水平复制使文件冗余度满足要求
SecondaryNameNode:对文件元信息(fsimage文件)和操作日志(edits文件)进行合并
2、block大小和副本数
blocksize:
hadoop 1.x blocksize=64MB
hadoop 2.x blocksize=128MB
属性:hdfs-site.xml中的dfs.blocksize
副本数:
hadoop 1.x 3
hadoop 2.x 3
hadoop 3.x 1.5
属性:hdfs-site.xml中的dfs.replication
3、NameNode详解
A、目录结构

B、dfs.namenode.name.dir属性
所属配置文件:
hdfs-site.xml
解释:
该属性确定存放元数据的目录,存放元数据的目录下有fsimage、edits log、VERSION、in_use.lock等诸多文件或目录。
该属性可以指定多个路径,以逗号分隔。一旦一个路径对应的磁盘故障,多个路径可保证HDFS仍能找到文件的元数据,从而避免系统故障。
C、NameNode
NameNode:存储文件的命名空间,比如
a.文件对应哪些block,这些block位于哪些节点上
b.文件名称、文件属性、目录结构等
a存储在内存中,由DataNode在向NameNode注册时发生,或通过心跳机制周期性发送
b持久化在fsimage文件中
D、fsimage文件和edits log文件
fsimage:
记录文件元信息
路径:${HADOOP_HOME}/tmp/dfs/name/current/fsimage******
每一个fsimage文件就有一个.md5文件与之对应,该.md5文件记录文件的校验和
edits log:
记录操作日志,记录文件的写操作,包括创建、移动、追加文件
edits log文件表征了文件系统的最新状态
fsimage和edits log合并:
发生检查点的时候,合并前切换新的edits log文件,切换时更新seen_txid的值
检查点:
60分钟
hdfs-site.xml中dfs.namenode.checkpoint.period属性确定
当edits log中记录的事务操作一百万条时
hdfs-site.xml中dfs.namenode.checkpoint.txns属性确定
事务检查:
检查edits log文件中的事务条数的时间间隔,默认一分钟
hdfs-site.xml中dfs.namenode.checkpoint.check.period属性确定
E、in_use.lock
作用:
表明该current目录已经被占用,停止数据节点,则该文件消失。
通过in_use.lock文件,数据节点可以保证独自占用current目录,防止两个数据节点同时操作一个current
目录,从而发生混乱。
注意:
在某些情况下,hdfs异常关闭,上一个数据节点产生的in_use.lock文件依旧存在,造成下一次数据节点无
法访问元数据,或者是集群报错甚至无法启动。此时只需要将该文件删除即可。
F、VERSION目录
说明:
是一个java的属性文件,包含了HDFS的版本信息。
属性:
namespaceID:是该文件系统的唯一标志符,当NameNode第一次格式化的时候生成。
clusterID:是HDFS集群使用的一个唯一标志符,集群有多个命名空间,不同的命名空间由不同的NameNode
管理。
blockpoolID:是block池的唯一标志符,一个NameNode管理一个命名空间,该命名空间中的所有文件存储的
block都在block池中。
cTime:标记着当前NameNode创建的时间。对于刚格式化的存储,该值永远是0,但是当文件系统更新的时
候,这个值就会更新为一个时间戳。
storageType:表示当前目录存储NameNode内容的数据结构。
4、DataNode详解
A.目录结构
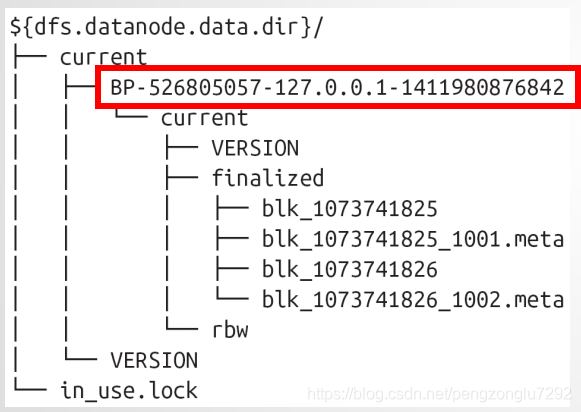
DataNode:存储数据块和数据块校验和、与NameNode通信(3秒发送一次心跳,30秒发送一次block信息)
B、dfs.datanode.data.dir
作用:
设置datanode节点存储数据块文件的本地路径,通常可以设置多个,用逗号隔开。
C、DataNode
作用:
存储数据、存储数据的校验和、进行block块的水平复制、向NameNode发送心跳。
注意:
1、HDFS块数据存储在以.blk为前缀的文件中,每个block块文件都有一个.meta为后缀的元数据文件相关
联,该.meta文件存储着block块数据的校验和。
2、每个block都有一个block池,每个block池对应于一个目录,该目录名称即为block块的id,如目录结构
中的BP-526805057.*。
3、每个block池中默认的block块有64个(由于很多操作系统对目录下文件个数有限制),由hdfs-
site.xml文件中的dfs.datanode.numblocks确定。
