




Deep Learning with Pytorch 中文简明笔记 第六章 Using a neural network to fit the data
Pytorch作为深度学习框架的后起之秀,凭借其简单的API和简洁的文档,收到了越来越多人的关注和喜爱。本文主要总结了 Deep Learning with Pytorch 一书第六章[Using a neural network to fit the data]的主要内容,并加以简单明了的解释,作为自己的学习记录,也供大家学习和参考。
文章目录
主要内容
- 非线性激活函数
- 使用Pytorch的nn模型
- 使用神经网络解决线性拟合问题
1. 人工神经单元
复杂函数的最基本的单元是神经单元
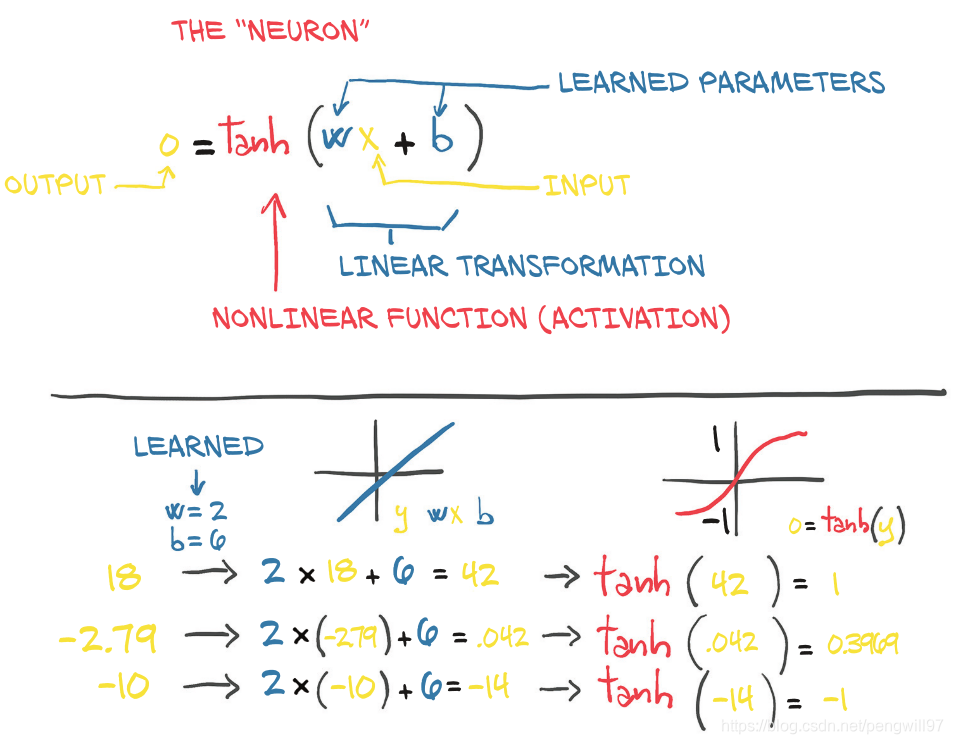
复杂函数就是多个神经单元的连接,最后展现出的形式就是函数的多层嵌套
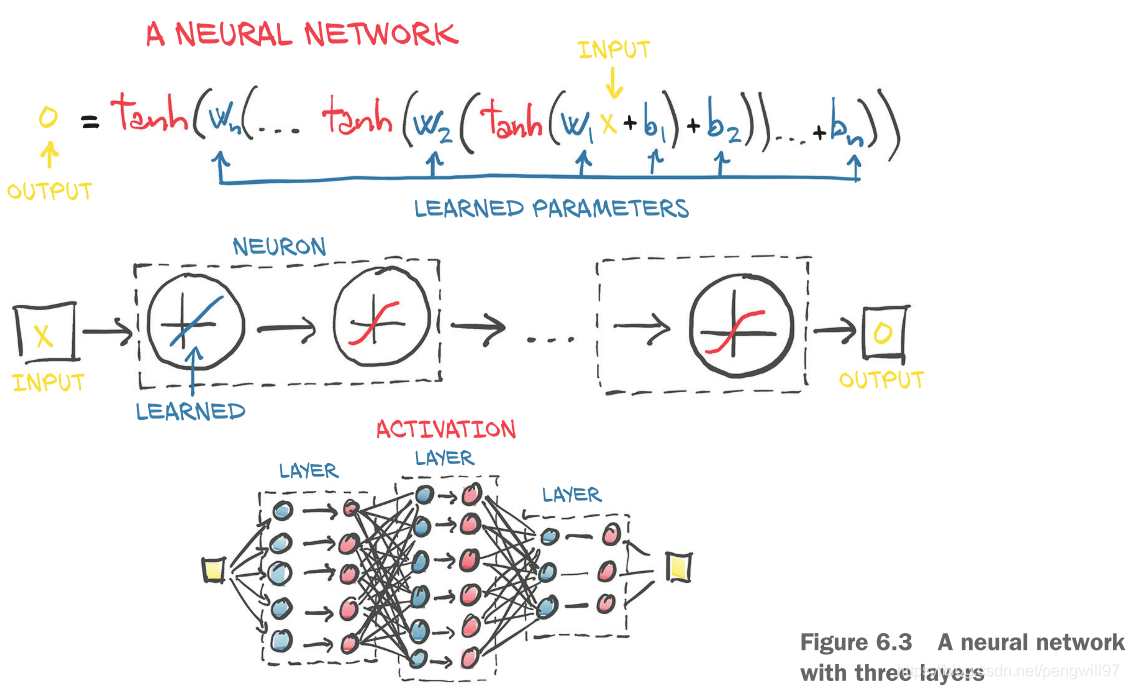
深度学习中最简单的单元是线性操作+非线性激活函数,非线性激活函数的主要作用为
- 在模型内部,它允许输出函数在不同的值处具有不同的斜率
- 在模型最后,它具有将先前线性运算的输出集中到给定范围的作用
激活函数的类型很多,如
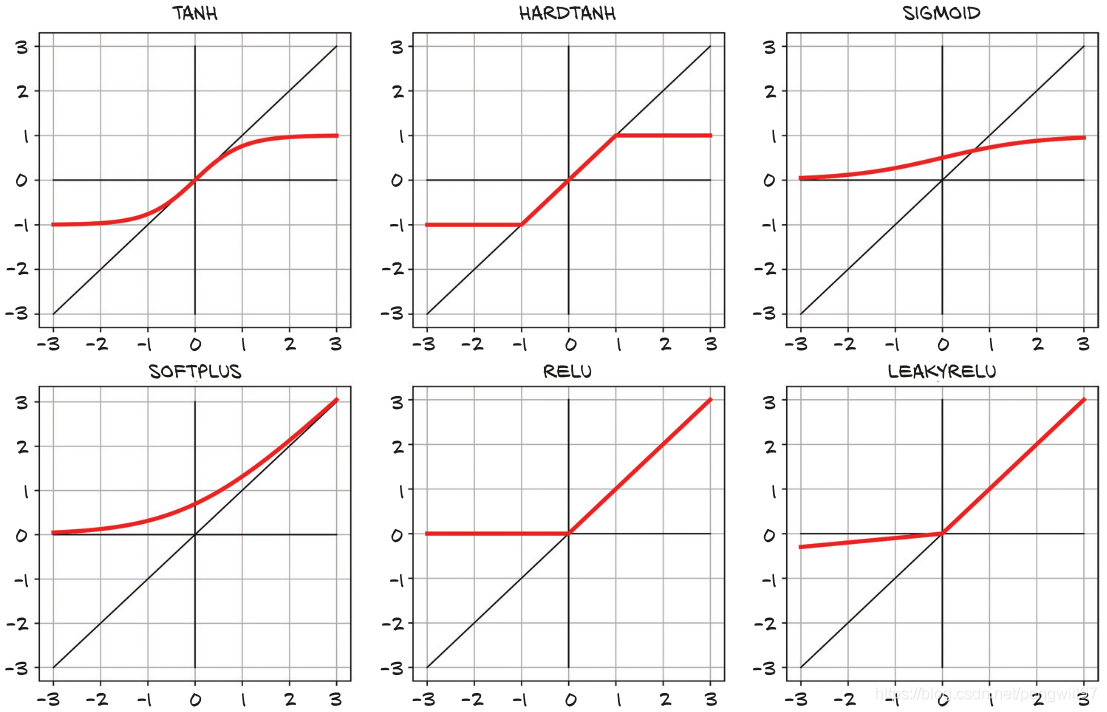
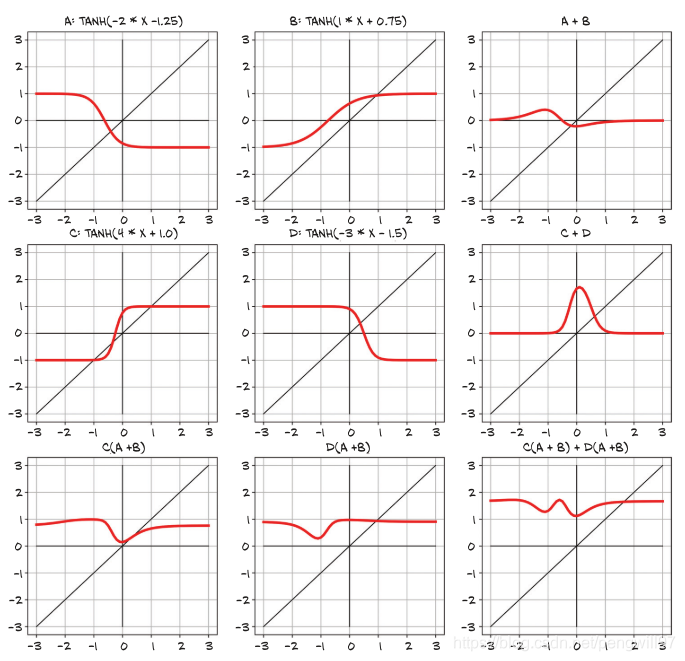
一般而言,激活函数是非线性且可微分的。并且激活函数有一段敏感区间,在这段区间中函数值的变化较为剧烈,同样也有一段不敏感区间,这段区间中函数值的变换较为缓和甚至几乎没有变化。
而对于参数学习而言,可以理解为调整非线性激活函数的offset和scale,使得更好的拟合数据。
2. Pytorch的nn模块
PyTorch具有专用于神经网络的子模块,叫做torch.nn模块。它包括了构建神经网络所需要的各种基本块。当模型需要一个列表或者一个字典组成的子模型时,PyTorch提供了nn.ModuleList和nn.ModuleDict。
PyToch对其子类nn.Module定义好了__call__()方法,使得其可以作为实例而调用。
# In[5]:
import torch.nn as nn
linear_model = nn.Linear(1, 1)
linear_model(t_un_val)
# Out[5]:
tensor([[0.6018], [0.2877]], grad_fn=<AddmmBackward>)
当对模型传入参数(数据)时,会调用模型的forward(),并且向其传入相同的参数。因此,不需要手动调用forward()函数。
y = model(x) # 正确
y = model.forward(x) # 错误
刚才使用到的线性模型nn.Linear,接受三个参数,分别为输入特征大小,输出特征大小和是否包含偏置项(默认为True)。我们可以使用weight和bias这两个属性来查看模型的参数详情。
# In[6]:
linear_model.weight
# Out[6]:
Parameter containing:
tensor([[-0.0674]], requires_grad=True)
# In[7]:
linear_model.bias
# Out[7]:
Parameter containing: tensor([0.7488], requires_grad=True)
按照刚才的方法传入参数,可以得到经过网络的结果。
# In[8]:
x = torch.ones(1) linear_model(x)
# Out[8]:
tensor( 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