D、存储数据的模型
1、文件线性切割(线性即大小平均),单一的文件的block大小可以指定。
2、副本依据副本存放策略存放,副本数可以设置,对应于hdfs-site.xml文件中的dfs.replication属性。副本
要承担计算任务。
3、文件上传时可以手动指定上传的文件的block大小和副本数,已上传的文件只能调整副本数,无法更改block大
小。
4、只支持一次写入,多次读取,但可以追加数据。同一个时刻,只有一个节点操作一份数据。
补充副本存放策略:
第一个副本:如果是集群内上传,则存放在上传的DataNode节点,如果是集群外上传,则随机找一个磁盘不
太慢,cpu压力不太大的节点存放。
第二个副本:与副本1不同的机架。(处于安全考虑)
第三个副本:与副本2相同的机架。(处于网络考虑)
如果有更多的副本,则后续的副本随机存放。
每一个机架一般ip网段不同。
E、心跳机制
心跳机制:
3秒钟:
DataNode向NameNode发送一次心跳的时间间隔。
由hdfs-dfs.xml中的dfs.heartbeat.interval属性确定。
每十次心跳,即30秒向DataNode发送一次block信息。
5分钟:
NameNode向DataNode发起一次检查的时间间隔。
由hdfs-dfs.xml中的dfs.heartbeat.recheck-interval属性确定。
10分30秒:
NameNode判定DataNode死亡的时间
该时间=2*dfs.heartbeat.recheck-interval+10*dfs.heartbeat.interval
当DataNode被判定为死亡,则NameNode立刻会发起死亡节点的数据复制,将数据复制到活着的节点
上。
注意:
Hadoop的心跳机制包括yarn的心跳机制和hdfs的心跳机制。两者类似,但并不完全相同。
yarn的心跳机制在之后的yarn的体系架构中将会详细介绍。
5、SecondaryNameNode
A、示意图
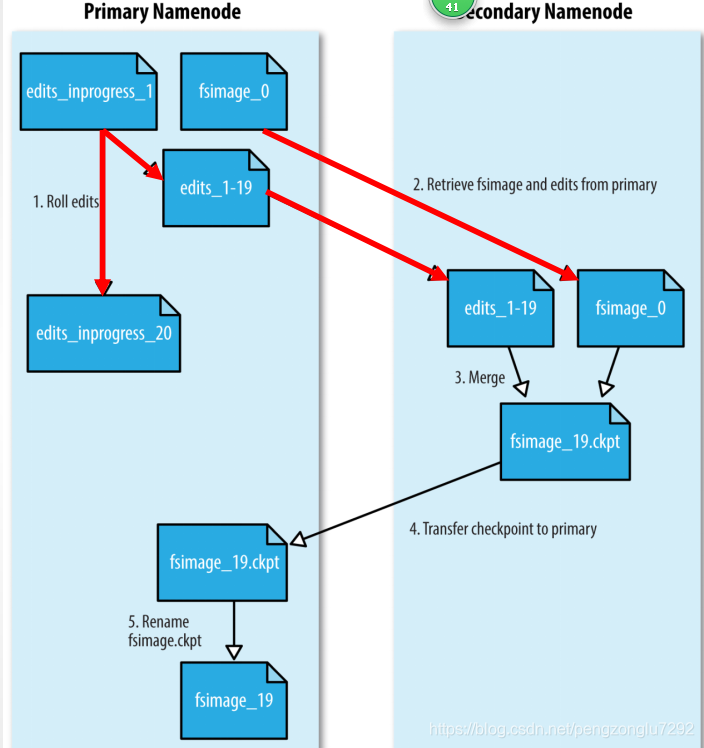
B、流程剖析
1、secondarynamenode请求namenode生成新的edits log文件并向其中写日志。NameNode会在所有的存储目录
中更新seen_txid文件
2、SecondaryNameNode通过HTTP GET的方式从NameNode下载fsimage和edits文件到本地。
3、SecondaryNameNode将fsimage加载到自己的内存,并根据edits log更新内存中的fsimage信息,然后将更
新完毕之后的fsimage写到磁盘上。
4、SecondaryNameNode通过HTTP PUT将新的fsimage文件发送到NameNode,NameNode将该文件保存为.ckpt的
临时文件备用。
5、NameNode重命名该临时文件并准备使用。此时NameNode拥有一个新的fsimage文件和一个新的很小的
edits.log文件(可能不是空的,因为在SecondaryNameNode合并期间可能对元数据进行了读写操作)。
注意:
1、管理员也可以将NameNode置于safemode,通过hdfs dfsadmin -saveNamespace命令来进行edits log
和fsimage的合并。
2、SecondaryNameNode要和NameNode拥有相同的内存。
3、对大的集群,SecondaryNameNode运行于一台专用的物理主机。
6、HDFS的权限
1、每个文件/目录都有一个属主和属组,权限对于属主和属组及其他人都是独立的,这一点和Linux是一样的。
2、对于一个文件,r表示读取的权限,w表示写或者追加的权限。对于目录而言,r表示列出目录内容的权限,w表
示创建或者删除文件和目录的权限,x表示访问该目录子项目的权限。
3、默认情况下hadoop运行时安全措施处于停用模式(对应于hdfs-site.xml中的dfs.permissions.enabled属
性)。一个客户端可以在远程系统上通过创建和任意一个合法用户同名的账号来进行访问。即:你说你是谁,hdfs
就认为你是谁。
4、超级用户是namenode进程的标识。对于超级用户,系统不会执行任何权限检查。
7、jps进程查看命令详解
1、执行jps进程若显示进程不可用,则可以通过ps -ef|grep pid 查看不可用进程的所属用户,在执行su - 用
户名 切换到所属用户执行jps命令,即可查看不可用进程的详细信息。
2、由于某种原因某进程突然被杀死,执行jps命令时该进程依然存在,此时我们只需要进入
~/tmp/hsperdata_hadoop(hadoop为用户名)目录下,删除对应的进程文件即可。



















 495
495

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











